







开始学习《ClickHouse原理解析与应用实践》,写博客作读书笔记。
本文全部内容都来自于书中内容,个人提炼。

第六章:
第7章 MergeTree系列表引擎
7.1 MergeTree
本节将进一步介绍MergeTree家族独有的另外两项能力 ——数据TTL与存储策略。
7.1.1 数据TTL
TTL即Time To Live,它表示数据的存活时间。
在MergeTree中,可以为某个列字段或整张表设置TTL。 列级别删除列数据,表级别删除表数据,同时设置的话以先到期的为主。
TTL需要依赖于DateTime或Date类型的字段。
-- 数据存活时间是time_col时间的3天之后
TTL time_col + INTERVAL 3 DAY
-- 数据存活时间是time_col时间的1月之后
TTL time_col + INTERVAL 1 MONTHINTERVAL完整的操作包括SECOND、 MINUTE、HOUR、DAY、WEEK、MONTH、QUARTER和YEAR。
1.列级别TTL
主键字段不能被声明TTL。
举例:create_time是日期类型,列字段code与type均被设置了TTL,它们的存活时间是在 create_time的取值基础之上向后延续10秒。
sql尝试:
CREATE TABLE ttl_table_v1(
id String,
create_time DateTime,
code String TTL create_time + INTERVAL 10 SECOND,
type UInt8 TTL create_time + INTERVAL 10 SECOND
)
ENGINE = MergeTree
PARTITION BY toYYYYMM(create_time)
ORDER BY id
INSERT INTO TABLE ttl_table_v1 VALUES('A000',now(),'C1',1),
('A000',now() + INTERVAL 10 MINUTE,'C1',1);
SELECT * FROM ttl_table_v1;
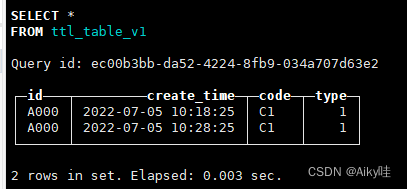
等待10s之后再次查询
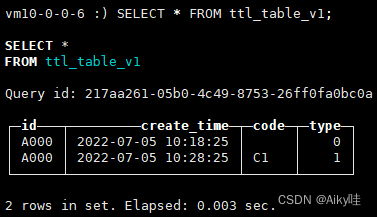
如果没有清除,执行optimize TABLE ttl_table_v1 FINAL再次尝试。
能够看到,由于第一行数据满足TTL过期条件(当前系统时间 >=create_time+10秒),它们的code和type列会被还原为数据类型的默认值。
修改列字段的TTL,或是为已有字段添加TTL,则可以使用ALTER语句:
ALTER TABLE ttl_table_v1 MODIFY COLUMN code String TTL create_time + INTERVAL 1 DAY目前ClickHouse没有提供取消列级别TTL的方法。
2.表级别TTL
当触发TTL清理时,那些满足过期时间的数据行将会被整行删除。
CREATE TABLE ttl_table_v2(
id String,
create_time DateTime,
code String TTL create_time + INTERVAL 1 MINUTE,
type UInt8
)ENGINE = MergeTree
PARTITION BY toYYYYMM(create_time)
ORDER BY create_time
TTL create_time + INTERVAL 1 DAY
ALTER TABLE ttl_table_v2 MODIFY TTL create_time + INTERVAL 3 DAY表级别TTL目前也没有取消的方法。
3.TTL的运行机理
在写入数据时,会以数据分区为单位,在每个分区目录内生成一个名为ttl.txt的文件。
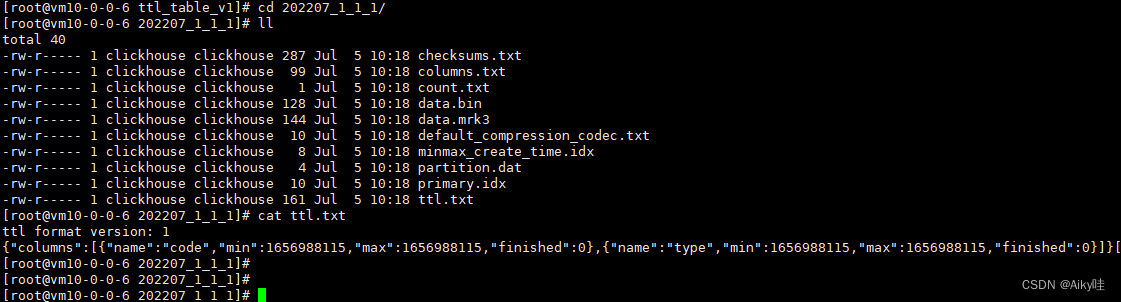
来MergeTree是通过一串JSON配置保存了TTL的相关信息。
其中:
- columns用于保存列级别TTL信息;
- table用于保存表级别TTL信息;
min和max则保存了当前数据分区内,TTL指定日期字段的最小值、最大值分别与INTERVAL表达 式计算后的时间戳。
SELECT
toDateTime('1656988115') AS ttl_min,
toDateTime('1656988115') AS ttl_max,
ttl_min - MIN(create_time) AS expire_min,
ttl_max - MAX(create_time) AS expire_max
FROM ttl_table_v1 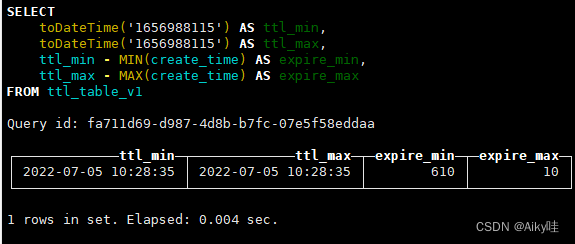
能够发现ttl.txt中记录的极值区间恰好等于当前数据分区内create_time最小与最大值增加10s。
与TTL表达式code String TTL create_time + INTERVAL 10 SECOND相符。
TTL大致处理逻辑:
- 每写入一批数据,会基于INTERVAL表达式的计算结果为这个分区生成ttl.txt文件,ttl.txt文件记录过期时间。
- 只有在MergeTree合并分区时,才会触发删除TTL过期数据的逻辑。
- 在选择删除的分区时,会使用贪婪算法,它的算法规则是尽可能找到会最早过期的,同时年纪又是最老的分区(合并次数更多,MaxBlockNum更大的)。
- 如果一个分区内某一列数据因为TTL到期全部被删除了,那么在合并之后生成的新分区目录中,将不会包含这个列字段的数据文件(.bin和.mrk)。
TTL默认的合并频率由MergeTree的merge_with_ttl_timeout参数控制,默认86400秒,即1天。它维护的是一个专有的TTL任务队列。有别于MergeTree的常规合并任务,如果这个值被设置的过小,可能会带来性能损耗。
可以使用optimize命令强制触发合并。
-- 触发一个分区合并
optimize TABLE table_name
-- 触发所有分区合并
optimize TABLE table_name FINAL
-- 控制全局TTL合并任务的启停方法
SYSTEM STOP/START TTL MERGES7.1.2 多路径存储策略
自定义存储策略的功能,支持以数据分区为最小移动单元,将分区目录写入多块磁盘目录。
根据配置策略的不同,目前大致有三类存储策略:
- 默认策略:MergeTree原本的存储策略,无须任何配置,所有分区会自动保存到config.xml配置中path指定的路径下。
- JBOD策略:一种轮询策略,每执行一次INSERT或者 MERGE,所产生的新分区会轮询写入各个磁盘。适合服务器挂载了多块磁盘,但没有做RAID的场景,可以降低单块磁盘的负载,在一定条件下能够增加数据并行读写的性能。
- HOT/COLD策略:HOT区域使用SSD这类高性能存储媒介,注重存取性能; COLD区域则使用HDD这类高容量存储媒介,注重存取经济性。数据在写入MergeTree 之初,首先会在HOT区域创建分区目录用于保存数据,当分区数据大小累积到阈值时,数据会自行移动到COLD区域。每个区域内可以多块磁盘,实现JBOD策略。
存储配置需要预先定义在config.xml配置文件中,由storage_configuration标签表示。
在storage_configuration之下又分为disks和policies两组标签,分别表示磁盘与存储策略。
<storage_configuration>
<disks>
<disk_name_a> <!--自定义磁盘名称 -->
<path>/chbase/data</path><!—磁盘路径 -->
<keep_free_space_bytes>1073741824</keep_free_space_bytes>
</disk_name_a>
<disk_name_b>
<path>… </path>
</disk_name_b>
</disks>
<policies>
<policie_name_a> <!--自定义策略名称 -->
<volumes>
<volume_name_a> <!--自定义卷名称 -->
<disk>disk_name_a</disk>
<disk>disk_name_b</disk>
<max_data_part_size_bytes>1073741824</max_data_part_size_bytes>
</volume_name_a>
</volumes>
<move_factor>0.2</move_factor>
</policie_name_a>
<policie_name_b>
</policie_name_b>
</policies>
</storage_configuration>
- <disk_name_*> 必填项,必须全局唯一,表示磁盘的自定义名称;
- <path>必填项,用于指定磁盘路径;
- <keep_free_space_bytes>选填项,以字节为单位,用于定义磁盘的预留空间。
- <policie_name_*>必填项,必须全局唯一,表示策略的自定义名称;
- <volume_name_*>必填项,必须全局唯一,表示卷的自定义名称;
- <disk>必填项,引用先前定义的disks磁盘,用于关联配置内的磁盘,可以声明多个disk,MergeTree会按定义的顺序选择disk;
- <max_data_part_size_bytes>选填项,以字节为单位,表示在这个卷的单 个disk磁盘中,一个数据分区的最大存储阈值,如果当前分区的数据大小超过阈 值,则之后的分区会写入下一个disk磁盘;
- <move_factor>选填项,默认为0.1;如果当前卷的可用空间小于factor因子,并且定义了多个卷,则数据会自动向下一个卷移动。
1.JBOD策略
<storage_configuration>
<!--自定义磁盘配置 -->
<disks>
<disk_hot1> <!--自定义磁盘名称 -->
<path>/chbase/data</path>
</disk_hot1>
<disk_hot2>
<path>/chbase/hotdata1</path>
</disk_hot2>
<disk_cold>
<path>/chbase/cloddata</path>
<keep_free_space_bytes>1073741824</keep_free_space_bytes>
</disk_cold>
</disks>
<!-- 实现JDOB效果 -->
<policies>
<default_jbod> <!--自定义策略名称 -->
<volumes>
<jbod> <!—自定义名称 磁盘组 -->
<disk>disk_hot1</disk>
<disk>disk_hot2</disk>
</jbod>
</volumes>
</default_jbod>
</policies>
</storage_configuration>首先在disks中配置3块磁盘。
然后配置一个存储策略,在volumes卷下引用两块磁盘,组成一个磁盘组。
一个支持JBOD策略的存储策略就配置好了。
直接使用书中的演示:
-- 查看磁盘配置
SELECT
name,
path,formatReadableSize(free_space) AS free,
formatReadableSize(total_space) AS total,
formatReadableSize(keep_free_space) AS reserved
FROM system.disks
┌─name─────┬─path────────┬─free────┬─total────┬─reserved─┐
│ default │ /chbase/data/ │ 38.26 GiB │ 49.09 GiB │ 0.00 B │
│ │ │ │ │ │
│ disk_cold │ /chbase/cloddata/ │ 37.26 GiB │ 48.09 GiB │ 1.00 GiB │
│ disk_hot1 │ /chbase/data/ │ 38.26 GiB │ 49.09 GiB │ 0.00 B │
│ disk_hot2 │ /chbase/hotdata1/ │ 38.26 GiB │ 49.09 GiB │ 0.00 B │
└────────┴────────────┴────────┴────────┴───────┘
-- 查看配置的存储策略
SELECT policy_name,
volume_name,
volume_priority,
disks,
formatReadableSize(max_data_part_size) max_data_part_size ,
move_factor FROM
system.storage_policies
┌─policy_name─┬─volume_name─┬─disks──────────┬─max_data_part_size─┬─move_factor─┐
│ default │ default │ ['default'] │ 0.00 B │ 0 │
│ default_jbod │ jbod │ ['disk_hot1','disk_hot2']│ 0.00 B │ 0.1 │
└────────┴────────┴─────────────┴──────────┴─────────┘
-- 定义表的时候使用jbod
CREATE TABLE jbod_table(
id UInt64
)ENGINE = MergeTree()
ORDER BY id
SETTINGS storage_policy 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 9570
9570











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











