






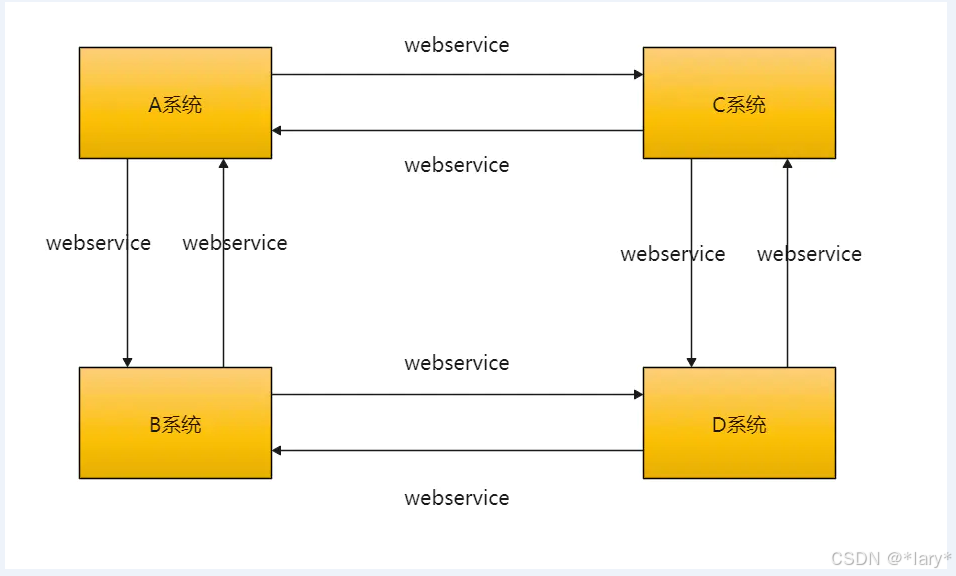
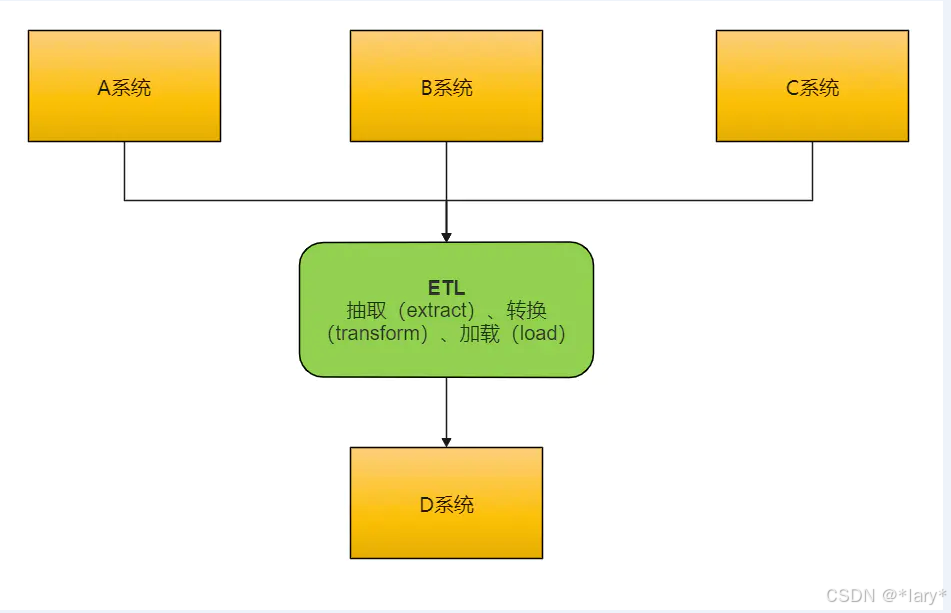
随着企业的发展,目前的业务线越来越复杂,各个业务系统独立运营。例如:CRM系统只会生产CRM的 数据;Billing只会生产Billing的数据。各业务系统之间只关心自己的数据,导致各业务系统之间数据相互独立,互不相通。一旦业务系统之间进行数据交互,只能通过传统的webservice接口之间进行数据通信。该种方式对人力成本、时间成本要求比较高。也就是说:需要成熟的开发人员才能编写响应的webservice接口进行数据通信。而ETL的诞生就解决了此类问题,企业不需要技术很好、很成熟的开发人员一样可以完成该任务。而且可以比优秀的开发人员完成的更好,致使人力成本更低。这些都是企业所迫切需要的,有此诞生了ETL。
传统的数据交互:
ETL数据交换:
简介:
-
什么是ETL:
https://baike.baidu.com/item/ETL/1251949?fr=aladdin
-
什么是kettle
https://baike.baidu.com/item/Kettle/592071
kettle是一款开源的ETL(Extract 抽取, Transform 转换, Load 载入)工具,由纯java编写,可以在Window、Linux、Unix上运行,绿色无需安装,数据抽取高效稳定。Kettle家族包括4个产品:Spoon,Pan,CHEF,Kitchen。
在数据仓库项目中,ETL工具的使用非常频繁。在以下的场景中通常可以应用到kettle:
1.数据清洗;
2.在不同应用或数据库之间整合数据;
3.把数据库中的数据导出到文本文件;
4.集成应用相关项目是个使用;
5.大批量数据载入数据库。
kettle的使用非常简单,通过图形界面设计实现做什么业务,无需写代码去实现,因此,kettle是以面向元数据来设计。
kettle支持多种输入和输出格式,包括文本文件、数据表,以及商业和免费的数据库引擎。另外,kettle强大的转换功能非常便于操纵数据。
kettle官网: https://community.hitachivantara.com/docs/DOC-1009855
准备工作
1.配置环境变量: 建议安装JDK1.8以上版本,kettle7.x以后版本不支持低版本JDK
2.下载kettle,解压到本地即可
3.下载相应的数据可驱动: 由于kettle需要连接数据库,因此需要下载对应的数据库驱动。
列如MySQL数据库需要下载mysql-connector-java.jar,如果是Oracle需要下载ojdbc.jar
下载完成后将jar放入kettle解压后路径的lib文件夹下即可.
4.启动
双击Spoon.bat就能启动,启动打开类似于以下这样的页面
kettle基本操作:
转换:
注释:转换包括一个或多个步骤,步骤之间通过跳(hop)来连接。跳定义了一个单向通道,允许数据从一个步骤流向另一个步骤。在Kettle中,数据的单位是行,数据流就是数据行从一个步骤到另一个步骤的移动。
1):表输入-表输出:
1,打开kettle,点击 文件->新建->转换,
在这里插入图片描述
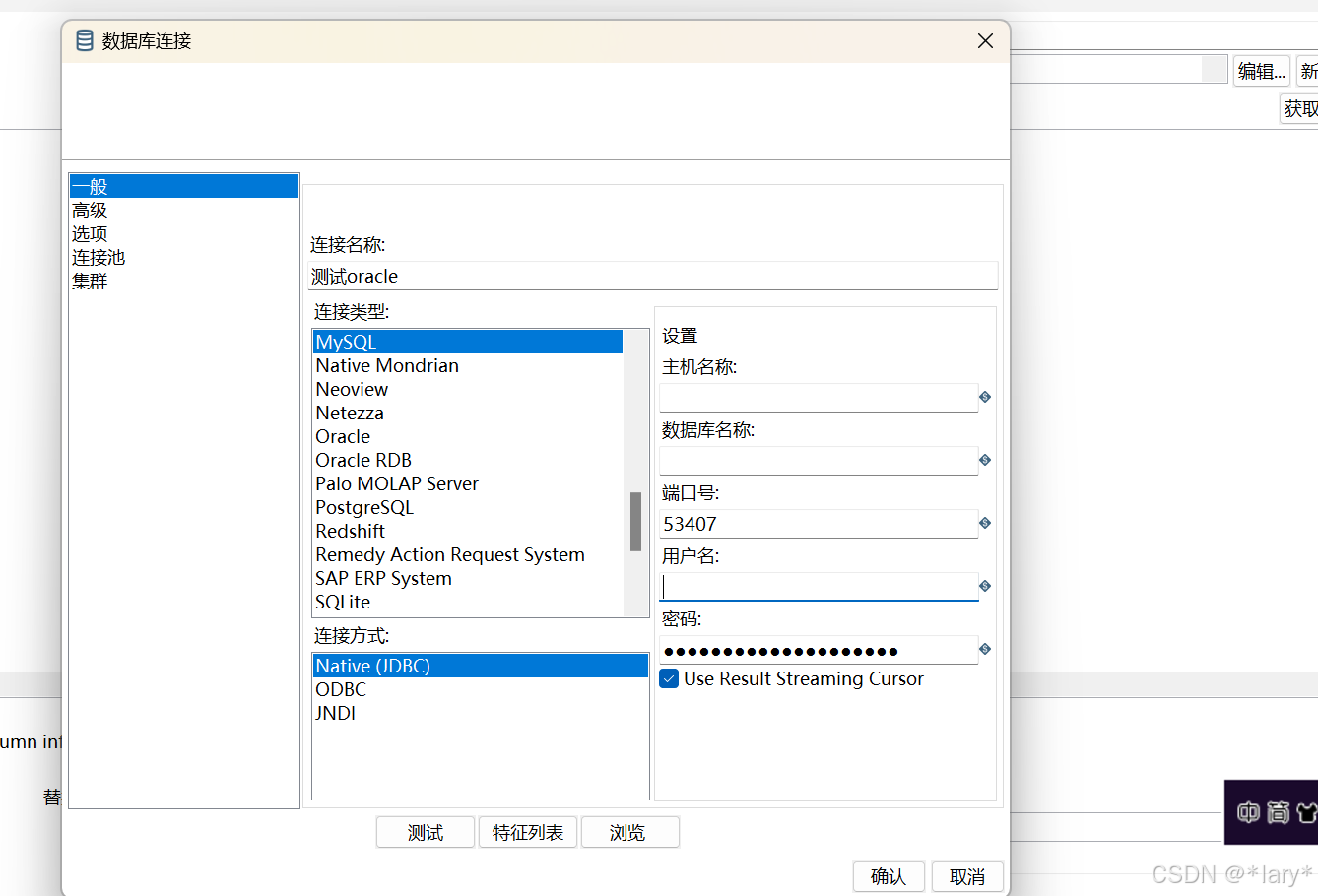
2,左边DB;连接处点击新建。
在这里插入图片描述
3:输入相关的数据库信息
1),表输入—插入/更新
在左侧找到表输入(核心对象->输入->表输入)双击
在这里插入图片描述
1:双击右侧表输入,进行配置,选择数据源,并输入SQL。可以点击预览进行他预览数据。
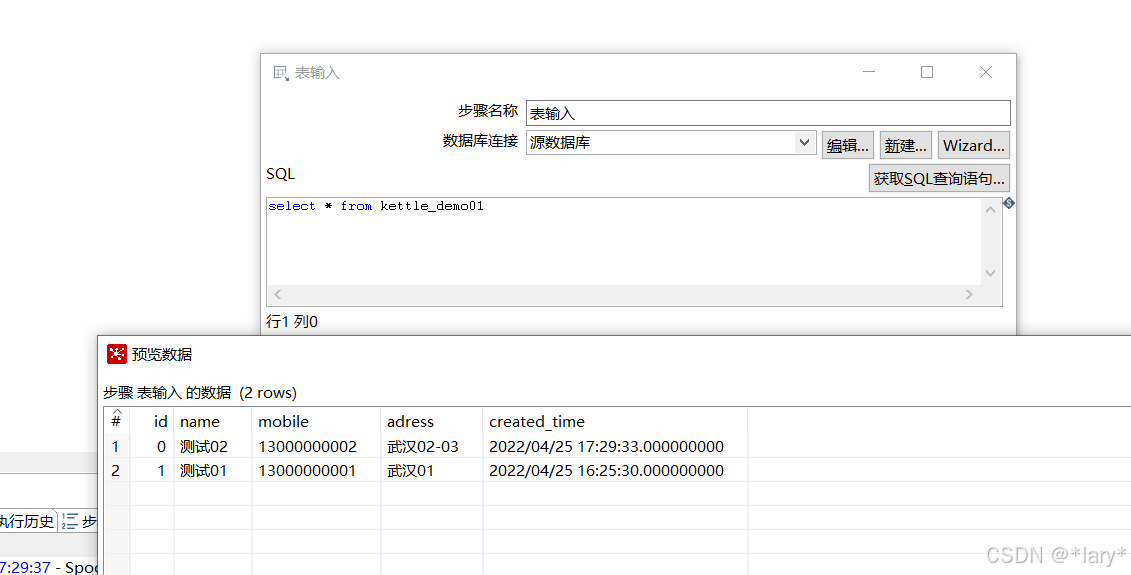
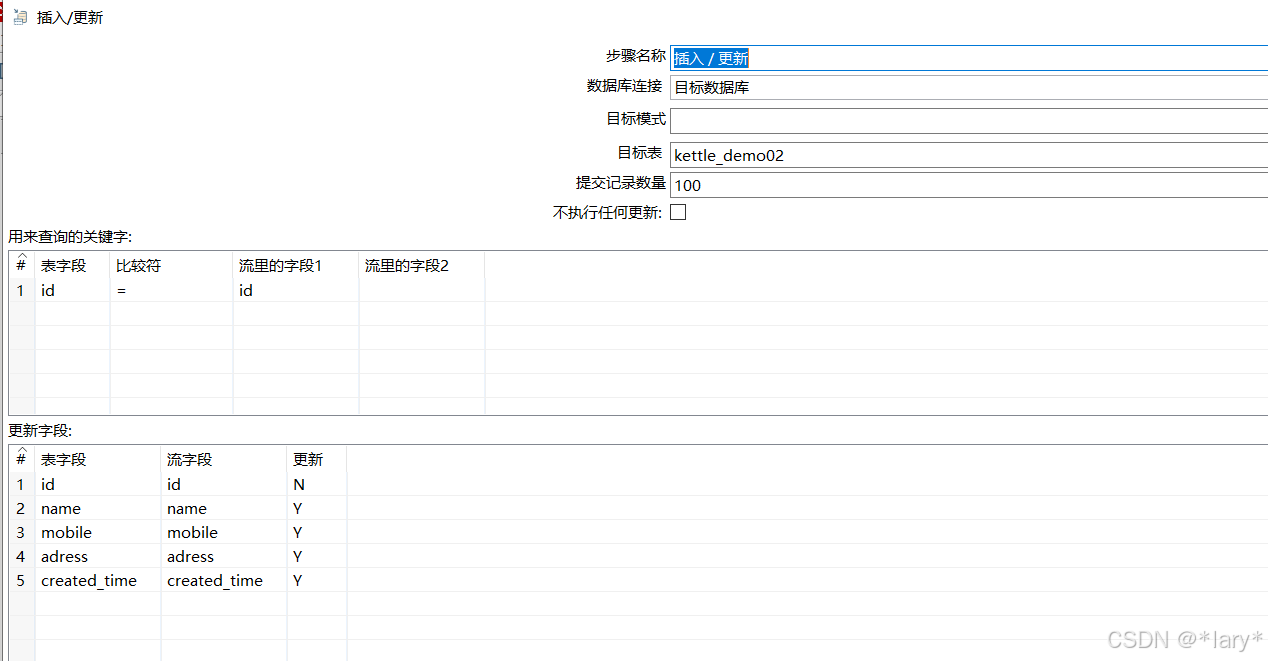
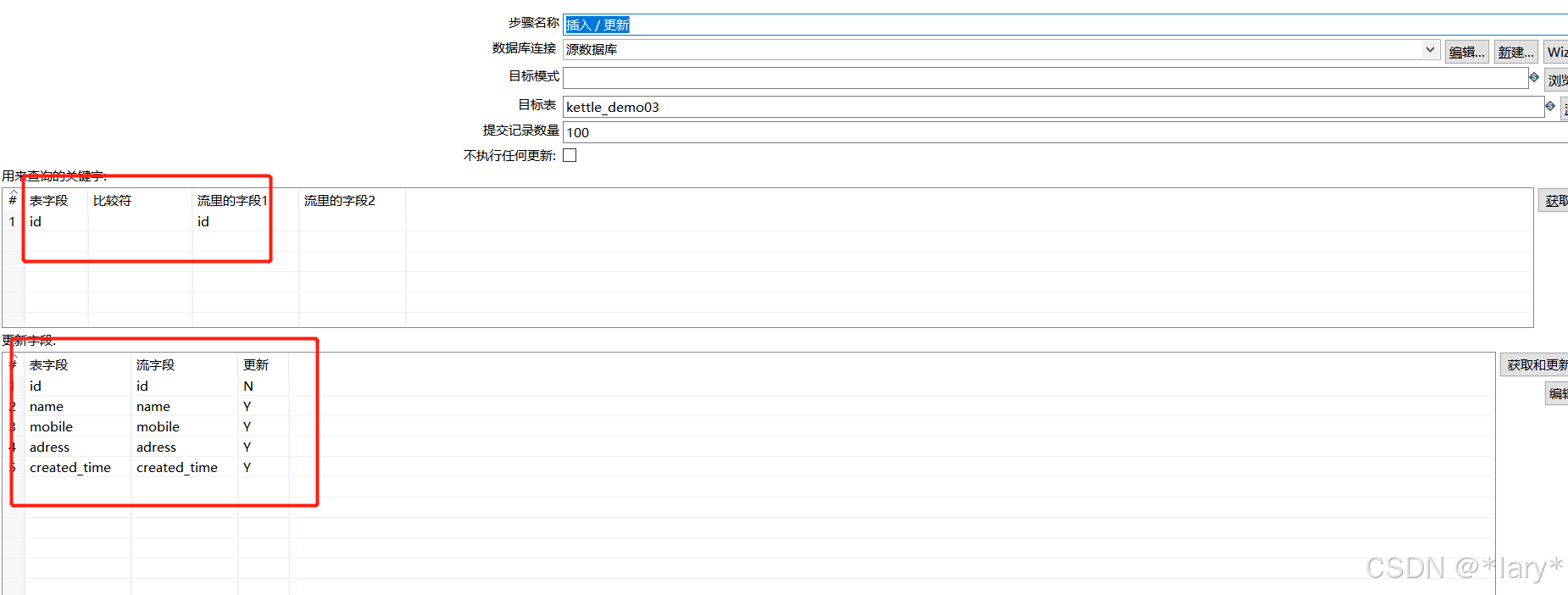
2, 在左侧找到插入/更新(核心对象->输出->插入/更新),双击
在这里插入图片描述
插入和更新的相关配置如下
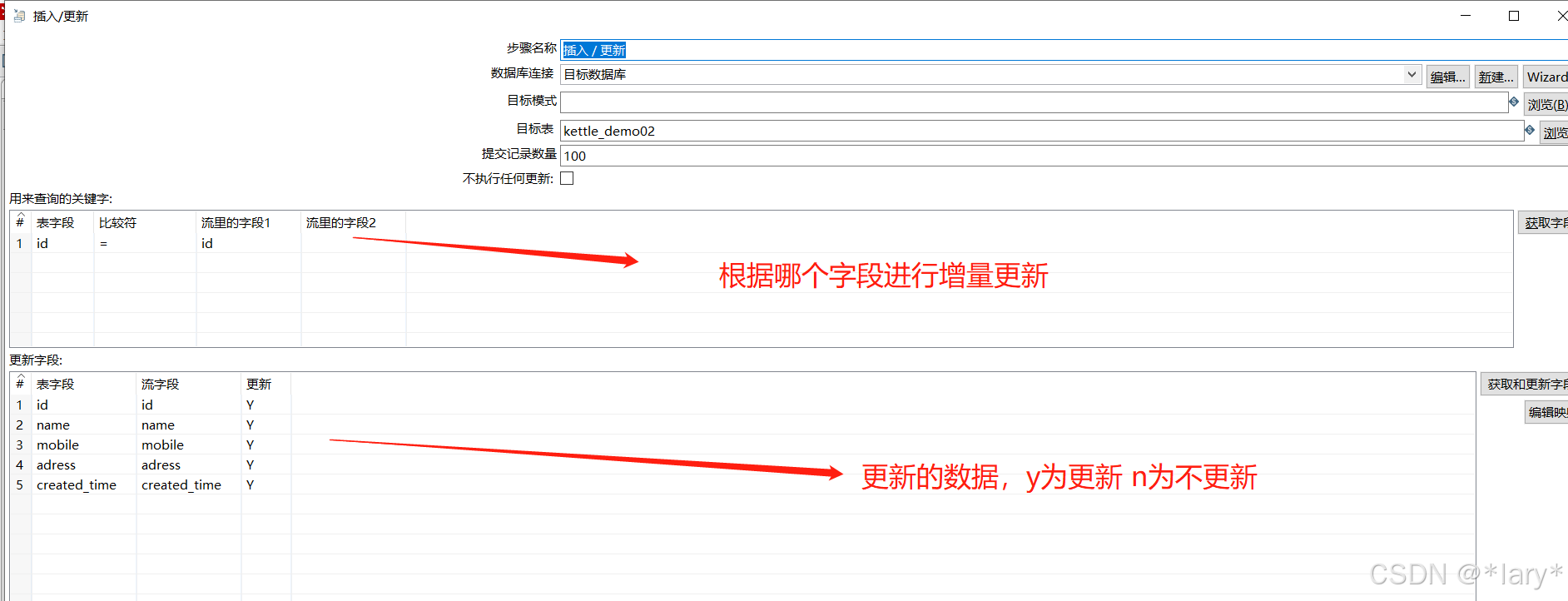
3,Shift键,把表输入和插入/更新用线连接起来。
4:根据参数增量更新
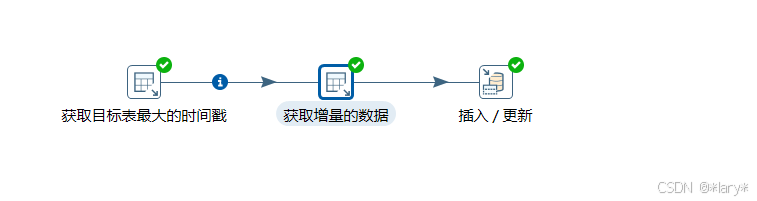
5:获取目标表的最后的更新时间

6:获取增量的数据
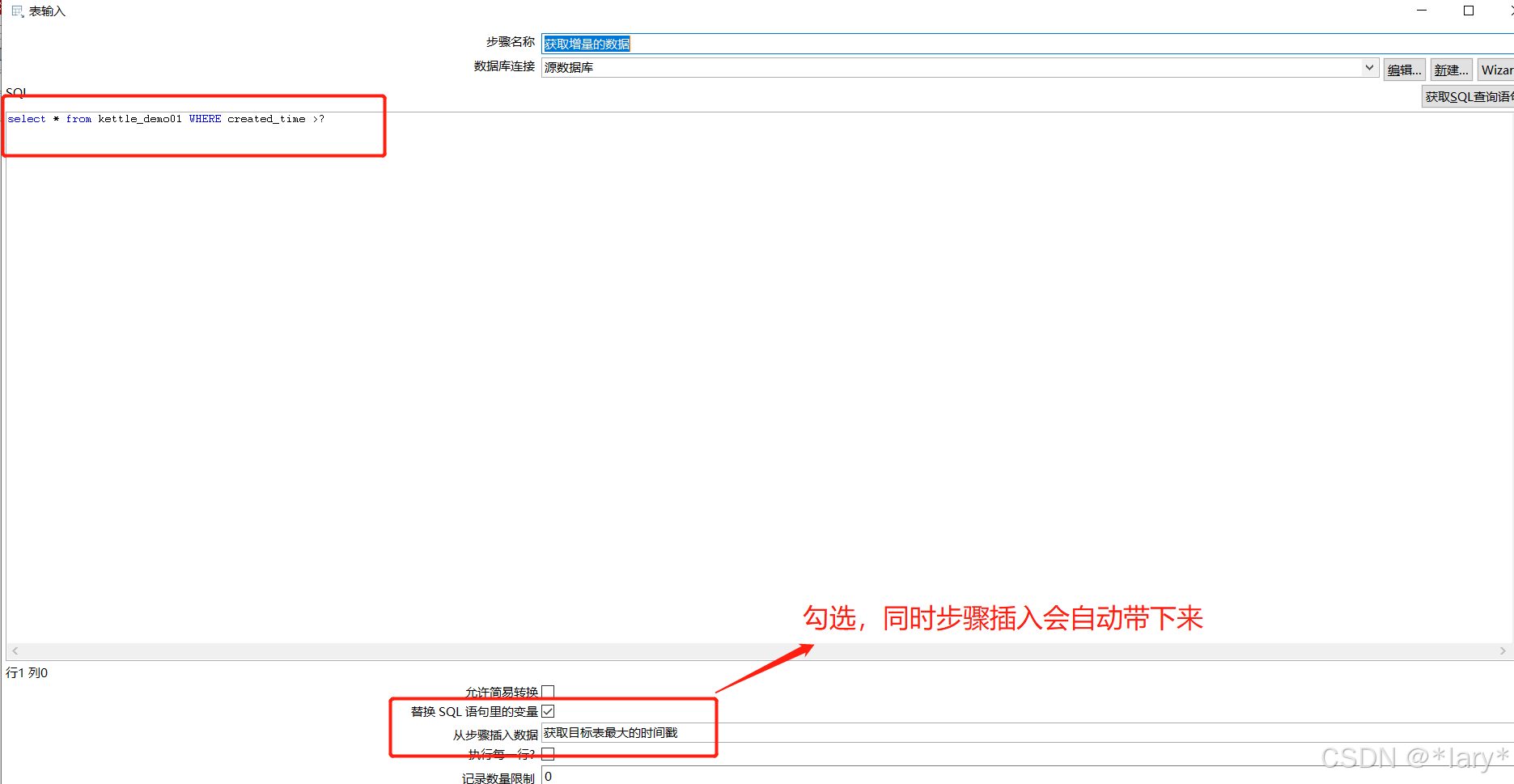
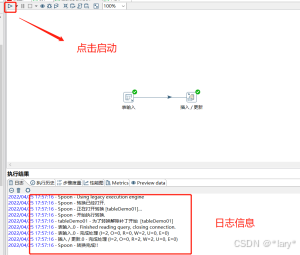
7:插入更新目标表的数据
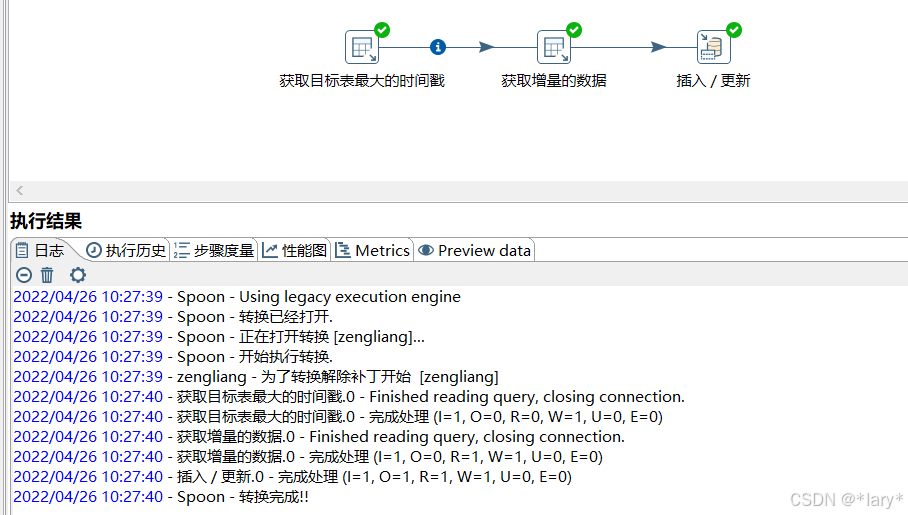
8:点击执行查询日志
2)文本文件输入-插入/更新
1:在左边的目录下选择文本文件输入
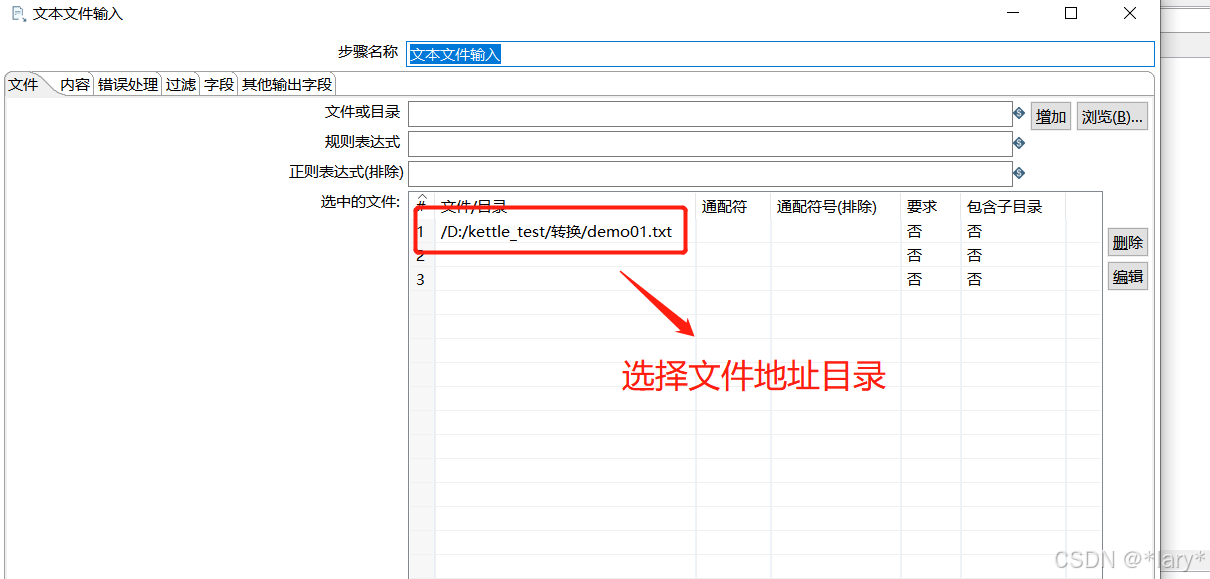
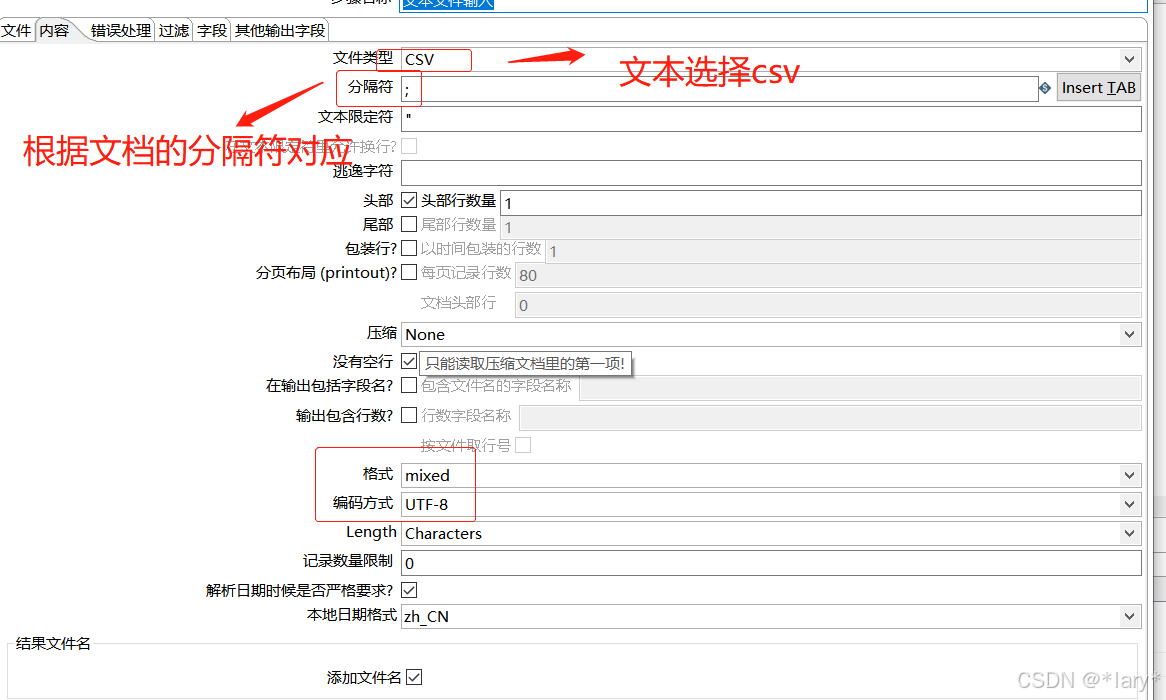
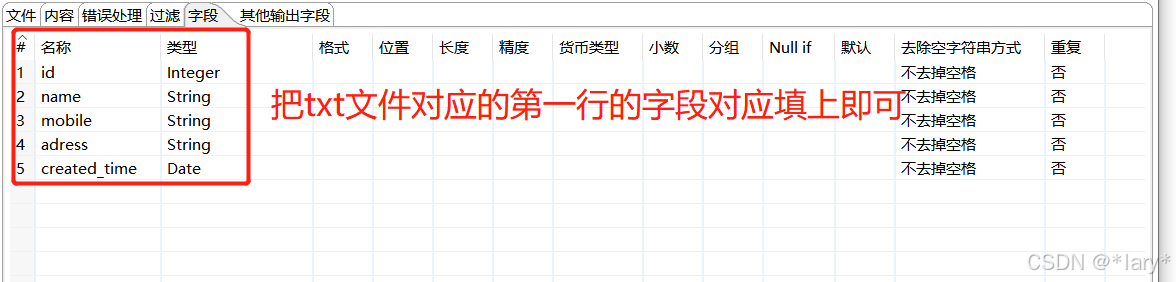
点击预览,即可预览到对应的数据,如下图所示
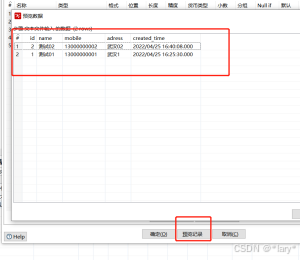
2:在左边目录下选择表输入/更新
3:查询日志和数据库看是否插入成功
百万数据转换:如图所示,使用默认的转换,表输入—插入/更新

根据上面的步骤度量可以看出,16000条数据插入6700需5分钟,则百万至少几个小时:
优化:
思路:采用线程池,调大运行内存,采用表输出,采用多线程,再进行插入更新
1:
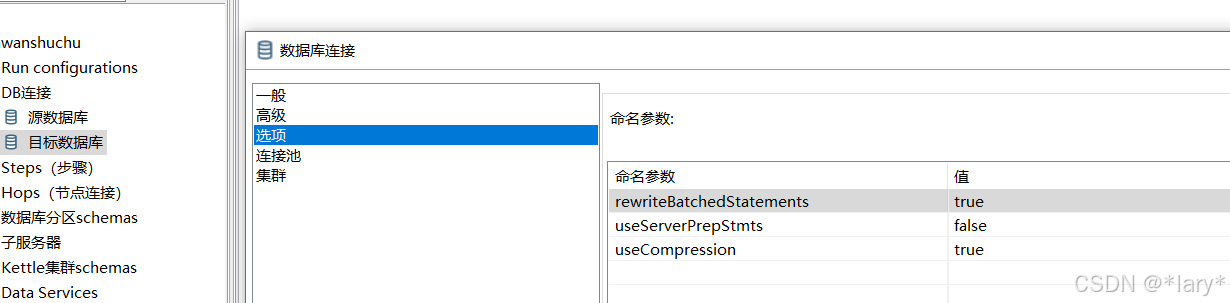
在配置的数据源是目标数据源时为了提高效率应在编辑界面添加三个选项,插入效率可以提升十倍左右
rewriteBatchedStatements |TRUE |
useServerPrepStmts | FALSE|
useCompression | TRUE |
MySql 的批量操作,要加rewriteBatchedStatements参数批量操作
useCompression :与服务器进行通信时采用zlib压缩(真/假)? 默认值为“假”。
useServerPrepStmts:如果服务器支持,是否使用服务器端预处理语句? 默认值为“真”。
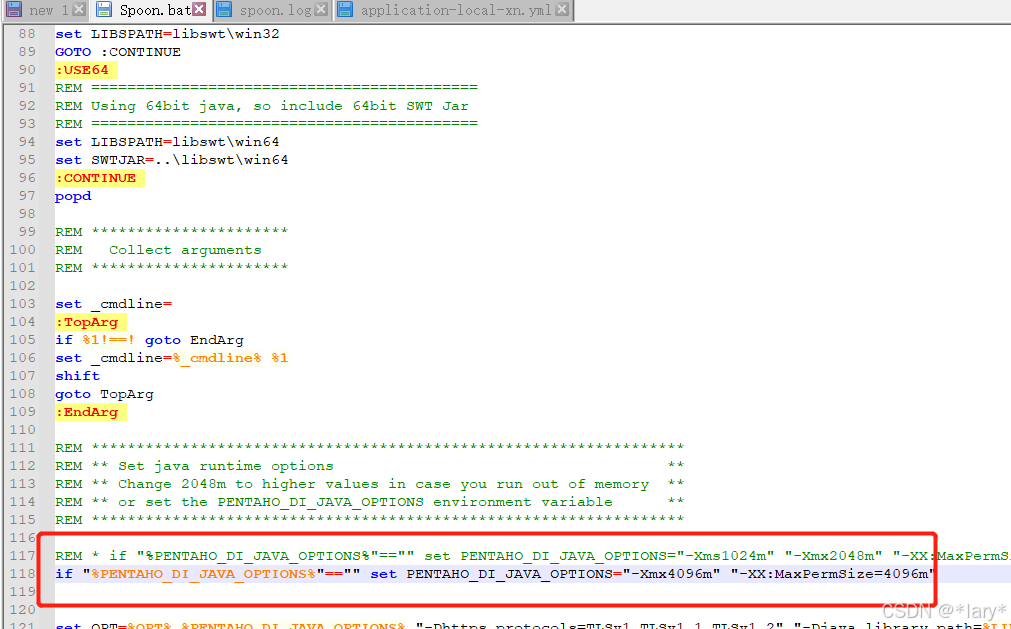
2:调整spoon.bat 将运行内存等调大:
3:将提交记录设置为10000
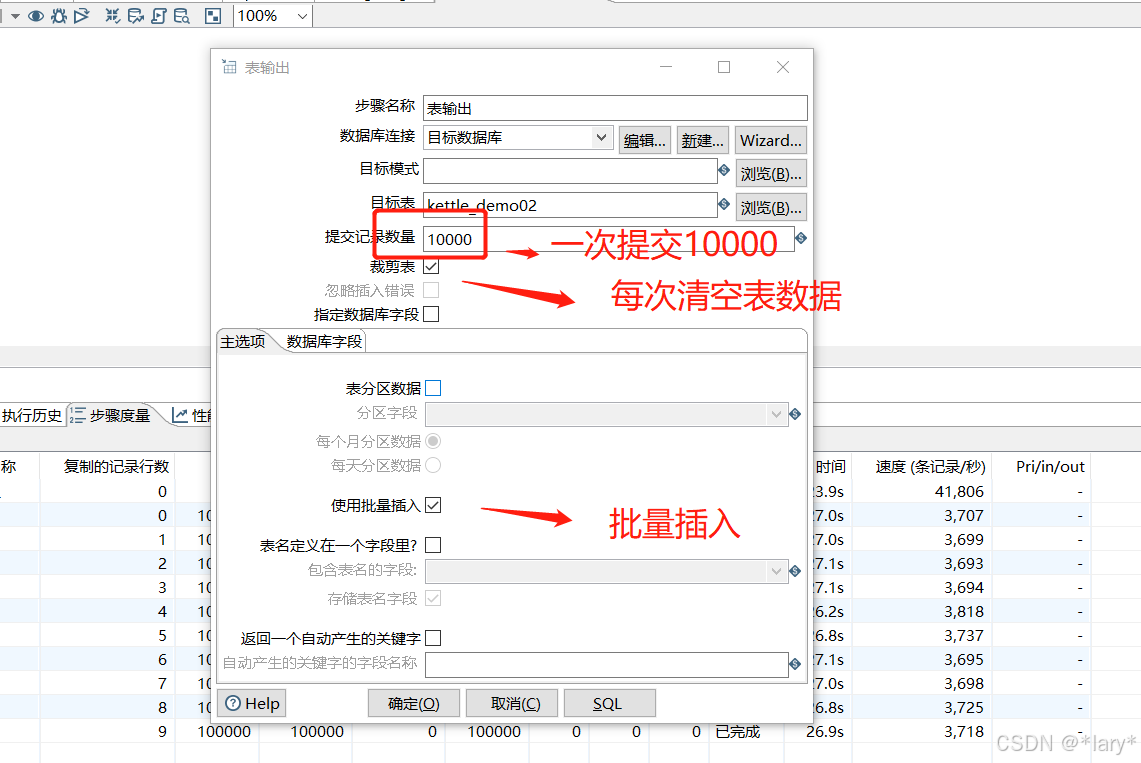
4:采用表输出的方式并且使用多线程如下图:
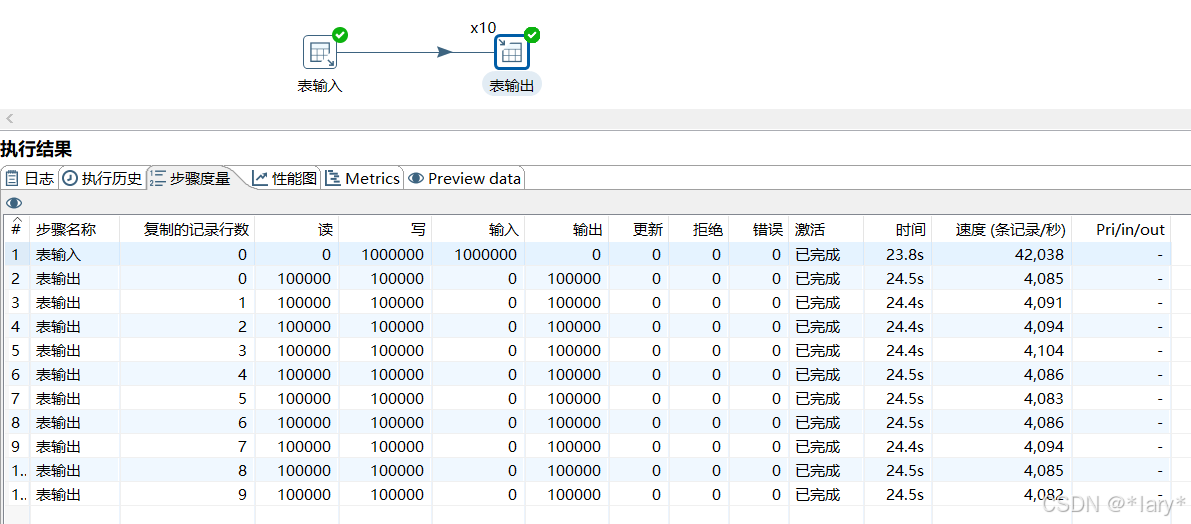
总结:根据上图可以看出,插入100万的数据只需24秒
1000条数据插入的更新只需8秒

作业:
注释:如果想要定时运行这个转换,那么就要用到作业。
如果想要定时运行这个转换,就用作业
1, 新建一个作业
在这里插入图片描述
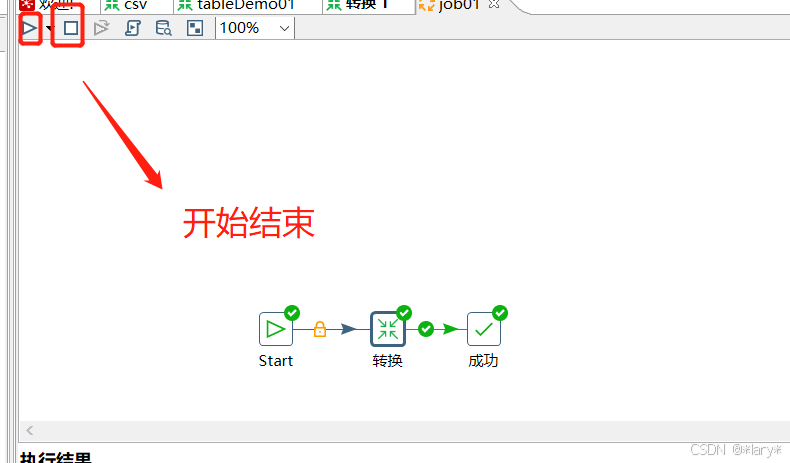
2, 从左侧一次拖动start,转换,成功到右侧,并用线连接起来
在这里插入图片描述
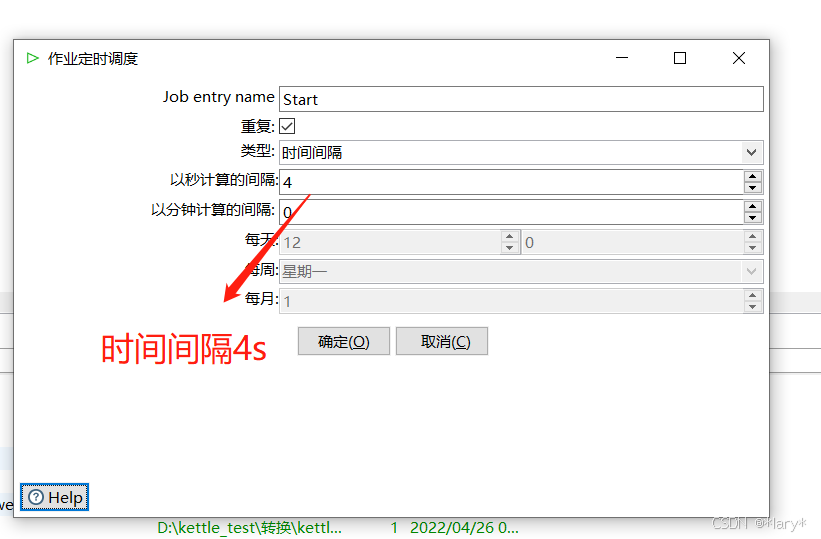
3, 双击start,可以配置作业的运行间隔,这边配置了4s运行一次
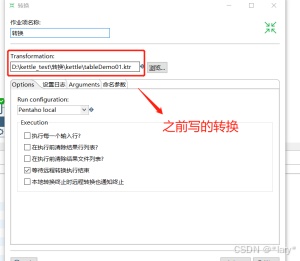
4, 双击转换,选择之前的新建的那个转换
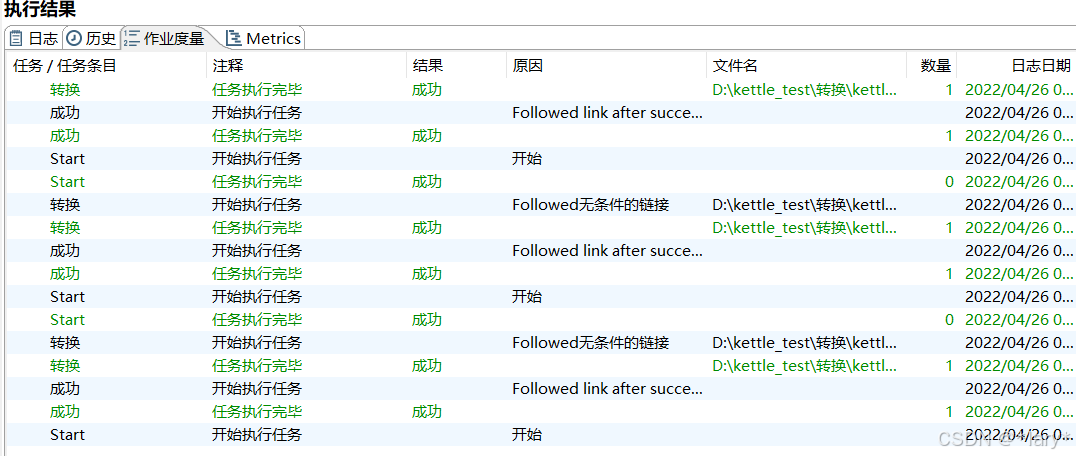
5,点击运行,就能运行这次作业,点击停止就能停止。在下方执
行结果,可以看到到运行的日志
6:保存到服务器:
坑点:connect 有时会消失,导致原因的
https://blog.csdn.net/weixin_40159138/article/details/101286615

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









