







任务: 增加重复件统计分析: 统计展示选择时间范围内重复1次、重复2次、重复3次、重复4次、重复5次及以上的数据量
17、统计出现的重复次数
增加重复件统计分析: 统计展示选择时间范围内重复1次、重复2次、重复3次、重复4次、重复5次及以上的数据量。
1,建表
DROP TABLE IF EXISTS repeat_num;
CREATE TABLE repeat_num(
id INT NOT NULL AUTO_INCREMENT,
create_date DATE,
content VARCHAR(500),
nums VARCHAR(500),
PRIMARY KEY(id)
);2,插入数据
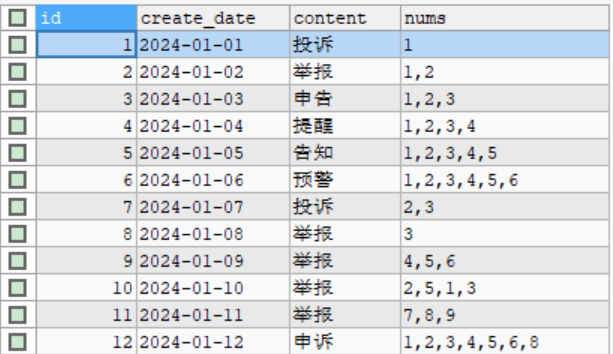
INSERT INTO repeat_num VALUES
(1, '2024-01-01', '投诉', '1'),
(2, '2024-01-02', '举报', '1,2'),
(3, '2024-01-03', '申告', '1,2,3'),
(4, '2024-01-04', '提醒', '1,2,3,4'),
(5, '2024-01-05', '告知', '1,2,3,4,5'),
(6, '2024-01-06', '预警', '1,2,3,4,5,6'),
(7, '2024-01-07', '投诉', '2,3'),
(8, '2024-01-08', '举报', '3'),
(9, '2024-01-09', '举报', '4,5,6'),
(10, '2024-01-10', '举报', '2,5,1,3'),
(11, '2024-01-11', '举报', '7,8,9'),
(12, '2024-01-12', '申诉', '1,2,3,4,5,6,8'),
(13, '2024-01-13', '申诉', '2,6'),
(14, '2024-01-14', '申诉', '1,3,4,5,6'),
(15, '2024-01-15', '申诉', '1,3,5,6,7,8,9'),
(16, '2024-01-16', '申诉', '5,7,8,9,10,11,13'),
(17, '2024-01-17', '申诉', '7,8,9,10'),
(18, '2024-01-18', '提醒', '7,8,9,10,14'),
(19, '2024-01-19', '告知', '5,7,8,9,10'),
(20, '2024-01-20', '告知', '4,5,6,7,8,9,11,12'),
(21, '2024-01-21', '预警', '3,5'),
(22, '2024-01-22', '预警', '8,9,11');3,sql
1,先结算长度:
-- 先计算原来的长度,然后用replace 替换到目标值,得到的长度,相减就是目标长度。 如果目标是多字符串的
SELECT LENGTH('1,2,3,4,5,6') -
LENGTH(REPLACE('1,2,3,4,5,6', ',', '')) AS count_commas;多字符间隔处理:
-- 多字符的,计算结果要除以自身长度
SELECT (LENGTH('best wish for you! best wish for you!') -
LENGTH( REPLACE ('best wish for you! best wish for you', 'for', '')))/
LENGTH('for') AS repeat_num;
-- 向下取整
SELECT FLOOR((LENGTH('best wish for you! best wish for you!') -
LENGTH( REPLACE ('best wish for you! best wish for you', 'for', '')))/
LENGTH('for')) AS repeat_num;2,计算重复次数:
SELECT *, (LENGTH(nums) - LENGTH(REPLACE(nums, ',', '')) + 1)
AS repeat_count
FROM repeat_num ;3,进行统计:
-- 统计:
SELECT repeat_count, SUM(repeat_count) repeat_sum
FROM (
SELECT *, (LENGTH(nums) - LENGTH(REPLACE(nums, ',', '')) + 1) AS repeat_count
FROM repeat_num
) AS temp GROUP BY repeat_count;4,统计以上的:
-- 统计 重复1次、重复2次、重复3次、重复4次、重复5次及以上
-- 以上的,又要聚合统计,得单独写
SELECT repeat_count, SUM(repeat_count) repeat_sum
FROM (
SELECT *, (LENGTH(nums) - LENGTH(REPLACE(nums, ',', '')) + 1) AS repeat_count
FROM repeat_num
) AS temp WHERE repeat_count <= 5
GROUP BY repeat_count
UNION
SELECT 6 AS repeat_count, SUM(repeat_count) repeat_sum
FROM (
SELECT *, (LENGTH(nums) - LENGTH(REPLACE(nums, ',', '')) + 1) AS repeat_count
FROM repeat_num
) AS temp WHERE repeat_count > 5;2,用函数的方式:
知识点:
SUBSTRING(s,n,len)带有len参数的格式,从字符串s返回一个长度同 len字符相同的子字符串,起始于位置n,也可能对n使用一个负值。假若这样,则子字符串的位置起始于字符串结尾的n字符,即倒数第n个字符,而不是字符串的开头位置。
【例 1】使用SUBSTRING函数获取指定位置处的子字符串,输入语句如下:
SELECT SUBSTRING('breakfast', 5) AS coll,
SUBSTRING('breakfast', 5,3) AS co12,
SUBSTRING('lunch', -3) AS co13,
SUBSTRING('lunch', -5, 3)AS col4;

SUBSTRING('breakfast',5)返回从第5个位置开始到字符串结尾的子字符串,结果为“kfast”; SUBSTRING(breakfast',5,3)返回从第5个位置开始长度为3的子字符串,结果为“kfa”;
SUBSTRING("unch',-3)返回从结尾开始第3个位置到字符串结尾的子字符串,结果为“nch”; SUBSTRING('lunch',-5,3)返回从结尾开始第5个位置,即字符串开头起,长度为3的子字符串,结果为“lun”。
用SUBSTRING去处理,不断去遍历,判断值符合条件的,就记录下。
函数:
DELIMITER //
CREATE FUNCTION count_by_symbols(str VARCHAR(255), symbol VARCHAR(10))
RETURNS INT
BEGIN
DECLARE cnt INT DEFAULT 0;
DECLARE idx INT DEFAULT 1;
DECLARE len INT;
SET len = CHAR_LENGTH(str);
WHILE idx <= len DO
IF SUBSTRING(str, idx, 1) = symbol THEN
SET cnt = cnt + 1;
END IF;
SET idx = idx + 1;
END WHILE;
RETURN cnt;
END //
DELIMITER ; 使用
SELECT count_by_symbols('a|lin|yan@sd|fd|ds|f', "|") AS count_symbol_num;如果新建函数保存
报错
This function has none of DETERMINISTIC, NO SQL, or READS SQL DATA in its declaration and binary logging is enabled (you *might* want to use the less safe log_bin_trust_function_creators variable)
SET GLOBAL log_bin_trust_function_creators = 1;调用:
SELECT *, (count_by_symbols(nums, ',') + 1) AS repeat_num
FROM repeat_num ;统计:
SELECT repeat_count, SUM(repeat_count) repeat_sum
FROM (
SELECT *, (count_by_symbols(nums, ',') + 1) AS repeat_count
FROM repeat_num
) AS temp WHERE repeat_count <= 5
GROUP BY repeat_count
UNION
SELECT 6 AS repeat_count, SUM(repeat_count) repeat_sum
FROM (
SELECT *, (count_by_symbols(nums, ',') + 1) AS repeat_count
FROM repeat_num
) AS temp WHERE repeat_count > 5;总结:
推荐用第一种方式,第二种,得看环境是否支持自定义函数或者过程。这种还好,如果要根据repeat_num去聚合的话,这种要聚合的话,这个要进行统计,就很麻烦了,用sql的话,得变成行转列,然后再进行统计。java的话,得把内容进行分离后,再重新聚合。
上一篇: 《mysql 日环比 统计》
下一篇: 《mysql 索引》















 451
451











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











