







java实现从url路径中下载文件到本地
参考文章:《java实现从url路径中下载pdf文档到本地》
对该篇的内容,进行了调整,实现下载url上的文件名的具体内容,就不用指定名称了。
代码:
public class DownLoadFileUtils {
/**
* 从网络Url中下载文件
* @param urlStr url的路径
* @throws IOException
*/
public static void downLoadByUrl(String urlStr,String savePath) {
try {
String fileName = getFileName(urlStr);
URL url = new URL(urlStr);
HttpURLConnection conn = (HttpURLConnection)url.openConnection();
//设置超时间为5秒
conn.setConnectTimeout(5*1000);
//防止屏蔽程序抓取而返回403错误
conn.setRequestProperty("User-Agent", "Mozilla/4.0 (compatible; MSIE 5.0; Windows NT; DigExt)");
//得到输入流
InputStream inputStream = conn.getInputStream();
//获取自己数组
byte[] getData = readInputStream(inputStream);
//文件保存位置
File saveDir = new File(savePath);
if(!saveDir.exists()){ // 没有就创建该文件
saveDir.mkdir();
}
File file = new File(saveDir+File.separator+fileName);
FileOutputStream fos = new FileOutputStream(file);
fos.write(getData);
fos.close();
inputStream.close();
System.out.println("the file: "+url+" download success");
}catch (Exception e){
e.printStackTrace();
}
}
/**
* 从输入流中获取字节数组
* @param inputStream
* @return
* @throws IOException
*/
private static byte[] readInputStream(InputStream inputStream) throws IOException {
byte[] buffer = new byte[4*1024];
int len = 0;
ByteArrayOutputStream bos = new ByteArrayOutputStream();
while((len = inputStream.read(buffer)) != -1) {
bos.write(buffer, 0, len);
}
bos.close();
return bos.toByteArray();
}
public static void main(String[] args) {
try{
String filePath = "https://docs.spring.io/spring-framework/docs/4.2.0.RC1/spring-framework-reference/pdf//spring-framework-reference.pdf";
filePath = "https://docs.spring.io/spring-framework/docs/1.0.0/license.txt";
filePath = "https://www.w3school.com.cn/i/eg_tulip.jpg";
filePath = "https://www.w3school.com.cn/example/xmle/note.xml";
downLoadByUrl(filePath,"F:/temp/download");
}catch (Exception e) {
e.printStackTrace();
}
}
/**
* 从src文件路径获取文件名
* @param srcRealPath src文件路径
* @return 文件名
*/
private static String getFileName(String srcRealPath){
return StringUtils.substringAfterLast(srcRealPath,"/");
}
}结果:
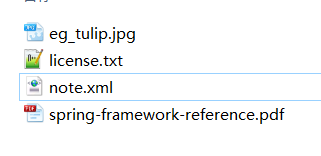
总结:
在处理src内容下载的时候,通过 HttpURLConnection 将其变成数据流,这个是重点。获取到数据流,下载就简单了。文件名就根据url上的后缀去处理,这样适应性会更高一些。
这下载的文件比较大,会比较久,尤其下载spring下的,网络慢啊啊啊!
作者:锋齐叶落
原文: https://www.cnblogs.com/qianzf/p/6888357.html
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











