






在学完前面四周的视频课程后,我学会了如何利用matlab和python的spyder编辑器做线性回归拟合直线和逻辑回归分类两件事,而神经网络的反向传播算法的数学公式原理Ng老师没有做详细的推导和说明,在网上的各种资源的帮助下结合这一周的课后作业代码,小葵花妈妈课堂。
这周的作业干了这么一件事情,小葵花妈妈在黑板上写了5000个阿拉伯数字,1到500个数字写的10,501到1000写的1,以此类推,最后4501到5000写的9,小葵花妈妈想要通过这5000个数字训练小葵花认识1到10这个数字,以后能通过它们的特征认出这10个数字,所以小葵花妈妈对每个数字提取出了400个特征点也就是用400个数来表示,这400个特征数共同决定在这个数字是1到10中的哪一个概率最大,概率最大就认为这个数字是几。
好,现在题目给了我们一个5000*400的矩阵X,和一个5000*1的向量y(输出结果,代码中计算误差时,处理成了y_onehot),现在我们只看X其中一行的400个数怎么确定出最后的手写数字是几的。
我们把这400个数叫这个神经网络的输入层,题目再告诉我们隐藏层的也只有1层,并且这一层有25个数,最后输出层就是10个数,这10个数代表这个阿拉伯数字分别为1到10的概率,选取概率最大的确定为结果y。
这个决定过程是这样的,把我们原始有的400个特征数最前面加一个1,这个1先理解为除这400个特征数外的所有外界影响,把401个数写成一个1*401的矩阵a1(行向量),由题意得,设theta1为401*25的矩阵,a1*theta1得到1*25的矩阵z2(行向量),这个操作可以理解为通过theta1矩阵把400+1个特征数转化为离最终结果更近的25个特征数,不过这个z2刚出生,还没得到认可,不具有特征这个阿拉伯数字的权利,需要进行激活一下,所以a2=g(z2),函数g为sigmoid函数:1 / (1 + exp(-z)),这是上一周逻辑回归的内容,也就是说把z2中的25个数分别带入上面(1+e的(-z)次方)分之1这个函数来得到新的25个数,得到a2,这是1*25的行向量,代表激活后的25个特征数。

再重复上面步骤,在a2前加一个1,(嗯,你懂的),得到这个1*26的矩阵(行向量)a2,由题意设theta2为 26*10 的矩阵,z3=a2*theta2,z3就是1*10的矩阵(行向量)了,不要忘了激活一下,a3=g(z3),(嗯,这个你也懂的),好,激活完成了,a3(1*10的哈)这10个数就是最终这个阿拉伯数字分别为1到10的10个概率了,哪个概率最大,就是几了。
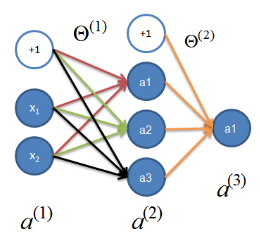
好了,题目背景(也叫正向传播)就是这样了,所以我们想要的就是我们设的未知数theta1和theta2了,求是不可能求出来的了,我们只能找到最好的她们俩让最终结果的误差最小,那这个误差长成什么样子呢,
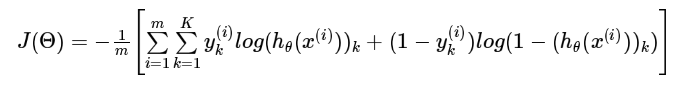
Ng的课堂上给的是这个样子的,是一个戴着很多层口罩的妹子(天冷),脱这个口罩很麻烦,只有暴力点了。

现在应该理解误差(代价函数)是什么意思了,通过前几周的课程,知道还需要知道梯度,才能进行梯度下降,让误差最小,这里的梯度不能像高数里面求出关于未知数的导函数式子,而是求出在确定theta1和theta2位置处的梯度值(导函数值)。
整个过程是这样的,计算机随机给出theta1和theta2的初始值,因为是随机给的,我们进行一遍正向传播,求出结果a3概率预测,和实际y_onehot概率(或者实际的y值)对比,发现基本都预测错了,计算误差J,发现误差J的值非常大。
现在我们计算在确定的初始theta1和theta2处的梯度值,计算出的结果是两个和theta1,theta2维数一致的矩阵,代表对应位置参数的梯度值,在最后的代码中,将两个梯度矩阵,按行展开为一整个行向量,初始的theta输入也展开为一整个行向量,连同误差J的计算方法导入minimize优化函数中,进行迭代优化,算出使J计算最小的最优的theta(为一个行向量,最后按维数合成theta1和theta2)。(这一段需要结合代码理解,正则化项可以先不管,理解好了最好再处理正则化,不会的回去复习Ng前面讲正则化的部分)。

上面的推导过程结合后面的python代码理解,最后把最优的theta1和theta2进行一次正向传播计算a3(h)发现,预测基本准确,如果计算J也非常小,当我用5000组数据进行训练,最后检测这5000组预测 ,正确率有99.98%。当我只用间隔的2500组数据训练,检测整体的5000组数据,正确率还有95%左右。而只用2500数据训练,检测另外的2500组数据时,正确率跌倒91%。
# -*- coding: utf-8 -*-
"""
Created on Tue Nov 21 16:30:57 2017
@author: leisure
"""
# -*- coding: utf-8 -*-
import numpy as np
from scipy.io import loadmat
def sigmoid(z):
return 1 / (1 + np.exp(-z))
def forward_propagate(X, theta1, theta2):
m = X.shape[0] #5000组数据
a1 = np.insert(X, 0, values=np.ones(m), axis=1) #在X最前 面加一列5000*1的向量
z2 = a1 * theta1 #得到5000*25的矩阵,400个特征转化为25个隐藏特征
a2 = np.insert(sigmoid(z2), 0, values=np.ones(m), axis=1) #取激活后的z2,再加一列5000*1的向量
z3 = a2 * theta2 #得到5000*10的矩阵,最后10个特征
h = sigmoid(z3) #激活后得到10个概率
return a1, z2, a2, z3, h
def sigmoid_gradient(z):
return np.multiply(sigmoid(z), (1 - sigmoid(z)))
def backprop(params, input_size, hidden_size, num_labels, X, y,learning_rate):
m = X.shape[0]
X = np.matrix(X)
y = np.matrix(y)
# reshape the parameter array into parameter matrices for each layer
theta1 = np.matrix(np.reshape(params[:hidden_size * (input_size + 1)], ((input_size + 1),hidden_size)))
theta2 = np.matrix(np.reshape(params[hidden_size * (input_size + 1):], ((hidden_size + 1),num_labels)))
# run the feed-forward pass
a1, z2, a2, z3, h = forward_propagate(X, theta1, theta2)
# initializations
J = 0
delta1 = np.zeros(theta1.shape) # (401, 25)
delta2 = np.zeros(theta2.shape) # (26, 10)
# compute the cost
for i in range(m):
first_term = np.multiply(-y[i,:], np.log(h[i,:])) #y_onehot的每一行和输出概率h的每一行数据相乘
second_term = np.multiply((1 - y[i,:]), np.log(1 - h[i,:]))
J += np.sum(first_term - second_term) #乘出来的10*1的向量元素求和,再累加5000组的数据
J = J / m
# add the cost regularization term
J += (float(learning_rate) / (2 * m)) * (np.sum(np.power(theta1[1:,:], 2)) + np.sum(np.power(theta2[1:,:], 2))) #加上正则化的项
# perform backpropagation
for t in range(m):
a1t = a1[t,:] # (1, 401)
z2t = z2[t,:] # (1, 25)
a2t = a2[t,:] # (1, 26)
ht = h[t,:] # (1, 10)
yt = y[t,:] # (1, 10)
d3t = ht - yt # (1, 10) 最后的误差向量
d2t = np.multiply((d3t * theta2.T)[:,1:], sigmoid_gradient(z2t)) # (1, 25)
delta1 = delta1 + a1t.T * d2t #401*25
delta2 = delta2 + a2t.T * d3t #26*10
delta1 = delta1 / m
delta2 = delta2 / m
# add the gradient regularization term
delta1[1:,:] = delta1[1:,:] + (theta1[1:,:] * learning_rate) / m
delta2[1:,:] = delta2[1:,:] + (theta2[1:,:] * learning_rate) / m
# unravel the gradient matrices into a single array
grad = np.concatenate((np.ravel(delta1), np.ravel(delta2)))
return J, grad
from scipy.optimize import minimize
# initial setup
data = loadmat('ex4data1.mat') #字典形式的数据结构
X = data['X']
y = data['y']
from sklearn.preprocessing import OneHotEncoder
encoder = OneHotEncoder(sparse=False)
y_onehot = encoder.fit_transform(y) # 每组数据中概率最大的为1,其余为0,5000*10
input_size = 400
hidden_size = 25
num_labels = 10
learning_rate = 1
# randomly initialize a parameter array of the size of the full network's parameters
params = (np.random.random(size=hidden_size * (input_size + 1) + num_labels * (hidden_size + 1)) - 0.5) * 0.25
m = X.shape[0]
X = np.matrix(X)
y = np.matrix(y)
# minimize the objective function
fmin = minimize(fun=backprop, x0=params, args=(input_size, hidden_size, num_labels, X, y_onehot,learning_rate),
method='TNC', jac=True, options={'maxiter': 250})
theta1 = np.matrix(np.reshape(fmin.x[:hidden_size * (input_size + 1)], ((input_size + 1),hidden_size )))
theta2 = np.matrix(np.reshape(fmin.x[hidden_size * (input_size + 1):], ((hidden_size + 1),num_labels )))
a1, z2, a2, z3, h = forward_propagate(X, theta1, theta2)
y_pred = np.array(np.argmax(h, axis=1) + 1)
correct = [1 if a == b else 0 for (a, b) in zip(y_pred, y)]
accuracy = (sum(map(int, correct)) / float(len(correct)))
print ('accuracy = {0}%'.format(accuracy * 100)) 我们都是初学者,希望更多人可以更快迈过这道坎,继续学习下去。















 612
612











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









