







BitCask:基于日志结构哈希表的高性能 KV 引擎
简介
BitCask 是分布式数据库 RIAK KV 的存储引擎,同时也是世界上最高效的 KV 存储引擎之一,其基于日志结构哈希表(Log-Structured Hash Table)实现。

GitHub 项目:https://github.com/basho/bitcask
存储模型
磁盘结构
如下图,对于 Bitcask 而言,它的一个实例其实就是 OS 上的一个目录,这个目录在同一时刻仅允许单进程访问。在这个目录下,又有着许多的文件,其中包含一个活跃文件和多个旧文件。
这里采用了类似仅追加(append only)的设计理念 ,当我们要写入数据时,会将数据写入到活跃文件中,而一旦活跃文件的容量达到一定的阈值时,它就会转变成旧文件,不再进行写入。作为替代,此时会创建一个新的文件来成为活跃文件。
这种 append only 的写入模式极大的利用了顺序 I/O,不需要进行的多余的磁盘寻道,大大的节约了时间。
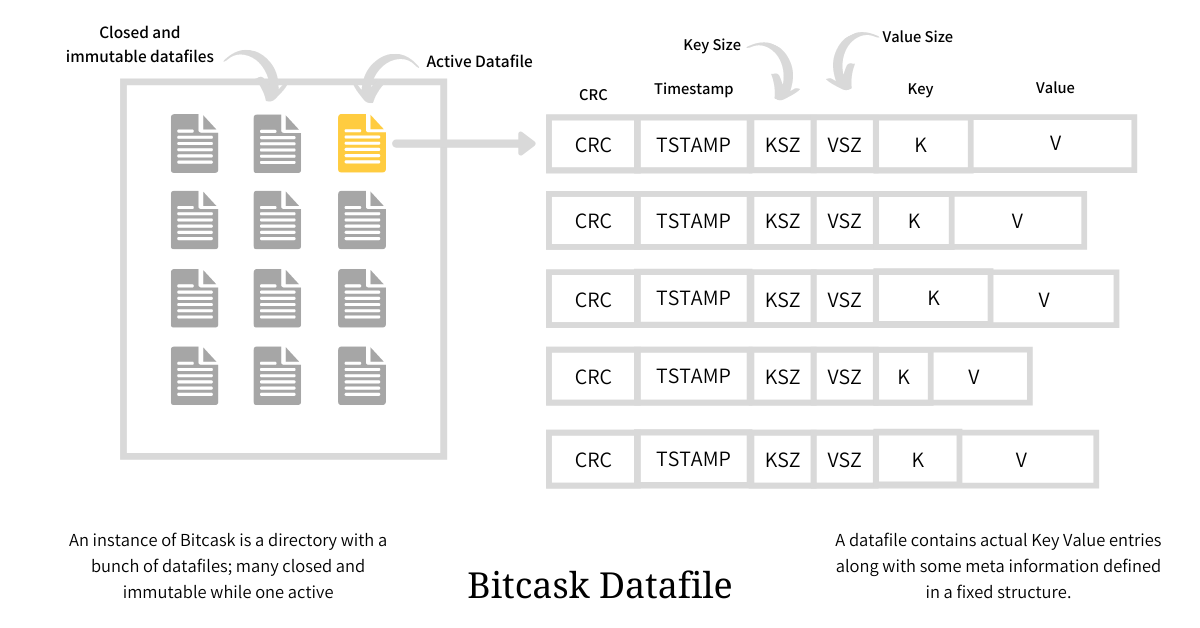
如图右侧,写入的数据按照固定的格式进行组织,包括以下字段:
- CRC:校验值,防止数据被篡改。
- timestamp:时间戳,用于标识写入时间,可以起到版本号的作用。
- KSZ:key size,代表写入 key 的大小。
- VSZ:value size,代表写入 value 的大小。
- key:实际写入的 key。
- value:实际写入的 value。
基于这种仅追加的思想,其将更新和删除都转换为一次写入:
- 更新:写入数据到新的文件中,通过时间戳标识最新数据(类似版本号)。
- 删除:标记删除,通过写入一个墓碑值来标记数据被删除(标记删除,不会实际去删,而是在后续合并流程中删)。
内存结构
在内存中,BitCask 维护了一个名叫 KeyDir 的结构作为索引,由哈希表实现(也可以采用跳表、红黑树、AVL 等实现)。其映射了每个 Key 与其 value 对应的存储位置(file id、value size、offset、timestamp)。在读取时通过 file id 确认读取文件,再通过 offset 和 value size 读取出指定区域的内容,即可获取到完整的数据
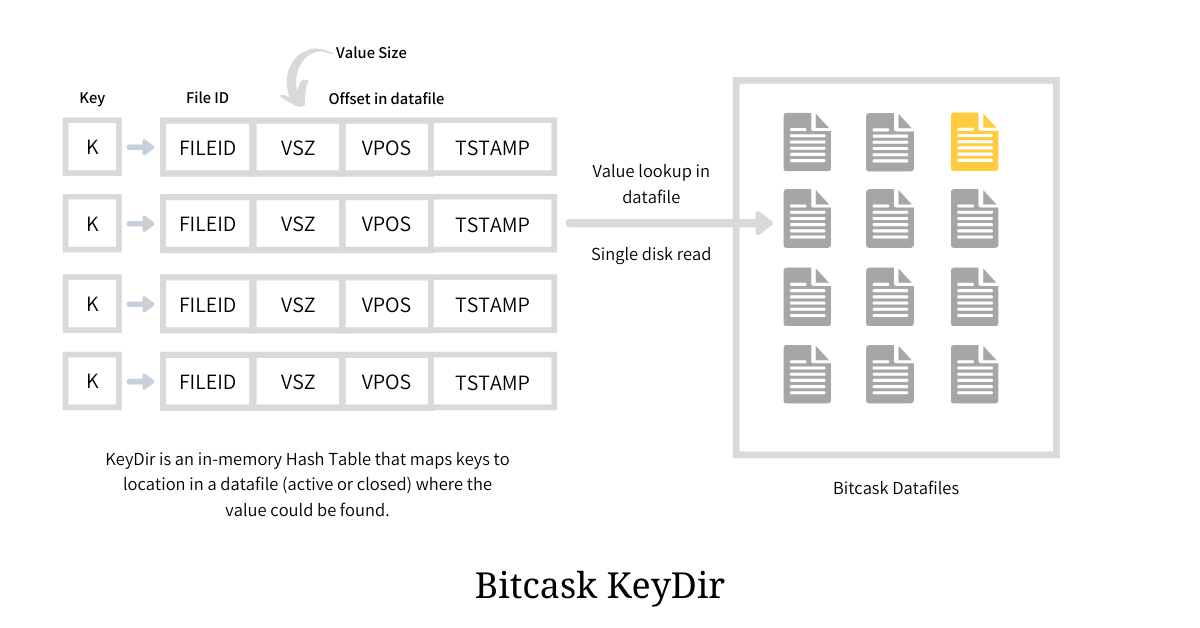
在 KeyDir 中,始终存储的是最新的 value 的位置,即使一个 Key 多次写入,我们也只需要通过一次磁盘 I/O 即可找到数据。
合并与快启动
随着我们不断的追加写入,同样的数据可能会存在多份,这也就导致数据量越来越膨胀。此时,就需要通过合并(merge)来清理掉所有无效的数据。
如下图,在合并时,首先会遍历所有的旧文件(不可变),过滤掉所有被标记删除的文件,同时会基于时间戳进行比对,保留所有数据的最新版本,将所有数据全部写入到新的数据文件中,再将旧文件删除。
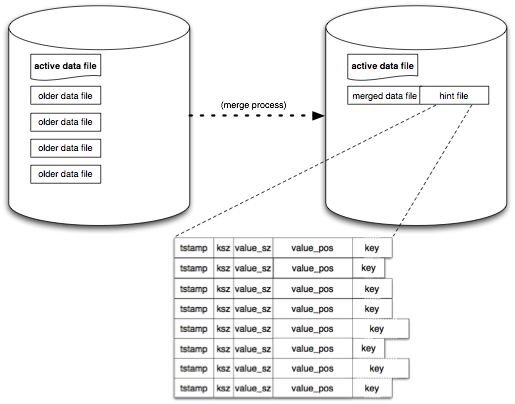
在完成合并后,对于每一个数据文件,会生成一个简易版本(不包含 value)——hint 作为索引文件。当我们启动 BitCask 时,就可以通过直接加载更少的数据,来快速的构建索引,提高启动速度。
优缺点
优点
- 读写低延时:写入仅追加,读取直接访问指定文件,读写都仅有一次磁盘 I/O。
- 高吞吐量:基于仅追加思想实现,顺序 I/O 保障了吞吐量。
- 支持比内存大得多的数据集:内存中仅存储 Key 和元数据,不存储 Value。
- 崩溃恢复快:在 BitCask 中数据文件其实就是每次的提交日志,易于重放,同时 hint 也可以加速重启。
- 易于备份与恢复:旧文件不可变,可以通过复制/粘贴旧文件来快速的备份与恢复。
- 设计简单,结构易管理:基础实现只需要一个内存哈希表和一个追加日志,非常简单。内存中也没有复杂的缓存机制,主要依赖于 FileSystem 的 PageCache。
缺点
- 存储量受限于内存:需要有足够的内存来存储 Key 和元数据。这个问题可以通过对 Key 分片并进行水平拓展来解决。
- 不支持 Range 操作:数据无序组织,无法直接进行 Range 操作。



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











