






什么是Hive?
- Hive是在Hadoop分布式文件系统上运行的开源分布式数据仓库数据库,用于查询和分析大数据。
- 数据以表格的形式存储(与关系型数据库十分相似)。数据操作可以使用名为HiveQL的SQL接口来执行。
- HiveQL默认情况下会转换成MapReduce进行计算(降低了开发难度),所以比较慢,常用于做离线数据分析场景,不适合做实时查询。
为什么选择Hive?
- Hive是运行在Hadoop上的SQL接口。此外,它还降低了使用MapReduce框架编程的复杂性。
- Hive帮助企业在HDFS上执行大规模数据分析,使其成为一个水平可伸缩的数据库。
- 通过HiveSQL使具有RDBMS背景的开发人员能够快速构建符合自己业务需求的数据仓库。
- Hive直接将数据存储在HDFS系统中,扩容等事宜都交由HDFS系统来维护。
如何将Hive中的分析数据导到业务系统中?
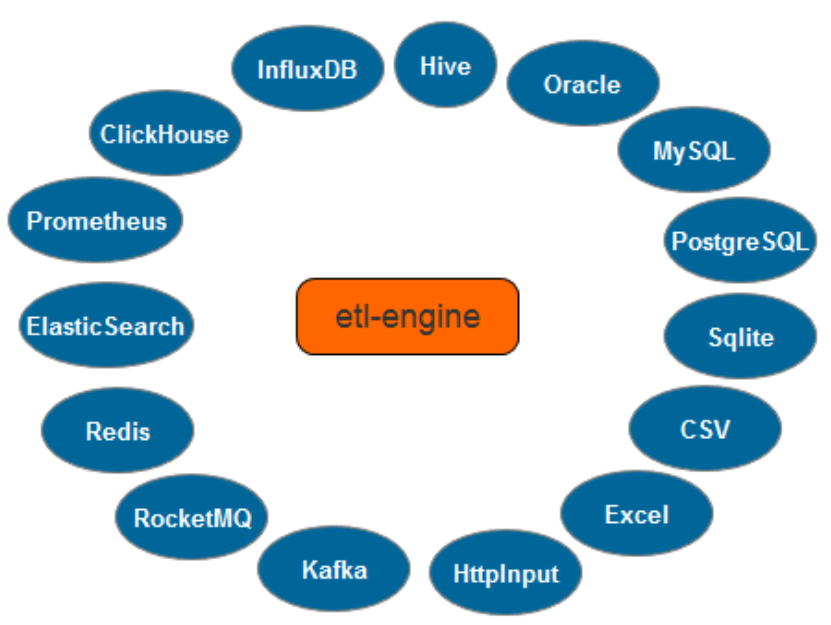
etl-engine支持对Hive的读取,并输出到以下目标数据源:
- 消息中间件(Kafka | RocketMQ);
- 关系型数据库( Oracle | MySQL | PostgreSQL | Sqlite | SQLServer);
- NoSQL(Elasticsearch | Redis);
- 时序数据库( InfluxDB | ClickHouse | Prometheus);
- 文件( Excel );
etl-engine支持None和Kerberos认证方式,适合测试环境及企业应用生产环境中的认证场景。
只需要二步 就完成 读Hive写DB操作
编写配置文件 hive_to_db.grf
执行命令
如此简单就完成了 读 hive 数据表 、写 mysql 数据表 操作。
















 569
569

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











