







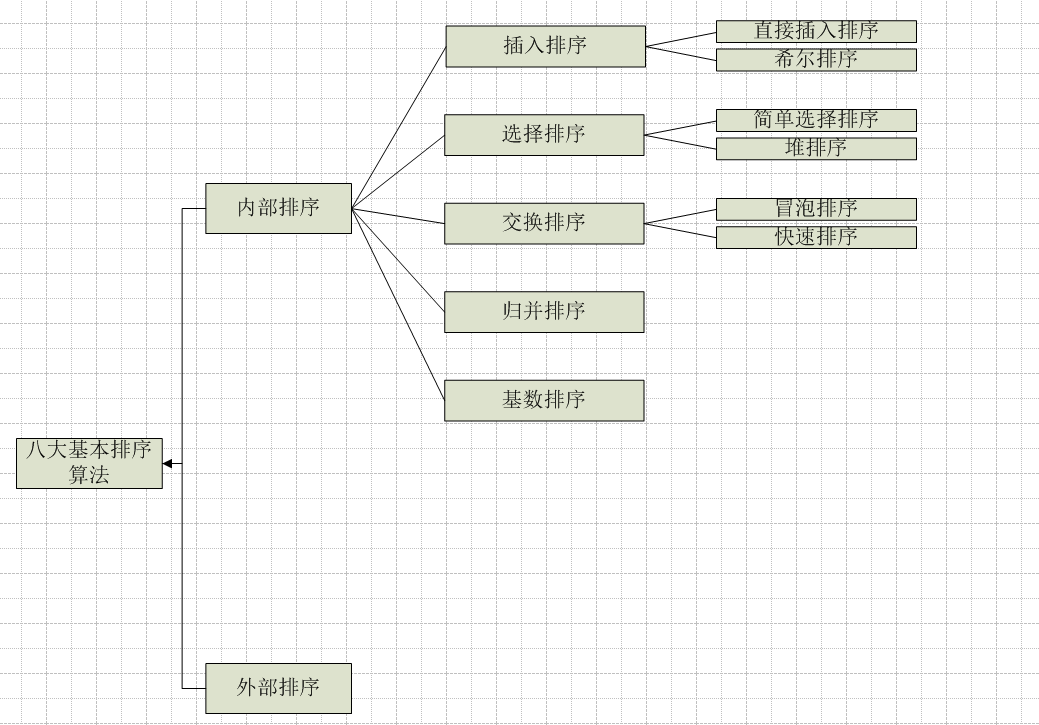
排序有内部排序和外部排序,内部排序是数据记录在内存中进行排序,而外部排序一般是排序的数据量很大,一次不能容纳全部的排序记录,在排序过程中需要访问外存。我们经常说的八大排序说的就是内部排序。
冒泡排序算法:(从后往前)bubbleSort
- 比较相邻的两个数,若前面的数大于后面的数,则交换两个数;
- 这样对0到n-1个数据进行遍历,那么最大的数据就会被排到n-1处;
- 重复步骤,直至再也不能交换。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
对于一些数据,前面部分是乱序的,而后面部分是有序的。当前面的排序好后,后面的元素排序还需要重复前面的操作,这种做法是非常多余的。对与这种情况可以做出优化,比如加上一个标志(flag),初始值为false,有交换则置为true,如果某次排序没有交换元素,则表明后面的元素是有序的,跳出循环,排序结束。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
时间复杂度O(n^2) , 算法稳定性:稳定(如果两个元素相等,我想你是不会再无聊地把他们俩交换一下)
快速排序算法(快排):quickSort
它的基本思想是:通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列。
注意:第一遍快速排序不会直接得到最终结果,只能确定一个数的最终位置。为了得到最后结果,必须继续分解数组,直到数组不能再分解为止(只有一个数据),才能得到正确结果。
- 先从数列中取出一个数作为基准数
- 分区过程,将比这个数大的数全放到它的右边,小于或等于它的数全放到它的左边。
- 再对左右区间重复第二步,直到各区间只有一个数。
快速排序算法是基于分治法的:
分治法+挖坑( 先从后向前找,再从前向后找):
3 4 6 8 9 10 5 2 16
首先选定一个枢纽数3,pivotkey=a[0] , a[0]被保存到pivotkey中,可以被认为,在a[0]上挖了一个坑,可以将其他数据填充到这里来。然后从后向前找到小于pivotkey的值2,a[0]=a[7],a[0]上的坑被a[7]填上,结果又形成了一个新坑a[7].
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
分治法,但不挖坑,交换的方法。最后的那个坑不需要去填,因为在交换的过程中,已经处理好了。这样,没交换一次就需要进行3次赋值语句,而实际上,在排序过程中对枢纽节点的赋值是多余的。只需最后赋值,也就是上面的做法。下面是没有改进前的方法。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
有时是以中间的数作为基准数的,要实现这个非常方便,直接将中间的数和第一个数进行交换就可以了。时间复杂度O(nlogn), 算法稳定性:不稳定。
直接插入排序: insertSort
直接插入排序(Insertion Sort)的基本思想是:每次将一个待排序的记录,按其关键字大小插入到前面已经排好序的子序列中的适当位置,直到全部记录插入完成为止。
直接插入排序时使用顺序查找,找到关键字应该插入的位置,然后将该位置后面的所有元素向后移动。然后将要插入的值插入目标位置。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
改进(折半插入排序):在直接插入排序时,采用折半查找的方法找到插入的标记点,然后将标记点后面的元素从后向前依次移动一个位置。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
折半插入排序所需附件的存储空间和直接插入排序相同,从时间复杂度上来讲,折半插入排序仅仅减少了关键字之间的比较次数,但移动次数不变。因此时间复杂度还是O(n^2). 算法稳定性:稳定。
改进:直接插入排序时,将收索和后移两个动作同时进行。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
再对上面的方法进行改写, 用数据交换代替数据后移。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
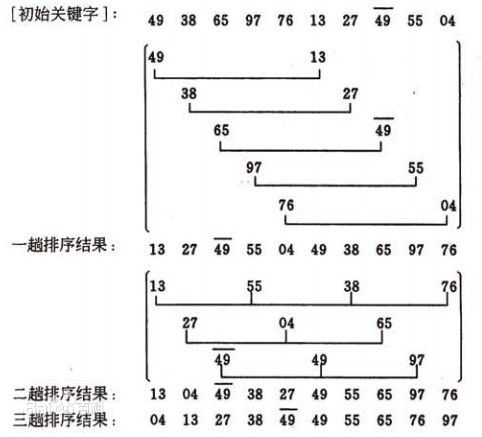
希尔排序::shellSort
希尔排序(Shell Sort)是插入排序的一种。也称缩小增量排序,是直接插入排序算法的一种更高效的改进版本。
基本思想是:先取一个小于n的整数d1作为第一个增量,把文件的全部记录分组。所有距离为d1的倍数的记录放在同一个组中。先在各组内进行直接插入排序;然后,取第二个增量d2(d2小于d1),重复上述的分组和排序;依次取d3、d4、…..直至取到dt=1为止,即所有记录放在同一组中进行直接插入排序。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
该方法实质上是一种分组插入方法。专家们提倡,几乎任何排序工作在开始时都可以用希尔排序,若在实际使用中证明它不够快,再改成快速排序这样更高级的排序算法. 本质上讲,希尔排序算法是直接插入排序算法的一种改进,减少了其复制的次数,速度要快很多。 原因是,当n值很大时数据项每一趟排序需要的个数很少,但数据项的距离很长。当n值减小时每一趟需要和动的数据增多,此时已经接近于它们排序后的最终位置。 正是这两种情况的结合才使希尔排序效率比插入排序高很多。希尔排序的时间复杂度与增量序列的选取有关,O(n^2)~O(nlog2n), 算法稳定性:不稳定。















 1054
1054

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









