







tokenization
tokenization是对一串输入字符进行划分和分类的任务,其输出的token将会被用于其他处理。
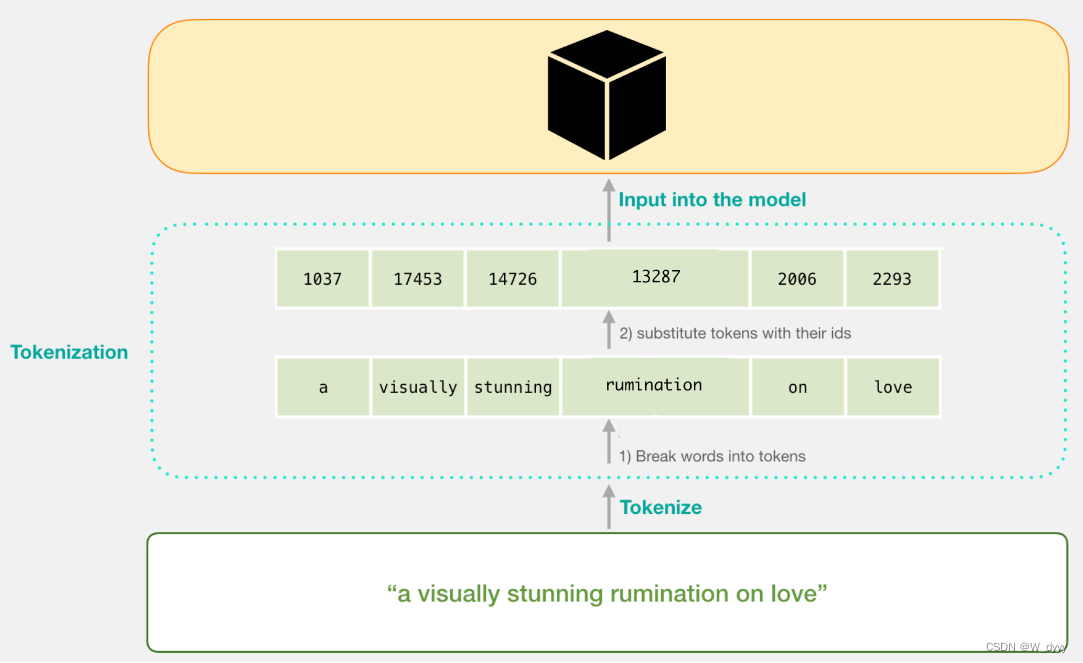
Data Preparation
read a dataset
定义一个MyDataSetReader来读取dataset,这个类接受两个输入
- path:要处理的文本文件路径
- lower:一个布尔型指示texture是否必须小写
class MyDatasetReader(object):
def __init__(self, path, lower = True):
self.path = path
self.lower = lower
def __iter__(self):
for line in open(self.path, 'r', encoding='utf-8'):
yield line # yields only the current line在colab上我们用wiki_10k建立dataset,并观察前5行
data_path = '/content/drive/My Drive/Colab Notebooks/nlp_data'
dataset_path = os.path.join(data_path, "wiki_10k.txt")
i=0
for line in MyDatasetReader(dataset_path):
print(line)
i+=1
if i>5:
breakClean the dataset
我们可以决定哪些dataset中要包含哪些token,根据我们的nlp任务,我们可以根据以下标准来过滤token
filtering stopwords
在很多nlp任务中,消除虚词是很常见的操作,即消除那些语义内容差,连词,介词,代词,情态动词。不同task可以有不同的stopword list。
import nltk
nltk.download('stopwords')
from nltk.corpus import stopwords
stopset = stopwords.words('english')
print(stopset)比如,如果你希望根据内容对文件进行分类,你希望捕获最关键的特征,丢弃不太相关的特征,例如冠词和代词,因为他们几乎出现在所有文本中,对描述文本内容几乎没有用处。
remove numbers
在某些情况(如topic modelling)下,光消除stopwords并不够,你可能想去掉数字,只从文本中提取具有特定主题代表性的单词

Remove alphanumeric tokens
alphanumeric称为文数字,该token可能由OCR错误产生,因此在某些情况下我们可能希望消除它们。
Lowercasing tokens
为了保持模型vocabulary大小并减少稀疏性,我们希望所有token都小写
Remove short tokens
某些情况您可能会希望去除short token,因为对这种token来说,stopwords比较多
Using a predefined number of words
在许多情况下,在模型的词汇表中使用预定义数量的单词是很有用的,这样可以管理其复杂性
Eliminating low-frequency words
由于词频遵循Zipfian分布,因此语料库中有许多低频词,这会影响模型的词汇量带下,在word2vec中也消除了低频词,因为它们很难建模并预测。
from collections import Counter
import re
alpha = re.compile('^[a-zA-Z_]+$') # strings that contain only alpha
alpha_or_num = re.compile('^[a-zA-Z_]+|[0-9_]+$') # strings that contain a combination of letters and numbers
alphanum = re.compile('^[a-zA-Z0-9_]+$') # strings that contain numbers
class MyTokenizer(object):
def __init__(self,
keepStopwords=False, # indicates if the stopwords have to be removed
keepNum = False, # indicates whether the numbers have to be kept or not
keepAlphaNum = False, # indicates whether alphanumeric tokens have to be kept or not
lower = True, # indicates if the strings have to be lowercased
minlength = 0, # indicates the length (in characters) of tokens under which tokens will be removed (this operation is not considered when minlength is 0)
vocabSize = 5000, # indicate the size of the vocabulary (it keeps only the N most frequent words in the dataset)
minfreq = 10e-5, # indicates the frequency under which tokens will be removed
stopset = None, # indicates a custom list of words that will be removed
vocab = None # indicates a predefined vocabulary (only the words in it will be mantained)
):
self.keepStopwords = keepStopwords
self.keepNum = keepNum
self.keepAlphaNum = keepAlphaNum
self.lower = lower
self.minlength = minlength
self.vocabSize = vocabSize
self.minfreq = minfreq
self.vocab = vocab
self.keepStopwords = keepStopwords
if not self.keepStopwords and not stopset:
import string
import nltk
nltk.download('stopwords')
from nltk.corpus import stopwords
stopset = set(stopwords.words('english')+[p for p in string.punctuation])
self.stopset = stopset
def tokenize(self, text):
if not self.lower:
return text.split()
else:
return [t.lower() for t in text.split()]
def get_vocab(self, Tokens):
Vocab = Counter()
for tokens in Tokens:
Vocab.update(tokens)
self.vocab = Counter(Vocab)
def cleanTokens(self, Tokens):
tokens_n = sum(self.vocab.values())
filtered_voc = self.vocab.most_common(self.vocabSize)
Freqs = Counter({t : f/tokens_n for t, f in filtered_voc if
f/tokens_n > self.minfreq and
t not in self.stopset
})
words = list(Freqs.keys())
# remove tokens that contain numbers
if not self.keepAlphaNum and not self.keepNum:
words = [w for w in words if alpha.match(w)]
# or just remove tokens that contain a combination of letters and numbers
elif not self.keepAlphaNum:
words = [w for w in words if alpha_or_num.match(w)]
words.sort()
self.words = words
words2idx = {w : i for i, w in enumerate(words)}
self.words2idx = words2idx
print('Vocabulary')
print(words[:12])
cleanTokens = []
for tokens in Tokens:
cleanTokens.append([t for t in tokens if t in words])
self.tokens = cleanTokens
tokenizer = MyTokenizer()
Tokens = [tokenizer.tokenize(text) for text in MyDatasetReader(dataset_path)]
tokenizer.get_vocab(Tokens)
print('Most frequent words')
print(tokenizer.vocab.most_common(12))
tokenizer.cleanTokens(Tokens)Out-of-Vocabulary Words (OOV)
移除stopwords的优点是很方便,因为它可以控制vocabulary的大小以及data的稀疏性。但缺点是模型不知道如何处理out-vocabulary-words (OOV),即词汇表vocabulary外的词。比如,一些lamma词频比较低,所以可能会被从dataset中删除,为了处理这种情况,可以将OOV单词映射到词汇表的相同条目。
Subword Information
另一种方法是利用语言的morphology。FastText (https://fasttext.cc/docs/en/crawl-vectors.html),不是在token级建立单词的表示,而是使用n-gram,允许将OOV单词表示为其成分(n-gram)的总和。例如:当n=3时,单词where将被标记为<wh, when, her, ere, re>
Byte Pair Encoding (BPE)
Byte Paire Encoding(BPE)是一种数据压缩技术,它用单个未使用的字节迭代地替换序列中最频繁的字节对,该算法适用于word segmentation。例如,算法迭代计数所有符号对,并替换出现频率最高的符号对(例如‘A’,'B'用新符号'AB'替换)
import re, collections
# compute the occurrencies of symbol pairs
def get_stats(vocab):
pairs = collections.defaultdict(int)
for word, freq in vocab.items():
symbols = word.split()
for i in range(len(symbols)-1):
pairs[symbols[i],symbols[i+1]] += freq
return pairs
# updates the vocabulary with a new sequence
def merge_vocab(pair, v_in):
v_out = {}
bigram = re.escape(' '.join(pair))
p = re.compile(r'(?<!\S)' + bigram + r'(?!\S)')
for word in v_in:
w_out = p.sub(''.join(pair), word)
v_out[w_out] = v_in[word]
return v_out
# initial vocabulary (</w>) indicates the end of the token
vocab = {'l o w </w>' : 5, 'l o w e r </w>' : 2, 'n e w e s t </w>':6,'w i d e s t </w>':3}
# number of merges to be performerd
num_merges = 10
for i in range(num_merges):
pairs = get_stats(vocab) # compute the occurrencies of symbol pairs
best = max(pairs, key=pairs.get) # find the most frequent pair
vocab = merge_vocab(best, vocab) # merge a symbols pair
print(best) # print the merged symbols
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









