为什么要使用线程池?
- 我们先看下面俩个程序的执行结果(太简单了,一看就懂的,不提供源码了,直接截图了):
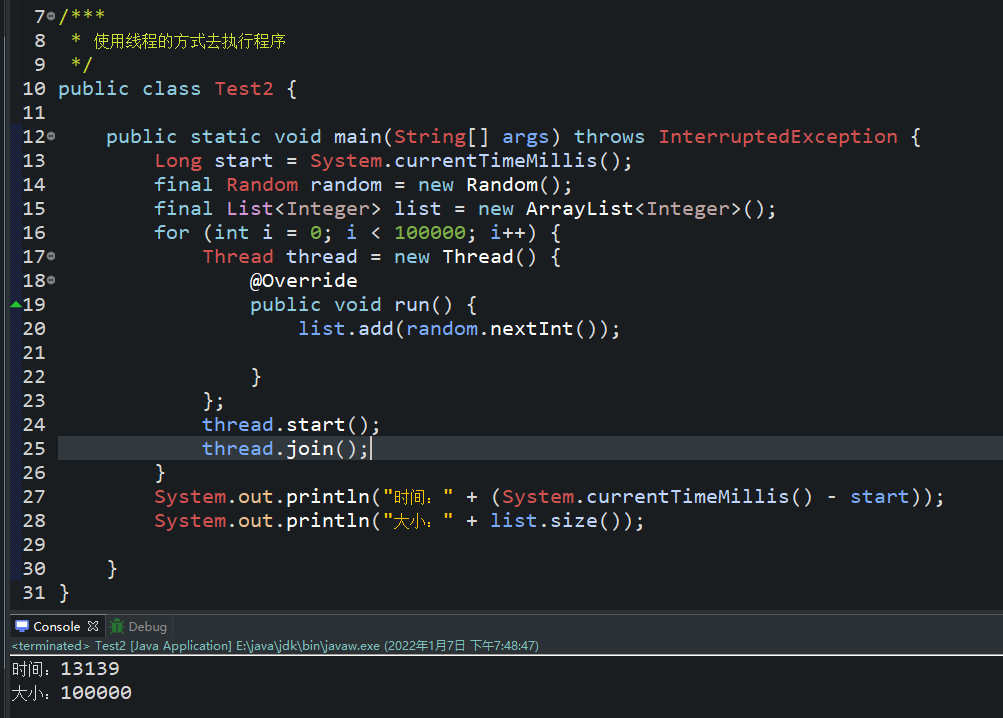
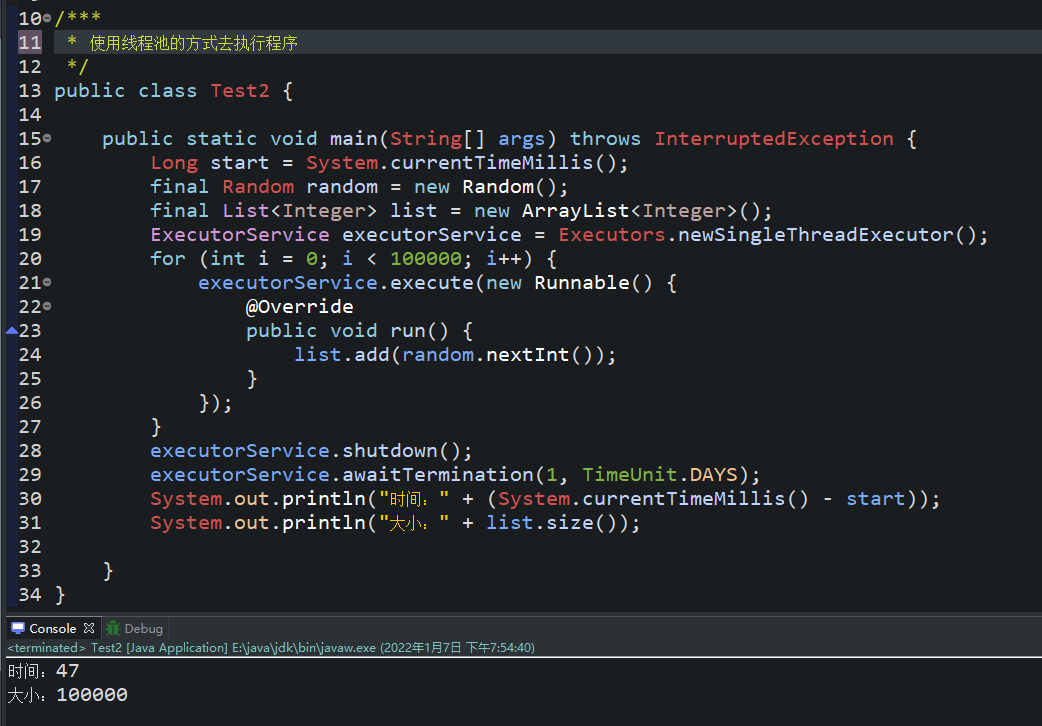
- 产生一个问题:为什么使用线程池会变的这么快呢?线程复用(第一种使用线程的方式,他创建了100001个线程,而使用线程池他只创建的俩个线程)
- 同时又会有一个问题:使用线程池一定会提高性能么? 不是!
验证一下java提供的不同线程池的性能,来理解为什么使用线程池不一定会提高性能!
- 验证的代码为这个代码的简化版,留一个进行验证,其他的注释了就是我验证的代码。
- 线程的的执行速度,可以通过毫秒数去看,日志太多,图中只能看到大概,建议自己去尝试一下!
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.LinkedBlockingQueue;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit;
import com.cangqiong.utils.test.threadPoll.MonkeyRejectedExecutionHandler;
public class ThreadPoolDemo {
public static void main(String[] args) {
ExecutorService executorService1 = Executors.newCachedThreadPool();
ExecutorService executorService2 = Executors.newFixedThreadPool(10);
ExecutorService executorService3 = Executors.newSingleThreadExecutor();
ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(10, 20, 0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>(10), new MonkeyRejectedExecutionHandler());
for (int i = 1; i <= 100; i++) {
executorService1.execute(new MyTask(i));
}
for (int i = 1; i <= 100; i++) {
executorService2.execute(new MyTask(i));
}
for (int i = 1; i <= 100; i++) {
executorService3.execute(new MyTask(i));
}
for (int i = 1; i <= 100; i++) {
threadPoolExecutor.execute(new MyTask(i));
}
}
}
class MyTask implements Runnable {
int i = 0;
public MyTask(int i) {
this.i = i;
}
@Override
public void run() {
System.out.println(Thread.currentThread().getName() + "线程正在执行第" + i + "个。当前的毫秒数为:" + System.currentTimeMillis());
try {
Thread.sleep(3000L);
} catch (Exception e) {
e.printStackTrace();
}
}
}
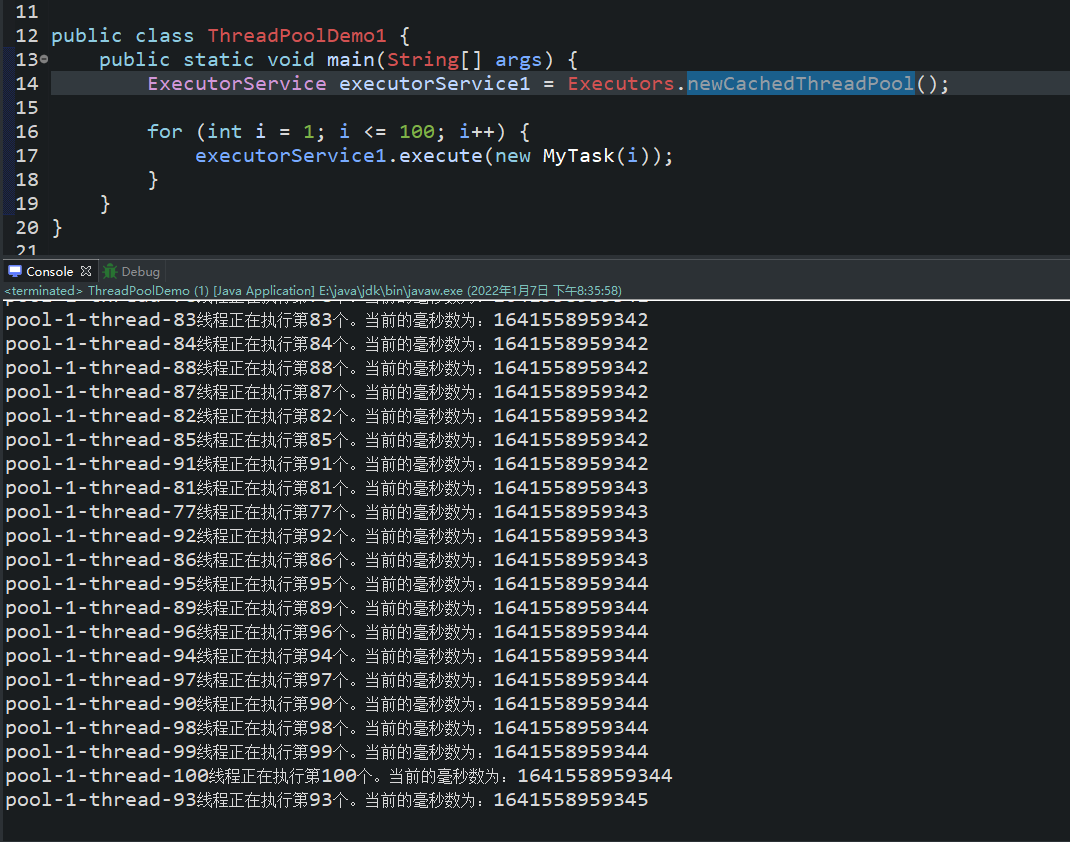
Executors.newCachedThreadPool()的执行结果:执行速度非常快!
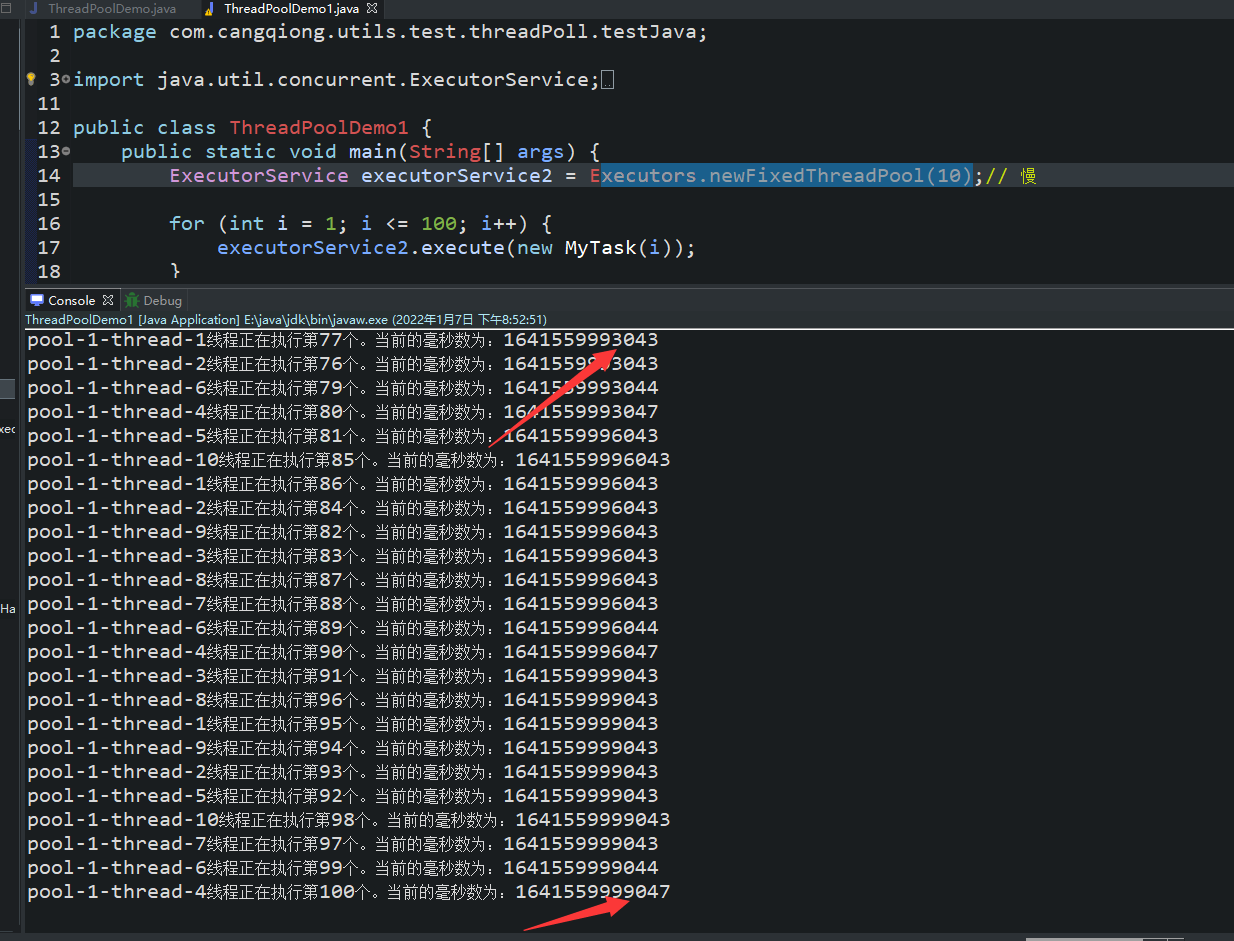
Executors.newFixedThreadPool(10)的执行结果:速度比较慢!
Executors.newSingleThreadExecutor()的执行结果:速度非常非常非常慢!
- 这里又有一个问题:为什么我们同样用一newSingleThreadExecutor去往数组中插入数据和执行这个3秒的任务。俩个的时间相差非常多?这要看执行的任务属于CPU密集型,还是内存的。所以使用线程池或者说使用很多线程去处理,性能不一定很高!
- 因此在使用线程池的时候,要针对不同业务去选择合适的线程池!
- 在实际开发中,不建议直接使用java提供的这些线程池,尽量根据业务去自定义线程池!
为什么使用这三种java提供的线程池,效果不一样呢?
- 我们可以点开他的创建的源码,可以看到都调用了同一个方法
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}
- 所有的创建线程池的工具类的底层都是调用ThreadPoolExecutor方法
- ThreadPoolExecutor有7个参数,下面分别介绍一下。
- corePoolSize:核心线程数,也是线程池中常驻的线程数。注意:线程池初始化时默认是没有线程的,当任务来临时才开始创建线程去执行任务
- maximumPoolSize:最大线程数,在核心线程数的基础上可能会额外增加一些非核心线程。简单理解就是临时的线程。
- keepAliveTime:非核心线程的存在时间。非核心线程的空闲时间超过这个时间,非核心线程就会被回收。如果corePoolSize = maximumPoolSize的时候,不存在非核心线程,所以也不存在回收!
- unit:keepAliveTime的时间单位。
- workQueue:用于保存任务的队列。当任务的数量超过了maximumPoolSize,这时候新的任务就会被存放在这个队列中。
- threadFactory:创建线程的工厂类,默认使用Executors.defaultThreadFactory(),也可以使用guava库的ThreadFactoryBuilder来创建。
- handler:线程池无法继续接收任务(队列已满且线程数达到maximunPoolSize)时的饱和策略,取值有AbortPolicy、CallerRunsPolicy、DiscardOldestPolicy、DiscardPolicy。简单理解就是maximumPoolSize满了放在队列中,队列也满了的时候,应该如何处理!
了解了参数是干什么的,那我们去分析这几个方法有什么区别。
- newCachedThreadPool的核心线程为0,最大线程数为int的最大值。简单理解就是无核心线程,所有线程都是临时的,而且临时的线程上限非常高。换做生活中的例子,一个公司里面一个正式员工没有,全都是外包人员,项目来了之后就开始招收外包人员,干完活把外包人员释放掉。
- newFixedThreadPool的corePoolSize = maximumPoolSize。简单理解就是无非核心线程,全部为核心线程。换做生活中的例子,一个公司里面都是正式员工,没有一个外包!
- newSingleThreadExecutor的corePoolSize = maximumPoolSize = 1。简单理解就是只有一个核心线程。换做生活中的例子,一个公司只有自己一个人,单干的那种!
了解了这些的区别,那我们应该在什么时候去使用这些工具类呢?线程数量应该配置多大呢?
- cpu密集型减少线程数:减少上下文切换。
- io密集型增加线程数:大部分时间在等待其他的响应,上下文切换不是主要影响性能的点,可以让cpu去干其他事情。
- 通过压测去确定这个值!
了解了几种线程池,为什么说不推荐使用呢?
- newCachedThreadPool:他的最新线程数太大了,创建大量的线程会导致cpu需要进行大量的上下文切换,从而很容易引起cpu100%。
- newFixedThreadPool:他的队列使用的是LinkedBlockingQueue,这是一个无界队列!任务比较多的时候,很容易引起OOM。
- newSingleThreadExecutor:他只有一个线程,其他的任务都放在无界队列中。任务比较多的时候,很容易引起OOM。
结束语
- 获取更多有价值的文章,让我们一起成为架构师!
- 关注公众号,可以让你逐步对MySQL以及并发编程有更深入的理解!
- 这个公众号,无广告!!!每日更新!!!
























 204
204











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









