






在 Kubernetes 生态系统中,持久化存储是支撑业务应用稳定运行的基石,对于维护整个系统的健壮性至关重要。对于选择自主搭建 Kubernetes 集群的运维架构师来说,挑选合适的后端持久化存储解决方案是关键的选型决策。目前,Ceph、GlusterFS、NFS、Longhorn 和 openEBS 等解决方案已在业界得到广泛应用。
为了丰富技术栈,并为容器云平台的持久化存储设计提供更广泛的灵活性和选择性,今天,我将带领大家一起探索,如何将 Ceph 集成到由 KubeSphere 管理的 Kubernetes 集群中。
集成 Ceph 至 Kubernetes 集群主要有两种方案:
- 利用 Rook Ceph 直接在 Kubernetes 集群上部署 Ceph 集群,这种方式更贴近云原生的应用特性。
- 手动部署独立的 Ceph 集群,并配置 Kubernetes 集群与之对接,实现存储服务的集成。
本文将重点实战演示使用 Rook Ceph 在 Kubernetes 集群上直接部署 Ceph 集群的方法,让您体验到云原生环境下 Ceph 部署的便捷与强大。
实战服务器配置(架构 1:1 复刻小规模生产环境,配置略有不同)
主机名 | IP | CPU | 内存 | 系统盘 | 数据盘 | 用途 |
ksp-registry | 192.168.9.90 | 4 | 8 | 40 | 200 | Harbor 镜像仓库 |
ksp-control-1 | 192.168.9.91 | 4 | 8 | 40 | 100 | KubeSphere/k8s-control-plane |
ksp-control-2 | 192.168.9.92 | 4 | 8 | 40 | 100 | KubeSphere/k8s-control-plane |
ksp-control-3 | 192.168.9.93 | 4 | 8 | 40 | 100 | KubeSphere/k8s-control-plane |
ksp-worker-1 | 192.168.9.94 | 4 | 16 | 40 | 100 | k8s-worker/CI |
ksp-worker-2 | 192.168.9.95 | 4 | 16 | 40 | 100 | k8s-worker |
ksp-worker-3 | 192.168.9.96 | 4 | 16 | 40 | 100 | k8s-worker |
ksp-storage-1 | 192.168.9.97 | 4 | 8 | 40 | 400+ | Containerd、OpenEBS、ElasticSearch/Longhorn/Ceph/NFS |
ksp-storage-2 | 192.168.9.98 | 4 | 8 | 40 | 300+ | Containerd、OpenEBS、ElasticSearch/Longhorn/Ceph |
ksp-storage-3 | 192.168.9.99 | 4 | 8 | 40 | 300+ | Containerd、OpenEBS、ElasticSearch/Longhorn/Ceph |
ksp-gpu-worker-1 | 192.168.9.101 | 4 | 16 | 40 | 100 | k8s-worker(GPU NVIDIA Tesla M40 24G) |
ksp-gpu-worker-2 | 192.168.9.102 | 4 | 16 | 40 | 100 | k8s-worker(GPU NVIDIA Tesla P100 16G) |
ksp-gateway-1 | 192.168.9.103 | 2 | 4 | 40 | 自建应用服务代理网关/VIP:192.168.9.100 | |
ksp-gateway-2 | 192.168.9.104 | 2 | 4 | 40 | 自建应用服务代理网关/VIP:192.168.9.100 | |
ksp-mid | 192.168.9.105 | 4 | 8 | 40 | 100 | 部署在 k8s 集群之外的服务节点(Gitlab 等) |
合计 | 15 | 56 | 152 | 600 | 2100+ |
实战环境涉及软件版本信息
- 操作系统:openEuler 22.03 LTS SP3 x86_64
- KubeSphere:v3.4.1
- Kubernetes:v1.28.8
- KubeKey: v3.1.1
- Containerd:1.7.13
- Rook:v1.14.9
- Ceph: v18.2.4
1. Rook 部署规划
为了更好地满足生产环境的实际需求,在规划和部署存储基础设施时,我增加了以下策略:
- 节点扩展:向 Kubernetes 集群中新增三个专用节点,这些节点将专门承载 Ceph 存储服务,确保存储操作的高效性和稳定性。
- 组件隔离:所有 Rook 和 Ceph 组件以及数据卷将被部署在这些专属节点上,实现组件的清晰隔离和专业化管理。
- 节点标签化:为每个存储节点设置了专门的标签
node.kubernetes.io/storage=rook,以便 Kubernetes 能够智能地调度相关资源。同时,非存储节点将被标记为node.rook.io/rook-csi=true,这表明它们将承载 Ceph CSI 插件,使得运行在这些节点上的业务 Pod 能够利用 Ceph 提供的持久化存储。 - 存储介质配置:在每个存储节点上,我将新增一块 100G 的 Ceph 专用数据盘
/dev/sdd。为保证最佳性能,该磁盘将采用裸设备形态直接供 Ceph OSD 使用,无需进行分区或格式化。
重要提示:
- 本文提供的配置和部署经验对于理解 Rook-Ceph 的安装和运行机制具有参考价值。然而,强烈建议不要将本文描述的配置直接应用于任何形式的生产环境。
- 在生产环境中,还需进一步考虑使用 SSD、NVMe 磁盘等高性能存储介质;细致规划故障域;制定详尽的存储节点策略;以及进行细致的系统优化配置等。
2. 前置条件
2.1 Kubernetes 版本
- Rook 可以安装在任何现有的 Kubernetes 集群上,只要它满足最低版本,并且授予 Rook 所需的特权
- 早期 v1.9.7 版本的 Rook 支持 Kubernetes v1.17 或更高版本
- 现在的 v1.14.9 版本支持 Kubernetes v1.25 到 v1.30 版本(可能支持更低的版本,可以自己验证测试)
2.2 CPU Architecture
支持的 CPU 架构包括: amd64 / x86_64 and arm64。
2.3 Ceph 先决条件
为了配置 Ceph 存储集群,至少需要以下任意一种类型的本地存储:
- Raw devices (no partitions or formatted filesystems,没有分区和格式化文件系统,本文选择)
- Raw partitions (no formatted filesystem,已分区但是没有格式化文件系统)
- LVM Logical Volumes (no formatted filesystem)
- PVs available from a storage class in
blockmode
使用以下命令确认分区或设备是否使用文件系统并进行了格式化:
- 如果 FSTYPE 字段不为空,说明该设备已经格式化为文件系统,对应的值就是文件系统类型
- 如果 FSTYPE 字段为空,说明该设备还没有被格式化,可以被 Ceph 使用
- 本例中可以使用的设备为 sdd
如果需要清理已有磁盘给 Ceph 使用,请使用下面的命令(生产环境请谨慎):
2.4 LVM 需求
Ceph OSDs 在以下场景依赖 LVM。
- If encryption is enabled (
encryptedDevice: "true"in the cluster CR) - A
metadatadevice is specified osdsPerDeviceis greater than 1
Ceph OSDs 在以下场景不需要 LVM。
- OSDs are created on raw devices or partitions
- Creating OSDs on PVCs using the
storageClassDeviceSets
openEuler 默认已经安装 lvm2,如果没有装,使用下面的命令安装。
2.5 Kernel 需求
- RBD 需求
Ceph 需要使用构建了 RBD 模块的 Linux 内核。许多 Linux 发行版都有这个模块,但不是所有发行版都有。例如,GKE Container-Optimised OS (COS) 就没有 RBD。
在 Kubernetes 节点使用 lsmod | grep rbd 命令验证,如果没有任何输出,请执行下面的命令加载 rbd 模块。
- CephFS 需求
如果您将从 Ceph shared file system (CephFS) 创建卷,推荐的最低内核版本是 4.17。如果内核版本小于 4.17,则不会强制执行请求的 PVC sizes。存储配额只会在更新的内核上执行。
注意: openEuler 22.03 SP3 目前最新的内核为 5.10.0-218.0.0.121,虽然大于 4.17 但是有些过于高了,在安装 Ceph CSI Plugin 的时候可能会遇到 CSI 驱动无法注册的问题。
3. 扩容集群节点
3.1 扩容存储专用 Worker 节点
将新增的三台存储专用节点加入已有的 Kubernetes 集群,详细的扩容操作请参考 KubeKey 扩容 Kubernetes Worker 节点实战指南。
3.2 设置节点标签
按规划给三个存储节点和其它 Worker 节点打上专属标签。
- 存储节点标签
- Worker 节点标签
- 控制(Control)节点
不做任何设置,Ceph 的服务组件和 CSI 插件都不会安装在控制节点。网上也有人建议把 Ceph 的管理组件部署在 K8s 的控制节点,我是不赞同的。个人建议把 Ceph 的所有组件独立部署。
4. 安装配置 Rook Ceph Operator
4.1 下载部署代码
4.2 修改镜像地址
可选配置,当 DockerHub 访问受限时,可以将 Rook-Ceph 需要的镜像离线下载到本地仓库,部署时修改镜像地址。
注意:上面的镜像仓库是我内部离线仓库,参考我文档的读者不要直接照抄,一定要换成自己的镜像仓库。
4.3 修改自定义配置
修改配置文件 operator.yaml 实现以下需求:
- rook-ceph 所有管理组件部署在指定标签节点
- k8s 其他节点安装 Ceph CSI Plugin
4.4 部署 Rook Operator
- 部署 Rook operator
- 验证
rook-ceph-operatorPod 的状态是否为Running
执行成功后,输出结果如下:
4.5 KubeSphere 控制台查看 Operator 资源
登录 KubeSphere 控制台查看创建的 Rook Ceph Operator Deployment 资源。
5. 创建 Ceph 集群
5.1 修改集群配置文件
- 修改集群配置文件
cluster.yaml,增加节点亲和配置
- 修改集群配置文件
cluster.yaml,增加存储节点和 OSD 磁盘配置
5.2 创建 Ceph 集群
- 创建集群
- 查看资源状态,确保所有相关 Pod 均为
Running
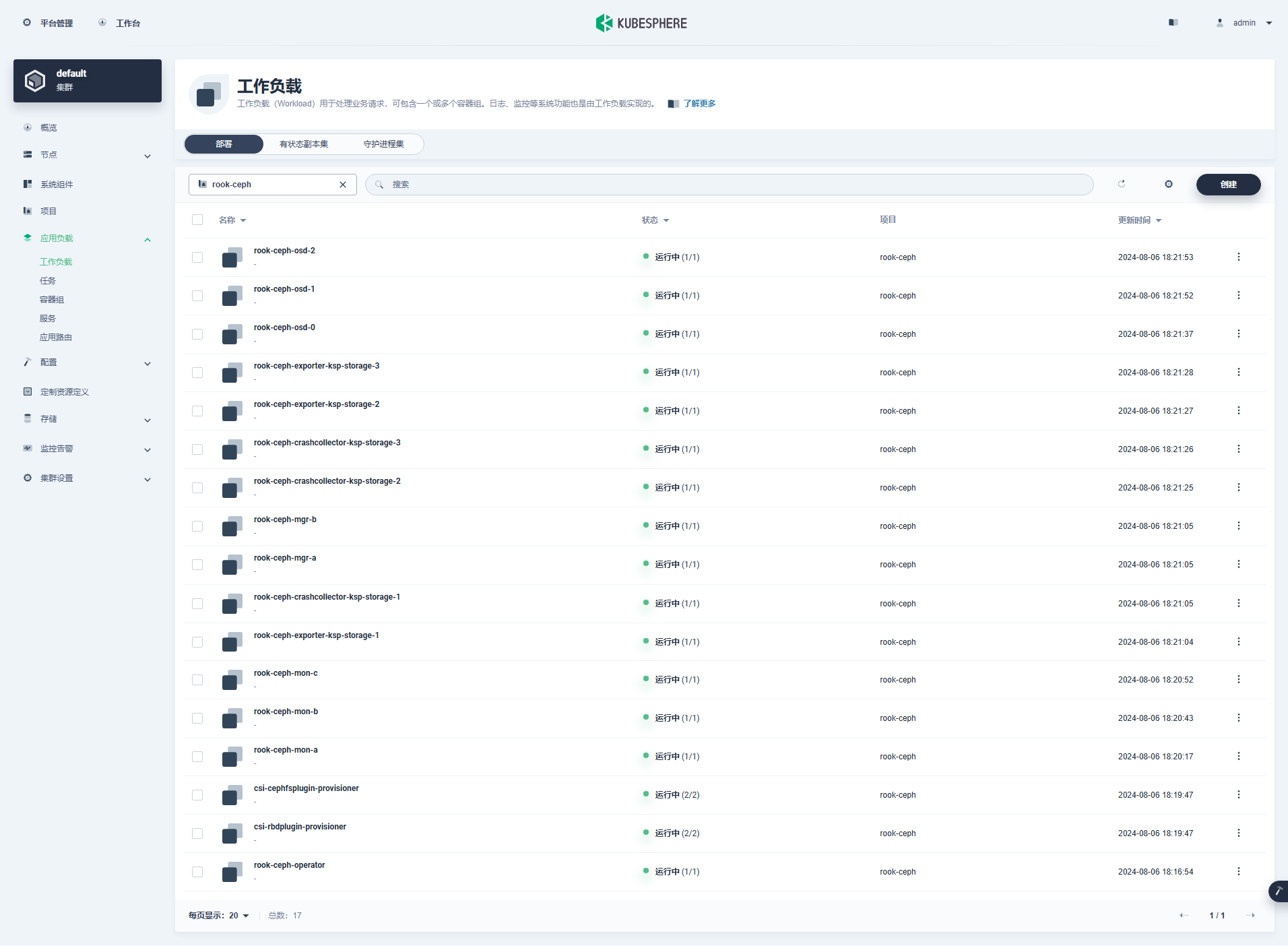
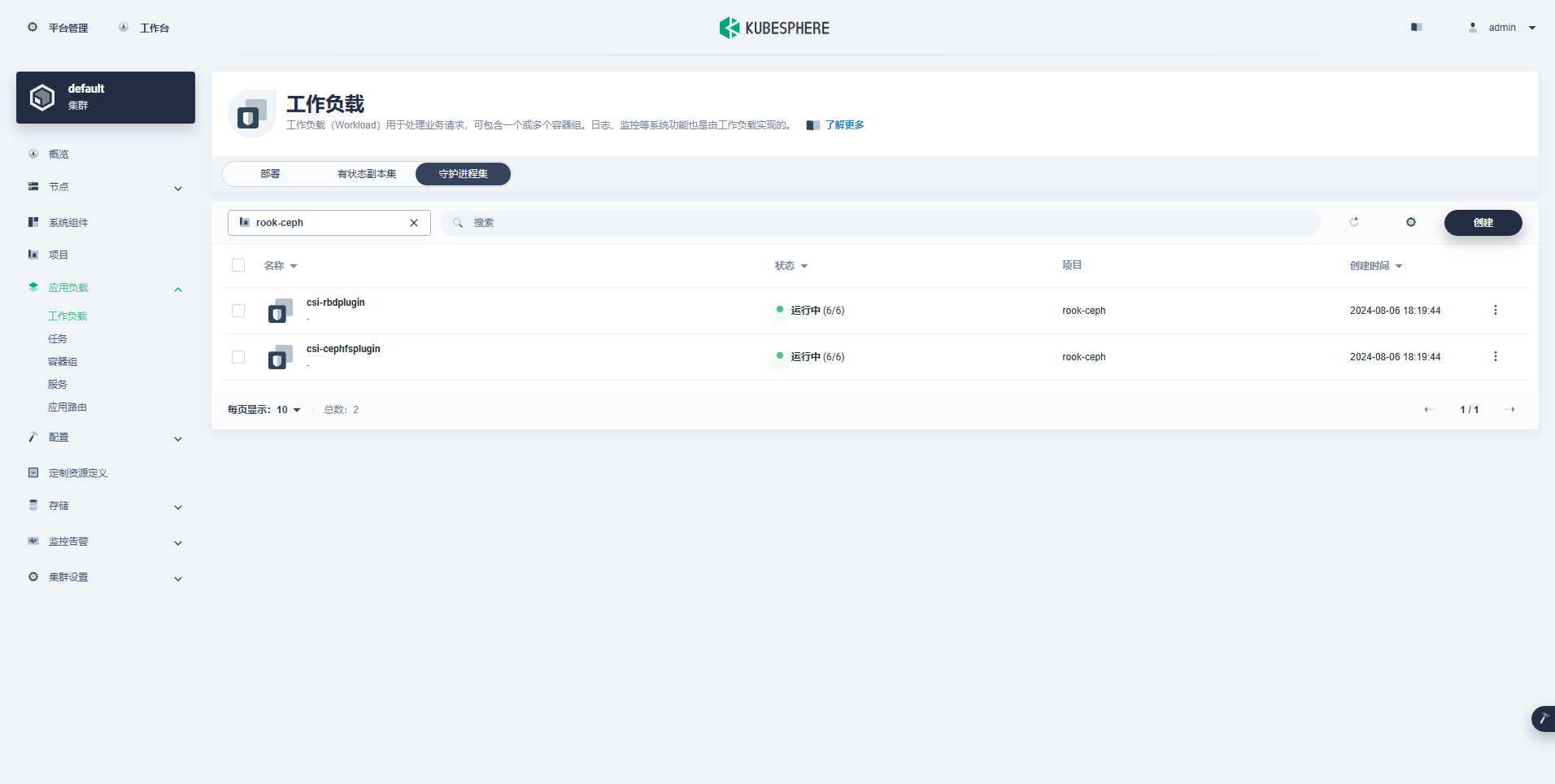
5.3 KubeSphere 控制台查看 Ceph 集群资源
- Deployment(部署,17个)
- Daemonsets(守护进程集,2个)
6. 创建 Rook toolbox
通过 Rook 提供的 toolbox,我们可以实现对 Ceph 集群的管理。
6.1 创建 toolbox
- 创建 toolbox
- 等待 toolbox pod 下载容器镜像,并进入 Running 状态:
6.2 常用命令
- 登录 Toolbox
- 验证 Ceph 集群状态
观察 Ceph 集群状态,需要满足下面的条件才会认为集群状态是健康的。
- health 的值为 HEALTH_OK
- Mons 的数量和状态
- Mgr 一个 active,一个 standbys
- OSD 3 个,状态都是 up
- 其他常用的 Ceph 命令
- 删除 toolbox(可选)
7. Block Storage
7.1 Storage 介绍
Rock Ceph 提供了三种存储类型,请参考官方指南了解详情:
- Block Storage(RBD): Create block storage to be consumed by a pod (RWO)
- Filesystem Storage(CephFS): Create a filesystem to be shared across multiple pods (RWX)
- Object Storage(RGW): Create an object store that is accessible inside or outside the Kubernetes cluster
本文使用比较稳定、可靠的 Block Storage(RBD)的方式作为 Kubernetes 的持久化存储。
7.2 创建存储池
Rook 允许通过自定义资源定义 (crd) 创建和自定义 Block 存储池。支持 Replicated 和 Erasure Coded 类型。本文演示 Replicated 的创建过程。
- 创建一个 3 副本的 Ceph 块存储池,编辑
CephBlockPoolCR 资源清单,vi ceph-replicapool.yaml
- 创建 CephBlockPool 资源
- 查看资源创建情况
- 在 ceph toolbox 中查看 Ceph 集群状态
7.3 创建 StorageClass
- 编辑 StorageClass 资源清单,
vi storageclass-rook-ceph-block.yaml
- 创建 StorageClass 资源
注意: examples/csi/rbd 目录中有更多的参考用例。
- 验证资源
8. 创建测试应用
8.1 使用 Rook 提供的测试案例
我们使用 Rook 官方提供的经典的 Wordpress 和 MySQL 应用程序创建一个使用 Rook 提供块存储的示例应用程序,这两个应用程序都使用由 Rook 提供的块存储卷。
- 创建 MySQL 和 Wordpress
- 查看 PVC 资源
- 查看 SVC 资源
- 查看 Pod 资源
8.2 指定节点创建测试应用
Wordpress 和 MySQL 测试用例中,pod 创建在了存储专用节点。为了测试集群中其它 Worker 节点是否可以使用 Ceph 存储,我们再做一个测试,在创建 Pod 时指定 nodeSelector 标签,将 Pod 创建在非 rook-ceph 专用节点的 ksp-worker-1 上。
- 编写测试 PVC 资源清单,
vi test-pvc-rbd.yaml
- 创建 PVC
- 查看 PVC
- 编写测试 Pod 资源清单,
vi test-pod-rbd.yaml
- 创建 Pod
- 查看 Pod( Pod 按预期创建在了 ksp-worker-1 节点,并正确运行)
- 查看 Pod 挂载的存储
- 测试存储空间读写
注意: 测试时,我们写入了 2G 的数据量,当达过我们创建的 PVC 2G 容量上限时会报错(实际使用写不满 2G)。说明,Ceph 存储可以做到容量配额限制。
9. Ceph Dashboard
Ceph 提供了一个 Dashboard 工具,我们可以在上面查看集群的状态,包括集群整体运行状态、Mgr、Mon、OSD 和其他 Ceph 进程的状态,查看存储池和 PG 状态,以及显示守护进程的日志等。
部署集群的配置文件 cluster.yaml ,默认已经开启了 Dashboard 功能,Rook Ceph operator 部署集群时将启用 ceph-mgr 的 Dashboard 模块。
9.1 获取 Dashboard 的 service 地址
9.2 配置在集群外部访问 Dashboard
通常我们需要在 K8s 集群外部访问 Ceph Dashboard,可以通过 NodePort 或是 Ingress 的方式。
本文演示 NodePort 方式。
- 创建资源清单文件,
vi ceph-dashboard-external-https.yaml
- 创建资源
- 验证创建的资源
9.3 获取 Login Credentials
登陆 Dashboard 时需要身份验证,Rook 创建了一个默认用户,用户名 admin。创建了一个名为 rook-ceph-dashboard-password 的 secret 存储密码,使用下面的命令获取随机生成的密码。
9.4 通过浏览器打开 Dashboard
访问 K8s 集群中任意节点的 IP,https://192.168.9.91:31443,默认用户名 admin,密码通过上面的命令获取。

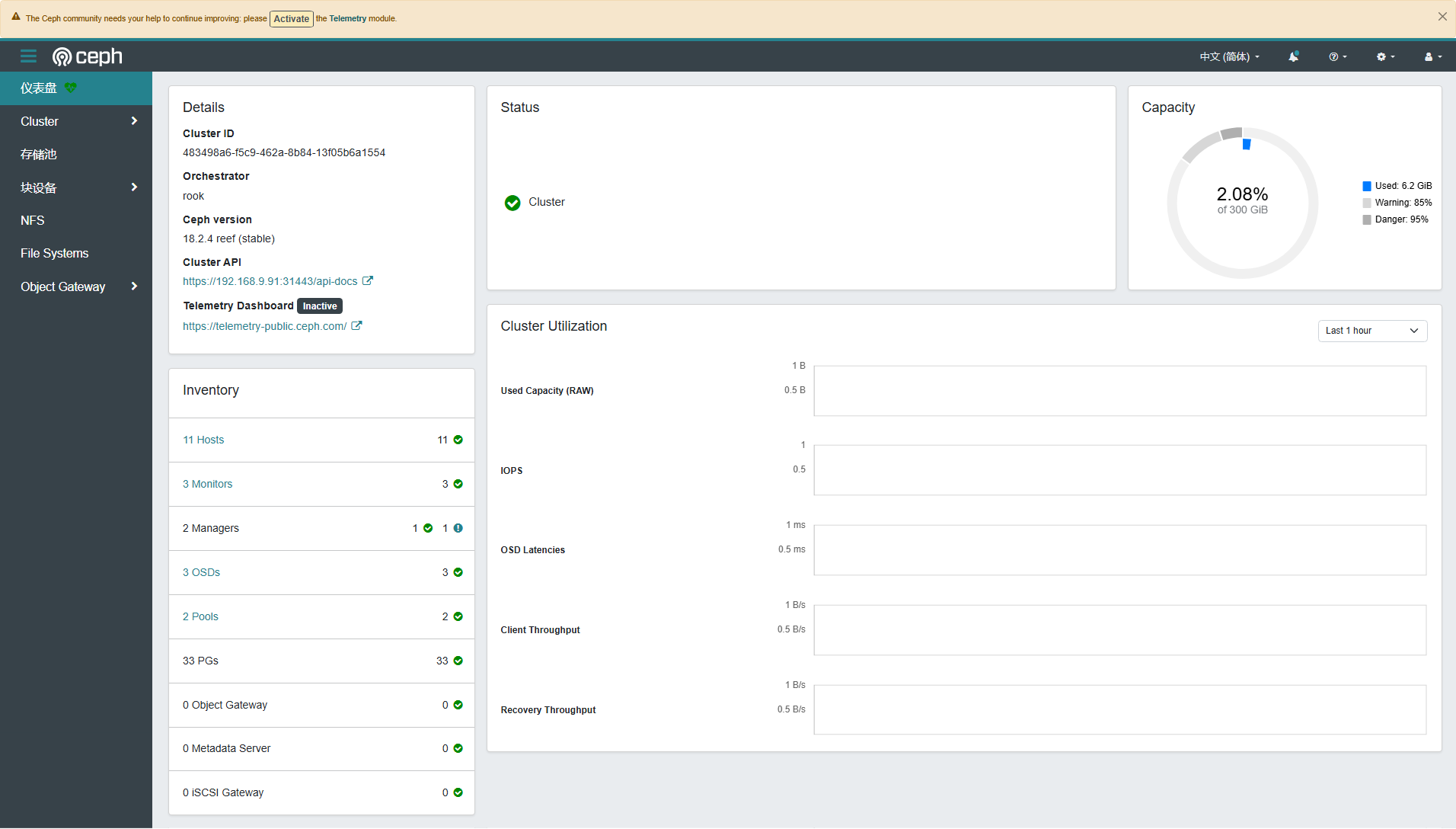
9.5 Ceph Dashboard 概览
Ceph Dashboard 虽然界面简单,但是常用的管理功能都具备,能实现图形化管理存储资源。下面展示几张截图,作为本文的结尾。
- Dashboard
- 集群-主机
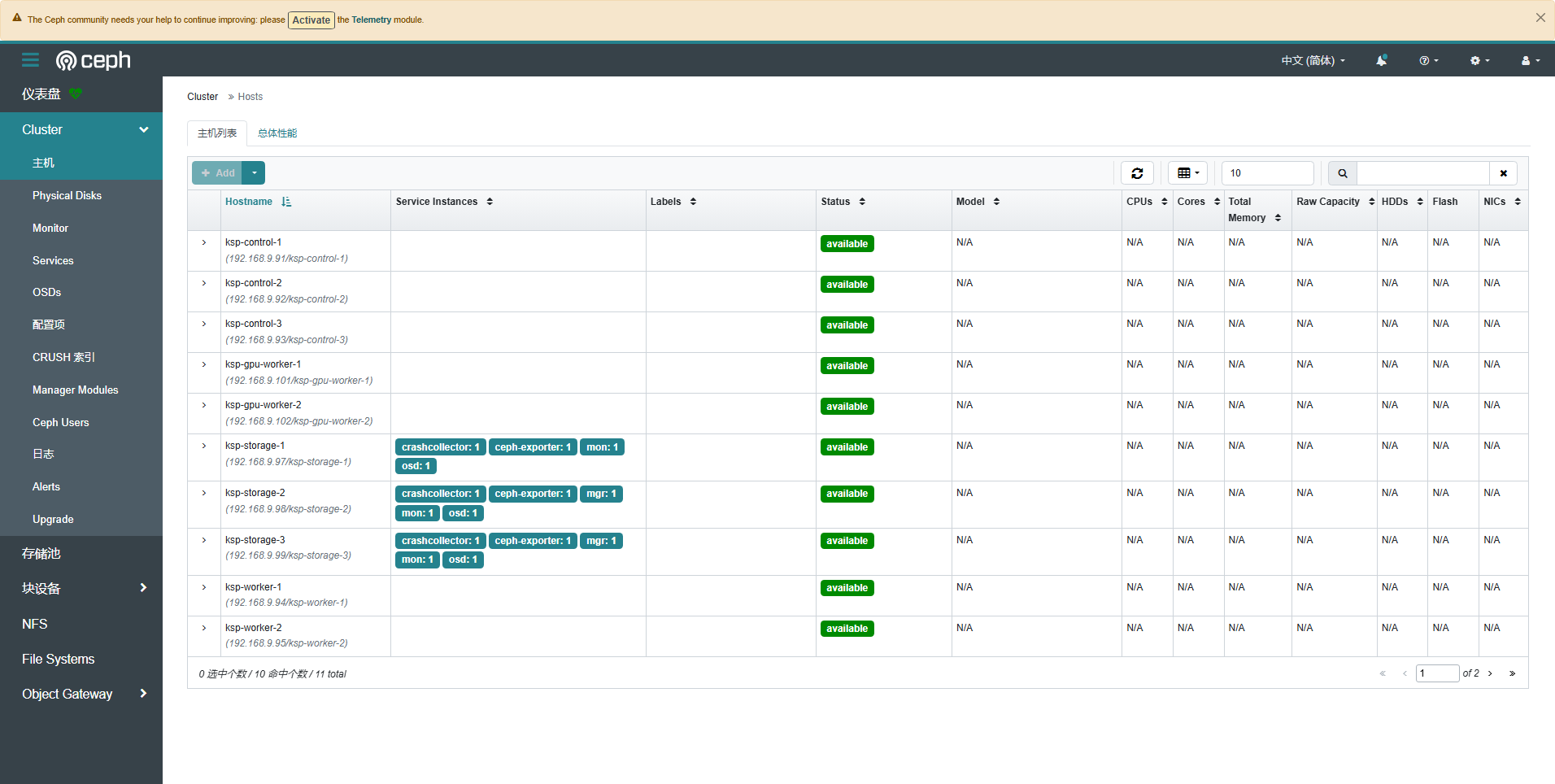
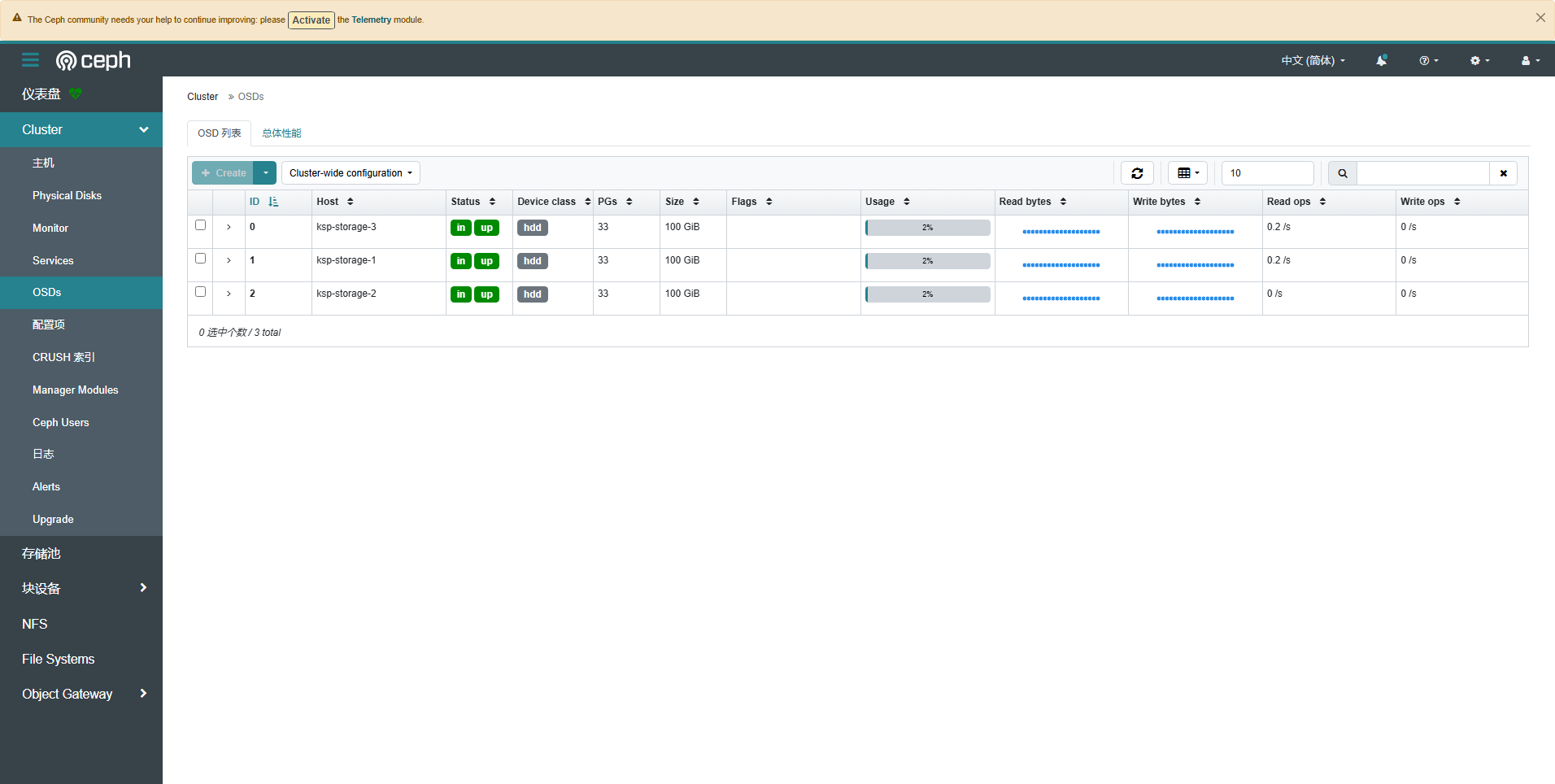
- 集群-OSD
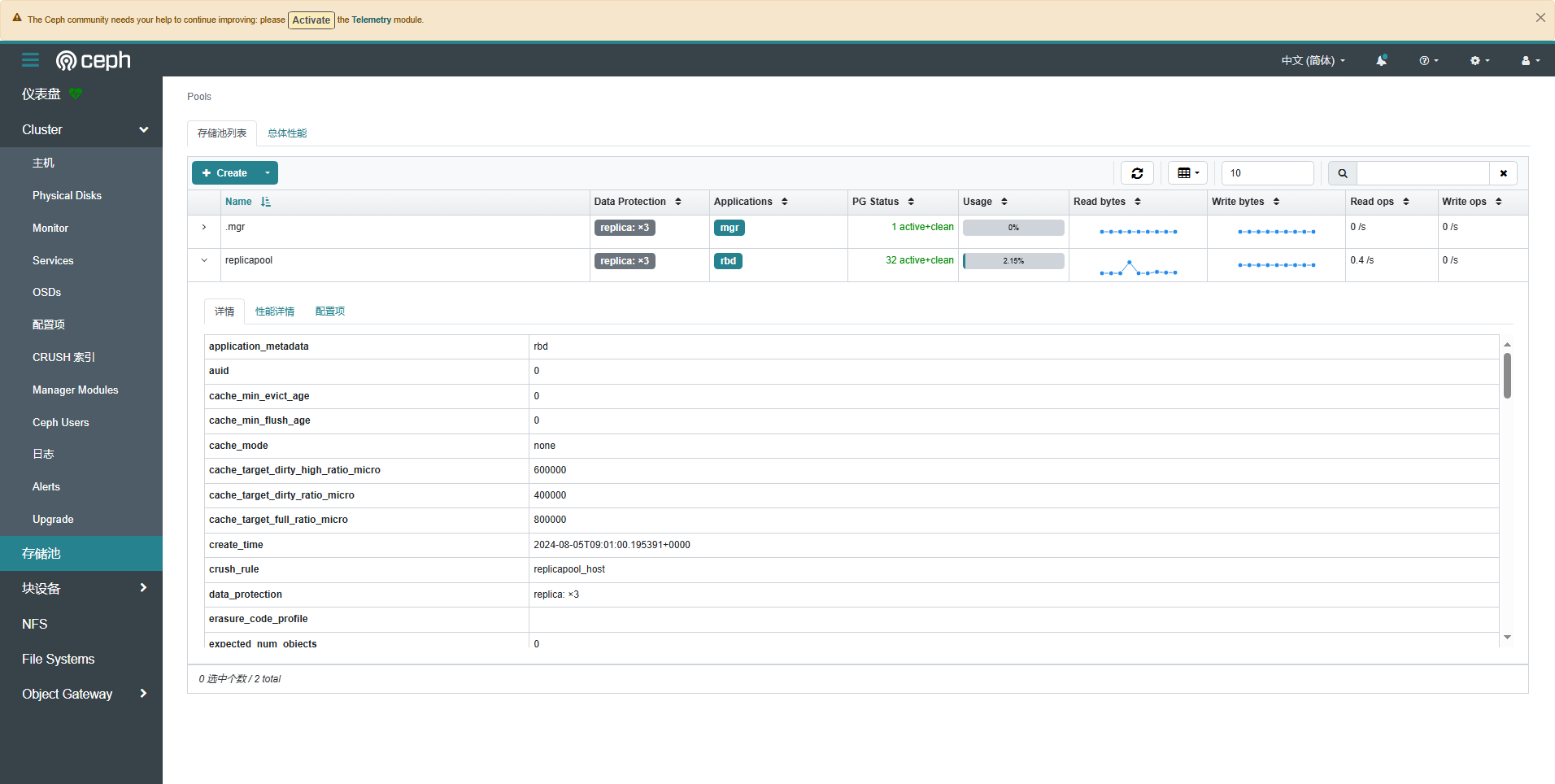
- 存储池
免责声明:
- 笔者水平有限,尽管经过多次验证和检查,尽力确保内容的准确性,但仍可能存在疏漏之处。敬请业界专家大佬不吝指教。
- 本文所述内容仅通过实战环境验证测试,读者可学习、借鉴,但严禁直接用于生产环境。由此引发的任何问题,作者概不负责!

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











