







tidb的聚合函数算法
tidb实现了两种聚合函数的算法:Hash Aggregation 和 Stream Aggregation
对于数据无序的,使用Hash Aggregation。
对于数据按照groupby字段有序的,使用Stream Aggregation。
以avg聚合函数作为例子,在执行时需要维护两个中间值sum和count。
Hash Aggregation
在 Hash Aggregate 的计算过程中,我们需要维护一个 Hash 表,Hash 表的键为聚合计算的 Group-By 列,值为聚合函数的中间结果 sum 和 count。在本例中,键为 列 a 的值,值为 sum(b) 和 count(b)。
计算过程中,只需要根据每行输入数据计算出键,在 Hash 表中找到对应值进行更新即可。对本例的执行过程模拟如下。
输入数据 a b | Hash 表 [key] (sum, count) |
|---|---|
| 1 9 | [1] (9, 1) |
| 1 -8 | [1] (1, 2) |
| 2 -7 | [1] (1, 2) [2] (-7, 1) |
| 2 6 | [1] (1, 2) [2] (-1, 2) |
| 1 5 | [1] (6, 3) [2] (-1, 2) |
| 2 4 | [1] (6, 3) [2] (3, 3) |
输入数据输入完后,扫描 Hash 表并计算,便可以得到最终结果:
| Hash 表 | avg(b) |
|---|---|
[1] (6, 3) | 2 |
[2] (3, 3) | 1 |
Stream Aggregation
Stream Aggregate 的计算需要保证输入数据按照 Group-By 列有序。在计算过程中,每当读到一个新的 Group 的值或所有数据输入完成时,便对前一个 Group 的聚合最终结果进行计算。
对于本例,我们首先对输入数据按照 a 列进行排序。排序后,本例执行过程模拟如下。
| 输入数据 | 是否为新 Group 或所有数据输入完成 | (sum, count)| avg(b) | |
|---|---|---|---|
| 1 9 | 是 | (9, 1) | 前一个 Group 为空,不进行计算 |
| 1 -8 | 否 | (1, 2) | |
| 1 5 | 否 | (6, 3) | |
| 2 -7 | 是 | (-7, 1) | 2 |
| 2 6 | 否 | (-1, 2) | |
| 2 4 | 否 | (3, 3) | |
| 是 | 1 |
因为 Stream Aggregate 的输入数据需要保证同一个 Group 的数据连续输入,所以 Stream Aggregate 处理完一个 Group 的数据后可以立刻向上返回结果,不用像 Hash Aggregate 一样需要处理完所有数据后才能正确的对外返回结果。当上层算子只需要计算部分结果时,比如 Limit,当获取到需要的行数后,可以提前中断 Stream Aggregate 后续的无用计算。
当 Group-By 列上存在索引时,由索引读入数据可以保证输入数据按照 Group-By 列有序,此时同一个 Group 的数据连续输入 Stream Aggregate 算子,可以避免额外的排序操作。
聚合的类型
由于分布式计算的需要,TiDB 对于聚合函数的计算阶段进行划分,相应定义了 5 种计算模式:CompleteMode,FinalMode,Partial1Mode,Partial2Mode,DedupMode。不同的计算模式下,所处理的输入值和输出值会有所差异,如下表所示:
| AggFunctionMode | 输入值 | 输出值 |
|---|---|---|
| CompleteMode | 原始数据 | 最终结果 |
| FinalMode | 中间结果 | 最终结果 |
| Partial1Mode | 原始数据 | 中间结果 |
| Partial2Mode | 中间结果 | 进一步聚合的中间结果 |
| DedupMode | 原始数据 | 去重后的原始数据 |
并行聚合的操作
TiDB 的并行 Hash Aggregation 算子执行过程中的主要线程有:Main Thead,Data Fetcher,Partial Worker,和 Final Worker:
- Main Thread 一个:
- 启动 Input Reader,Partial Workers 及 Final Workers
- 等待 Final Worker 的执行结果并返回
- Data Fetcher 一个:
- 按 batch 读取子节点数据并分发给 Partial Worker
- Partial Worker 多个:
- 读取 Data Fetcher 发送来的数据,并做预聚合
- 将预聚合结果根据 Group 值 shuffle 给对应的 Final Worker
- Final Worker 多个:
- 读取 PartialWorker 发送来的数据,计算最终结果,发送给 Main Thread
Hash Aggregation 的执行阶段可分为如下图所示的 5 步:
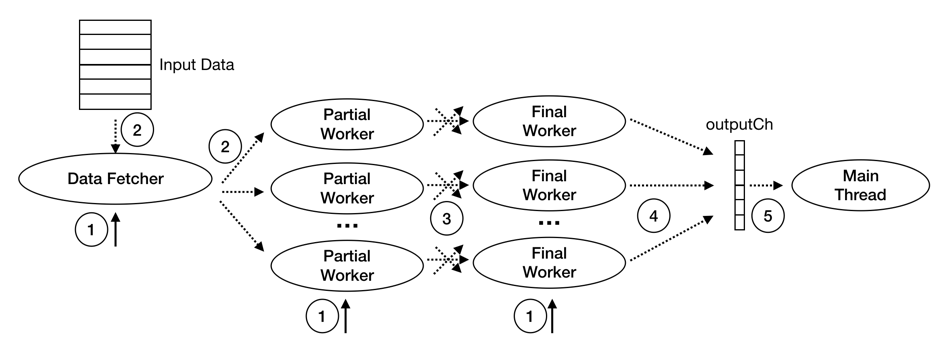
-
启动 Data Fetcher,Partial Workers 及 Final Workers。
这部分工作由 prepare4Parallel 函数完成。该函数会启动一个 Data Fetcher,多个 Partial Worker 以及 多个 Final Worker。Partial Worker 和 Final Worker 的数量可以分别通过
tidb_hashgg_partial_concurrency和tidb_hashagg_final_concurrency系统变量进行控制,这两个系统变量的默认值都为 4。 -
DataFetcher 读取子节点的数据并分发给 Partial Workers。
这部分工作由 fetchChildData 函数完成。
-
Partial Workers 预聚合计算,及根据 Group Key shuffle 给对应的 Final Workers。
这部分工作由 HashAggPartialWorker.run 函数完成。该函数调用 updatePartialResult 函数对 DataFetcher 发来数据执行 预聚合计算,并将预聚合结果存储到 partialResultMap 中。其中
partialResultMap的 key 为根据Group-By的值 encode 的结果,value 为 PartialResult 类型的数组,数组中的每个元素表示该下标处的聚合函数在对应 Group 中的预聚合结果。shuffleIntermData 函数完成根据 Group 值 shuffle 给对应的 Final Worker。 -
Final Worker 计算最终结果,发送给 Main Thread。
这部分工作由 HashAggFinalWorker.run 函数完成。该函数调用 consumeIntermData 函数 接收 PartialWorkers 发送来的预聚合结果,进而 合并 得到最终结果。getFinalResult 函数完成发送最终结果给 Main Thread。
-
Main Thread 接收最终结果并返回。
tbase的聚合函数算法
tbase的聚合函数算法介绍:https://cloud.tencent.com/developer/article/1429767
tbase的资料比较少。

我们先看一下什么是社区聚合?社区聚合是对于单节点并行的,用一个Gather算子收集各个DN节点的结果。可优化的方式是把要聚合的表/中间表数据进行分片,分完片后每个worker对应于某一个片进行聚合。第一次聚合完之后(现在只是某一个分片聚合)gather算子会把多个一次聚合的结果,再进行第二次聚合然后得到最终结果。这其中有一个问题是:Gather算子这个地方是没法并行的,这可能是影响性能的一个瓶颈,我们怎么优化呢?

具体优化如下:第一步是一样的,每个分片进行聚合。但聚合完之后不是由gather再次聚合,而是把每个分片都广播到所有的worker上面去,每个worker负责对应某一个分片,这就不需要gather即可直接得到最终结果,也就是说我们第二次聚合也能实现并行。
当然不仅仅是性能的优化,我们知道社区聚合方式一旦有一个聚合算子,整个执行计划的并行度都会受到影响,因为前面所有的结果都是在一个点聚合的。当我们整体并行计算后,能够解决聚合算子成为并行执行当中的独木桥的问题。效率会提升,整个并行度大幅增加。
tbase和tidb的聚合算法异同
相同处
- 均使用了并行聚合函数的操作。
- 聚合都有两个阶段,预聚合和最终聚合
- 都用到了hash的方式寻找聚合
- 都采用了预处理结果分发给多个线程的方式来执行最终聚合。
不同处
- tidb除了hash聚合的方式外还实现了流式聚合的方式。
- tidb的预聚合处理和最终聚合处理在不同的线程中处理。tbase的是在一个线程中。
- tbase的聚合阶段有多种类型,最多的有三层聚合操作,tbase看不出,但图中最多为两层。
















 1600
1600











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











