







前言:
看了一大堆网上的介绍没看明白aggregateByKey到底啥意思,自己琢磨半天,感觉知道到底如何用了,特意写出来分享下。
准备:
用java写aggregateByKey,这样好理解一点
算子释义:
aggregateByKey, 先说分为三个参数的:
第一个参数是, 每个key的初始值
第二个是个函数, Seq Function, 经测试这个函数就是用来先对每个分区内的数据按照key分别进行定义进行函数定义的操作
第三个是个函数, Combiner Function, 对经过 Seq Function 处理过的数据按照key分别进行进行函数定义的操作
测试代码如下:
List<Tuple2<String, Integer>> abk = Arrays.asList(
new Tuple2<String, Integer>("class1", 1),
new Tuple2<String, Integer>("class1", 2),
new Tuple2<String, Integer>("class1", 4),
new Tuple2<String, Integer>("class2", 3),
new Tuple2<String, Integer>("class2", 1),
new Tuple2<String, Integer>("class2", 5));
JavaPairRDD<String, Integer> abkrdd = js.parallelizePairs(abk, 3);
abkrdd.mapPartitionsWithIndex(
new Function2<Integer, Iterator<Tuple2<String, Integer>>, Iterator<String>>() {
@Override
public Iterator<String> call(Integer s,
Iterator<Tuple2<String, Integer>> v)
throws Exception {
List<String> li = new ArrayList<>();
while (v.hasNext()) {
li.add("data:" + v.next() + " in " + (s + 1) + " " + " partition");
}
return li.iterator();
}
}, true).foreach(m -> System.out.println(m));
JavaPairRDD<String, Integer> abkrdd2 = abkrdd.aggregateByKey(0,
new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer s, Integer v) throws Exception {
System.out.println("seq:" + s + "," + v);
return Math.max(s, v);
}
}, new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer s, Integer v) throws Exception {
System.out.println("com:" + s + "," + v);
return s + v;
}
});
abkrdd2.foreach(new VoidFunction<Tuple2<String, Integer>>() {
@Override
public void call(Tuple2<String, Integer> s) throws Exception {
System.out.println("c:" + s._1 + ",v:" + s._2);
}
});过程分析:
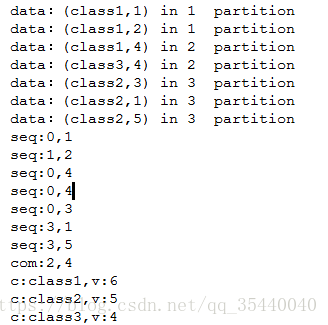
1)输出结果如下:

2)初始数据转为rdd时设置了三个分区,通过mapPartitionWithIndex输出各个数据所在分区如下:
对于partition 1,有数据(class1,1),(class1,2)
对于partition 2,有数据(class1,4),(class2,3)
对于partition 2,有数据(class2,1),(class2,5)
3)然后对rdd进行aggregateByKey操作:
设置第一个参数:初始对比值为0,注意0只会在Seq Function(也就是第二个参数)中使用,若是aggregate算子,在Combiner Function 中也会被使用
设置第二个参数:Seq Function,对每个分区内的数据按照key分别进行定义进行函数定义的操作。
设置第三个参数:Combiner Function, 对经过 Seq Function 处理过的数据按照key分别进行函数定义的操作
4)分析如下:
对于partition 1,先进行Seq Function定义的操作(取最大值):由于key值都是class1,所以过程如下:
data:(class1,1),(class1,2)
key:class1
0 对比1 -> 1
1 对比2 -> 2
故该分区key值对应的最终结果为:(class1,2)
对于partition 2,同上,先进行Seq Function定义的操作(取最大值):但是由于该分区内key值不同,所以过程略有不同,跟上面上比:
data:(class1,4),(class2,3)
key:class1
0 对比4 -> 4
key:class2
0 对比3 -> 3
故该分区key值对应的最终结果为:(class1,4),(class2,3)
注:这块测试一下午,源码一大堆调用看不懂,然后就纳闷到底为啥,我刚开始的时候以为:只要是一个分区内的数据,互相之间都要进行对比,然后看执行流程就是不明白为啥class1的4不给class2的3对比,而是用设置的初始值0去对比,一直以为是分区的问题,感觉(class1,4),(class2,3)不在一个分区,后来特意输出分区,发现确实它俩是在一个分区的,后来就怀疑是不是aggregateByKey即使不使用带分区的有4个参数的那种模式,分区参数也会有个默认值,然后我就去设置了一个分区值,发现并没有影响,还是这种情况,4就是不跟3比,我就不懂了,到底为啥,然后我就出去逛了一会,再回来做到电脑面前,突然福至心灵,悟了,就是如上这个函数就是用来先对每个分区内的数据按照key分别进行定义进行函数定义的操作。做了一些小测试如下:加上一个数据(class3,4),结果如下:
对于partition 3,同上:过程如下:
data:(class2,1),(class2,5)
key:class2
0 对比1 -> 1
1 对比5 -> 5
故该分区key值对应的最终结果为:(class2,5)
然后来到第三个参数所定义的函数:Combiner Function,这个函数是针对的所有分区的数据,按照key分别进行Combiner Function定义的相加操作:
上一步出来的最终结果如下:
partition1:(class1,2)
partition2:(class1,4),(class2,3)
partition3:(class2,5)
然后进行Combiner Function定义的操作:
key:class1
2 + 4 -> 6
然后foreach输出如下:
key:class2
3 + 5 -> 8
然后foreach输出如下:
疑惑:不知道aggregateByKey的分区参数到底有啥用?
def aggregateByKey[U: ClassTag](zeroValue: U, numPartitions: Int)
(seqOp: (U, V) => U, combOp: (U, U) => U): RDD[(K, U)]
以为是重新设定分区,但是尝试后发现,并不是,不知道有啥用,难道是重新分配task任务数??不清楚呀
后记:重分区,这块评论区已解决;好久不编程了,这块都忘得差不多了,感谢评论区的小伙伴。















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









