






tcp/ip四层源码分析(Linux)之socket.c
文章目录
分析版本:linux-4.16.12
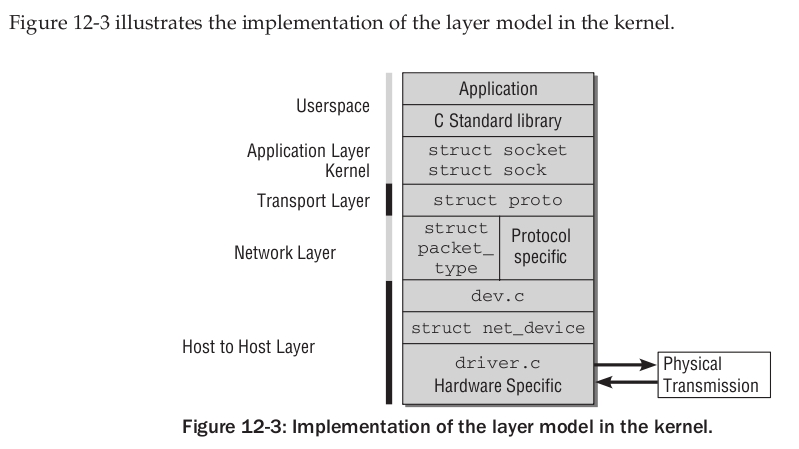
由这个图可知,内核中的进程可以通过使用struct socket结构体来访问linux内核中的网络系统中的传输层、网络层、数据链路层。也可以说struct socket是内核中的进程与内核中的网路系统的桥梁。
1、socket层
这一部分处理BSD socket相关操作,每个socket在内核中以struct socket结构体现这一部分的文件
应用系统的函数调用如socket、bind、listen、accept、connect 等函数,将通过共同的入口函数 sys_socket 调用BSD socket层的对应系统调用函数,如sock_socket、sock_bind、sock_listen、sock_accept、sock_connect 等函数(socket.c)。从前面分析得知, sock_ 函数内部又将调用下一层的函数实现
主要有:/net/socket.c /net/protocols.c etc
2、INET socket层
BSD socket层对应的套接字结构是 socket 结构,这是一个通用的套接字结构,INET socket 层则使用的是 sock 结构,这是一个比 socket 更复杂的结构,具体到某种协议,一个通用,一个是具体
bsd套接字层,操作的对象是socket,数据存放在msghdr这样的数据结构:
struct msghdr {
void *msg_name; /* ptr to socket address structure */
int msg_namelen; /* size of socket address structure */
struct iov_iter msg_iter; /* data */
void *msg_control; /* ancillary data */
__kernel_size_t msg_controllen; /* ancillary data buffer length */
unsigned int msg_flags; /* flags on received message */
struct kiocb *msg_iocb; /* ptr to iocb for async requests */
};
创建socket需要传递family,type,protocol三个参数,创建socket其实就是创建一个socket实例,然后创建一个文件描述符结构,并且互相建立一些关联,即建立互相连接的指针,并且初始化这些对文件的写读操作映射到socket的read,write函数上来。
struct socket {
socket_state state;
short type;
unsigned long flags;
struct socket_wq __rcu *wq;
struct file *file;
struct sock *sk;//socket在网络层中的标识
const struct proto_ops *ops;
};
socket结构体解释
typedef enum {
SS_FREE = 0, //该socket还未分配
SS_UNCONNECTED, //未连向任何socket
SS_CONNECTING, //正在连接过程中
SS_CONNECTED, //已连向一个socket
SS_DISCONNECTING //正在断开连接的过程中
}socket_state;
该成员只对TCP socket有用,因为只有tcp是面向连接的协议,udp跟raw不需要维护socket状态。
flags是一组标志位,在内核中并没有发现被使用
struct socket结构体的类型
struct socket 中的flags字段取值:
struct socket 中的flags字段取值:
#define SOCK_ASYNC_NOSPACE 0
#define SOCK_ASYNC_WAITDATA 1
#define SOCK_NOSPACE 2
#define SOCK_PASSCRED 3
#define SOCK_PASSSEC 4
我们知道在TCP层中使用两个协议:tcp协议和udp协议。而在将TCP层中的数据往下传输时,要使用网络层的协议,而网络层的协议很多,不同的网络使用不同的网络层协议。我们常用的因特网中,网络层使用的是IPV4和IPV6协议。
所以在内核中的进程在使用struct socket提取内核网络系统中的数据时,不光要指明struct socket的类型(用于说明是提取TCP层中tcp协议负载的数据,还是udp层负载的数据),还要指明网络层的协议类型(网络层的协议用于负载TCP层中的数据)。
linux内核中的网络系统中的网络层的协议,在linux中被称为address family(地址簇,通常以AF_XXX表示)或protocol family(协议簇,通常以PF_XXX表示)
定义在文件:include/linux/socket.h中
创建一个socket结构体
int sock_create(int family, int type, int protocol,
struct socket **res);
int sock_create_kern(int family, int type, int protocol,
struct socket **res);
EXPROT_SYMBOL(sock_create);
EXPROT_SYMBOL(sock_create_kern);
family : 指定协议簇的类型,其值为:PF_XXX或 AF_XXX
type : 指定要创建的struct socket结构体的类型;
protocol : 一般为0;
res : 中存放创建的struct socket结构体的地址
int sock_create(int family, int type, int protocol, struct socket **res)
{
return __sock_create(current->nsproxy->net_ns, family, type, protocol, res, 0);
}
int sock_create_kern(int family, int type, int protocol, struct socket **res)
{
return __sock_create( &init_net, family, type, protocot, res, 1 );
}
如果在内核中创建struct socket时,推荐使用sock_create_kern()函数;
proto_ops之Socket层标识
inet_stream_ops
const struct proto_ops inet_stream_ops = {
.family = PF_INET,
.owner = THIS_MODULE,
.release = inet_release,//
.bind = inet_bind,
.connect = inet_stream_connect,
.socketpair = sock_no_socketpair,
.accept = inet_accept,
.getname = inet_getname,
.poll = tcp_poll,
.ioctl = inet_ioctl,
.listen = inet_listen,
.shutdown = inet_shutdown,
.setsockopt = sock_common_setsockopt,
.getsockopt = sock_common_getsockopt,
.sendmsg = inet_sendmsg,
.recvmsg = inet_recvmsg,
.mmap = sock_no_mmap,
.sendpage = inet_sendpage,
.splice_read = tcp_splice_read,
.read_sock = tcp_read_sock,
.sendmsg_locked = tcp_sendmsg_locked,
.sendpage_locked = tcp_sendpage_locked,
.peek_len = tcp_peek_len,
#ifdef CONFIG_COMPAT
.compat_setsockopt = compat_sock_common_setsockopt,
.compat_getsockopt = compat_sock_common_getsockopt,
.compat_ioctl = inet_compat_ioctl,
#endif
};
EXPORT_SYMBOL(inet_stream_ops);
**proto_ops:**该结构体包含了某个特定的“protocol family"的一系列functions。 其包含的functions和struct proto很类似,但是其在socket层 (见下图中1的位置)。
例如,inet_stream_ops对应SOCK_STREAM, inet_dgram_ops对应SOCK_DGRAM
当socket相关的systemcall发生时, 首先从"proto_ops"结构体中调用相应的function, 然后对应的ip-protocol function从proto结构体中被调用
prot该结构体包含了某个特定的ip protocol的一系列functions, 包括close(), connect(), accept(), bind()等,例如,tcp_prot对应于SOCK_STREAM, udp_prot对应于SOCK_DGRAM
tcp_prot对应于SOCK_STREAM
struct proto tcp_prot = {
.name = "TCP",
.owner = THIS_MODULE, //此模块
.close = tcp_close,
.connect = tcp_v4_connect,
.disconnect = tcp_disconnect,
.accept = inet_csk_accept,
.ioctl = tcp_ioctl,
.init = tcp_v4_init_sock,
.destroy = tcp_v4_destroy_sock,
.shutdown = tcp_shutdown,
.setsockopt = tcp_setsockopt,
.getsockopt = tcp_getsockopt,
.keepalive = tcp_set_keepalive,
.recvmsg = tcp_recvmsg,
.sendmsg = tcp_sendmsg,
.sendpage = tcp_sendpage,
.backlog_rcv = tcp_v4_do_rcv,
.release_cb = tcp_release_cb,
.hash = inet_hash,
.unhash = inet_unhash,
.get_port = inet_csk_get_port,
.enter_memory_pressure = tcp_enter_memory_pressure,
.leave_memory_pressure = tcp_leave_memory_pressure,
.stream_memory_free = tcp_stream_memory_free,
.sockets_allocated = &tcp_sockets_allocated,
.orphan_count = &tcp_orphan_count,
.memory_allocated = &tcp_memory_allocated,
.memory_pressure = &tcp_memory_pressure,
.sysctl_mem = sysctl_tcp_mem,
.sysctl_wmem_offset = offsetof(struct net, ipv4.sysctl_tcp_wmem),
.sysctl_rmem_offset = offsetof(struct net, ipv4.sysctl_tcp_rmem),
.max_header = MAX_TCP_HEADER,
.obj_size = sizeof(struct tcp_sock),
.slab_flags = SLAB_TYPESAFE_BY_RCU,
.twsk_prot = &tcp_timewait_sock_ops,
.rsk_prot = &tcp_request_sock_ops,
.h.hashinfo = &tcp_hashinfo,
.no_autobind = true,
#ifdef CONFIG_COMPAT
.compat_setsockopt = compat_tcp_setsockopt,
.compat_getsockopt = compat_tcp_getsockopt,
#endif
.diag_destroy = tcp_abort,
};
EXPORT_SYMBOL(tcp_prot);
udp_prot对应于SOCK_DGRAM
struct proto udp_prot = {
.name = "UDP",
.owner = THIS_MODULE,
.close = udp_lib_close,
.connect = ip4_datagram_connect,
.disconnect = udp_disconnect,
.ioctl = udp_ioctl,
.init = udp_init_sock,
.destroy = udp_destroy_sock,
.setsockopt = udp_setsockopt,
.getsockopt = udp_getsockopt,
.sendmsg = udp_sendmsg,
.recvmsg = udp_recvmsg,
.sendpage = udp_sendpage,
.release_cb = ip4_datagram_release_cb,
.hash = udp_lib_hash,
.unhash = udp_lib_unhash,
.rehash = udp_v4_rehash,
.get_port = udp_v4_get_port,
.memory_allocated = &udp_memory_allocated,
.sysctl_mem = sysctl_udp_mem,
.sysctl_wmem = &sysctl_udp_wmem_min,
.sysctl_rmem = &sysctl_udp_rmem_min,
.obj_size = sizeof(struct udp_sock),
.h.udp_table = &udp_table,
#ifdef CONFIG_COMPAT
.compat_setsockopt = compat_udp_setsockopt,
.compat_getsockopt = compat_udp_getsockopt,
#endif
.diag_destroy = udp_abort,
};
EXPORT_SYMBOL(udp_prot);
总结networking
从几个专有名词从上往下依次时
1.socket access
2.protocol families(协议家族)
3.networking storage和sokcet splice
4.protocols
5.networking interface
6.network device drivers
7.network controllers
有以上的代码可知:linux内核在使用sock_create()、sock_create_kern()
进行struct socket结构体的创建时,其本质是分配了一个struct socket_alloc
结构体,而这个struct socket_alloc结构体中包含了struct socket 和struct
inode(struct inode结构体,是linux内核用来刻画一个存放在内存中的文件的,通过将struct inode 和 struct socket绑定在一起形成struct socket_alloc结构体,来表示内核中的网络文件)。然后对分配的struct socket结构体进行初始化,来定义内核中的网络文件的类型(family, type, protocol).
网络协议簇结构体
struct net_proto_family
{
int family ; // 协议簇
int (*create)(struct net *net, struct socket *sock, int protocol);
struct module *owner;
};
内核中的所有的网络协议的响应的网络协议簇结构体都存放在 net_families[]指针数组中;
static struct net_proto_family *net_families[NPROTO];211或138
static int __sock_create(struct net *net, int family, int type, int protocol,
struct socket **res, int kern )
{
struct socket *sock;
struct net_proto_family *pf;
sock = sock_alloc();//分配一个struct socket 结构体
sock->type = type;
pf = rcu_dereference(net_families[family]); //获取相应的网络协议簇结构体的地址;
pf->create(net, sock, protocol); // 对struct socket结构体做相应的处理;
*res = sock; // res中保存创建的struct socket结构体的地址;
return 0;
}
主要的操作函数
struct socket_alloc
{
struct socket socket ;
struct inode vfs_node ;
}
static inline struct socket *SOCKET_I(struct inode *inode)
{
return &contain_of(inode, struct socket_alloc, vfs->node)->socket;
}
static struct socket *sock_alloc(void)
{
struct inode *inode;
struct socket *sock;
inode = new_inode(sock_mnt->mnt_sb);//分配一个新的struct inode节点
sock = SOCKET_I(inode);
inode->i_mode = S_IFSOCK | S_IRWXUGO;//设置inode节点的权限
inode->i_uid = current_fsuid(); // 设置节点的UID
inode->i_gid = current_fsgid(); //设置节点的GID
return sock;
}
struct proto_ops {
int family;
struct module *owner;
int (*release) (struct socket *sock);
int (*bind) (struct socket *sock,
struct sockaddr *myaddr,
int sockaddr_len);
int (*connect) (struct socket *sock,
struct sockaddr *vaddr,
int sockaddr_len, int flags);
int (*socketpair)(struct socket *sock1,
struct socket *sock2);
int (*accept) (struct socket *sock,
struct socket *newsock, int flags, bool kern);
int (*getname) (struct socket *sock,
struct sockaddr *addr,
struct poll_table_struct *wait);
int (*ioctl) (struct socket *sock, unsigned int cmd,
unsigned long arg);
#ifdef CONFIG_COMPAT
int (*compat_ioctl) (struct socket *sock, unsigned int cmd,
unsigned long arg);
#endif
int (*listen) (struct socket *sock, int len);
int (*shutdown) (struct socket *sock, int flags);
int (*setsockopt)(struct socket *sock, int level,
int (*getsockopt)(struct socket *sock, int level,
int optname, char __user *optval, int __user *optlen);
#ifdef CONFIG_COMPAT
int (*compat_setsockopt)(struct socket *sock, int level,
int (*compat_getsockopt)(struct socket *sock, int level,
int optname, char __user *optval, int __user *optlen);
#endif
int (*sendmsg) (struct socket *sock, struct msghdr *m,
size_t total_len);
/* Notes for implementing recvmsg:
* ===============================
* msg->msg_namelen should get updated by the recvmsg handlers
* iff msg_name != NULL. It is by default 0 to prevent
* returning uninitialized memory to user space. The recvfrom
* handlers can assume that msg.msg_name is either NULL or has
* a minimum size of sizeof(struct sockaddr_storage).
*/
int (*recvmsg) (struct socket *sock, struct msghdr *m,
size_t total_len, int flags);
int (*mmap) (struct file *file, struct socket *sock,
struct vm_area_struct * vma);
ssize_t (*sendpage) (struct socket *sock, struct page *page,
int offset, size_t size, int flags);
ssize_t (*splice_read)(struct socket *sock, loff_t *ppos,
struct pipe_inode_info *pipe, size_t len, unsigned int flags);
int (*set_peek_off)(struct sock *sk, int val);
int (*peek_len)(struct socket *sock);
/* The following functions are called internally by kernel with
* sock lock already held.
*/
int (*read_sock)(struct sock *sk, read_descriptor_t *desc,
sk_read_actor_t recv_actor);
int (*sendpage_locked)(struct sock *sk, struct page *page,
int offset, size_t size, int flags);
int (*sendmsg_locked)(struct sock *sk, struct msghdr *msg,
size_t size);
};
同时初始化socket的操作函数(proto_ops结构),如果传入的type参数是STREAM类型,那么就初始化为SOCKET->ops为inet_stream_ops,如果是DGRAM类型,则SOCKET-ops为inet_dgram_ops。对于inet_stream_ops其实是一个结构体,包含了stream类型的socket操作的一些入口函数,在这些函数里主要做的是对socket进行相关的操作,同时通过调用下面提到的sock中的相关操作完成socket到sock层的传递。比如在
inet_stream_ops里有个inet_release的操作,这个操作除了释放socket的类型空间操作外,还通过调用socket连接的sock的close操作,对于stream类型来说,即tcp_close来关闭sock
释放sock。
层次解释(socket->sock)
协议栈中总共定义了三个struct proto_ops类型的变量,分别是myinet_stream_ops, myinet_dgram_ops, myinet_sockraw_ops,对应流协议, 数据报和原始套接口协议的操作函数集
enum sock_type
{
SOCK_STREAM = 1, // 用于与TCP层中的tcp协议数据的struct socket
SOCK_DGRAM = 2, //用于与TCP层中的udp协议数据的struct socket
SOCK_RAW = 3, // raw struct socket
SOCK_RDM = 4, //可靠传输消息的struct socket
SOCK_SEQPACKET = 5,// sequential packet socket
SOCK_DCCP = 6,
SOCK_PACKET = 10, //从dev level中获取数据包的socket
};
sk是网络层对于socket的表示
sk_prot和sk_prot_creator,这两个成员指向特定的协议处理函数集,其类型是结构体struct proto,该结构体也是跟struct proto_ops相似的一组协议操作函数集。这两者之间的概念似乎有些混淆,可以这么理解,struct proto_ops的成员操作struct socket层次上的数据,处理完了,再由它们调用成员sk->sk_prot的函数,操作struct sock层次上的数据。即它们之间存在着层次上的差异。struct proto类型的变量在协议栈中总共也有三个,分别是mytcp_prot,myudp_prot,myraw_prot,对应TCP, UDP和RAW协议。
struct sock {
/*
* Now struct inet_timewait_sock also uses sock_common, so please just
* don't add nothing before this first member (__sk_common) --acme
*/
struct sock_common __sk_common;
#define sk_node __sk_common.skc_node
#define sk_nulls_node __sk_common.skc_nulls_node
#define sk_refcnt __sk_common.skc_refcnt
#define sk_tx_queue_mapping __sk_common.skc_tx_queue_mapping
#define sk_dontcopy_begin __sk_common.skc_dontcopy_begin
#define sk_dontcopy_end __sk_common.skc_dontcopy_end
#define sk_hash __sk_common.skc_hash
#define sk_portpair __sk_common.skc_portpair
#define sk_num __sk_common.skc_num
#define sk_dport __sk_common.skc_dport
#define sk_addrpair __sk_common.skc_addrpair
#define sk_daddr __sk_common.skc_daddr
#define sk_rcv_saddr __sk_common.skc_rcv_saddr
#define sk_family __sk_common.skc_family
#define sk_state __sk_common.skc_state
#define sk_reuse __sk_common.skc_reuse
#define sk_reuseport __sk_common.skc_reuseport
#define sk_ipv6only __sk_common.skc_ipv6only
#define sk_net_refcnt __sk_common.skc_net_refcnt
#define sk_bound_dev_if __sk_common.skc_bound_dev_if
#define sk_bind_node __sk_common.skc_bind_node
#define sk_prot __sk_common.skc_prot
#define sk_net __sk_common.skc_net
#define sk_v6_daddr __sk_common.skc_v6_daddr
#define sk_v6_rcv_saddr __sk_common.skc_v6_rcv_saddr
#define sk_cookie __sk_common.skc_cookie
#define sk_incoming_cpu __sk_common.skc_incoming_cpu
#define sk_flags __sk_common.skc_flags
#define sk_rxhash __sk_common.skc_rxhash
socket_lock_t sk_lock;
atomic_t sk_drops;
int sk_rcvlowat;
struct sk_buff_head sk_error_queue;
struct sk_buff_head sk_receive_queue;
/*
* The backlog queue is special, it is always used with
* the per-socket spinlock held and requires low latency
* access. Therefore we special case it's implementation.
* Note : rmem_alloc is in this structure to fill a hole
* on 64bit arches, not because its logically part of
* backlog.
*/
struct {
atomic_t rmem_alloc;
int len;
struct sk_buff *head;
struct sk_buff *tail;
} sk_backlog;
#define sk_rmem_alloc sk_backlog.rmem_alloc
int sk_forward_alloc;
#ifdef CONFIG_NET_RX_BUSY_POLL
unsigned int sk_ll_usec;
/* ===== mostly read cache line ===== */
unsigned int sk_napi_id;
#endif
int sk_rcvbuf;
struct sk_filter __rcu *sk_filter;
union {
struct socket_wq __rcu *sk_wq;
struct socket_wq *sk_wq_raw;
};
#ifdef CONFIG_XFRM
struct xfrm_policy __rcu *sk_policy[2];
#endif
struct dst_entry *sk_rx_dst;
struct dst_entry __rcu *sk_dst_cache;
atomic_t sk_omem_alloc;
int sk_sndbuf;
/* ===== cache line for TX ===== */
int sk_wmem_queued;
refcount_t sk_wmem_alloc;
unsigned long sk_tsq_flags;
union {
struct sk_buff *sk_send_head;
struct rb_root tcp_rtx_queue;
};
struct sk_buff_head sk_write_queue;
__s32 sk_peek_off;
int sk_write_pending;
__u32 sk_dst_pending_confirm;
u32 sk_pacing_status; /* see enum sk_pacing */
long sk_sndtimeo;
struct timer_list sk_timer;
__u32 sk_priority;
__u32 sk_mark;
u32 sk_pacing_rate; /* bytes per second */
u32 sk_max_pacing_rate;
struct page_frag sk_frag;
netdev_features_t sk_route_caps;
netdev_features_t sk_route_nocaps;
int sk_gso_type;
unsigned int sk_gso_max_size;
gfp_t sk_allocation;
__u32 sk_txhash;
/*
* Because of non atomicity rules, all
* changes are protected by socket lock.
*/
unsigned int __sk_flags_offset[0];
#ifdef __BIG_ENDIAN_BITFIELD
#define SK_FL_PROTO_SHIFT 16
#define SK_FL_PROTO_MASK 0x00ff0000
#define SK_FL_TYPE_SHIFT 0
#define SK_FL_TYPE_MASK 0x0000ffff
#else
#define SK_FL_PROTO_SHIFT 8
#define SK_FL_PROTO_MASK 0x0000ff00
#define SK_FL_TYPE_SHIFT 16
#define SK_FL_TYPE_MASK 0xffff0000
#endif
unsigned int sk_padding : 1,
sk_kern_sock : 1,
sk_no_check_tx : 1,
sk_no_check_rx : 1,
sk_userlocks : 4,
sk_protocol : 8,
sk_type : 16;
#define SK_PROTOCOL_MAX U8_MAX
u16 sk_gso_max_segs;
u8 sk_pacing_shift;
unsigned long sk_lingertime;
struct proto *sk_prot_creator;
u32 sk_max_ack_backlog;
kuid_t sk_uid;
struct pid *sk_peer_pid;
const struct cred *sk_peer_cred;
long sk_rcvtimeo;
ktime_t sk_stamp;
u16 sk_tsflags;
u8 sk_shutdown;
u32 sk_tskey;
atomic_t sk_zckey;
struct socket *sk_socket;
void *sk_user_data;
#ifdef CONFIG_SECURITY
void *sk_security;
#endif
struct sock_cgroup_data sk_cgrp_data;
struct mem_cgroup *sk_memcg;
void (*sk_state_change)(struct sock *sk);
void (*sk_data_ready)(struct sock *sk);
void (*sk_write_space)(struct sock *sk);
void (*sk_error_report)(struct sock *sk);
int (*sk_backlog_rcv)(struct sock *sk,
struct sk_buff *skb);
void (*sk_destruct)(struct sock *sk);
struct sock_reuseport __rcu *sk_reuseport_cb;
struct rcu_head sk_rcu;
};
sk_state
sk_state表示socket当前的连接状态,是一个比struct socket的state更为精细的状态,其可能的取值如下
enum {
TCP_ESTABLISHED = 1,
TCP_SYN_SENT,
TCP_SYN_RECV,
TCP_FIN_WAIT1,
TCP_FIN_WAIT2,
TCP_TIME_WAIT,
TCP_CLOSE,
TCP_CLOSE_WAIT,
TCP_LAST_ACK,
TCP_LISTEN,
TCP_CLOSING,
TCP_MAX_STATES
;
这些取值从名字上看,似乎只使用于TCP协议,但事实上,UDP和RAW也借用了其中一些值,在一个socket创建之初,其取值都是 TCP_CLOSE,一个UDP socket connect完成后,将这个值改为TCP_ESTABLISHED,最后,关闭sockt前置回TCP_CLOSE,RAW也一样
sk_rcvbuf和sk_sndbuf分别表示接收和发送缓冲区的大小。sk_receive_queue和sk_write_queue分别为接收缓 冲队列和发送缓冲队列,队列里排列的是套接字缓冲区struct sk_buff,队列中的struct sk_buff的字节数总和不能超过缓冲区大小的设定
sk_rmem_alloc, sk_wmem_alloc和sk_omem_alloc分别表示接收缓冲队列,发送缓冲队列及其它缓冲队列中已经分配的字节数,用于跟踪缓冲区的使用情况。
struct sock有一个struct sock_common成员,因为struct inet_timewait_sock也要用到它,所以把它单独归到一个结构体中,其定义如下
struct sock_common {
unsigned short skc_family;
volatile unsigned char skc_state;
unsigned char skc_reuse;
int skc_bound_dev_if;
struct hlist_node skc_node;
struct hlist_node skc_bind_node;
atomic_t skc_refcnt;
unsigned int skc_hash;
struct proto *skc_prot;
};
struct inet_sock。
这是INET域专用的一个socket表示,它是在struct sock的基础上进行的扩展,在基本socket的属性已具备的基础上,struct inet_sock提供了INET域专有的一些属性,比如TTL,组播列表,IP地址,端口等,下面是其完整定义:
struct inet_sock {
struct sock sk;
#if defined(CONFIG_IPV6) || defined(CONFIG_IPV6_MODULE)
struct ipv6_pinfo *pinet6;
#endif
__u32 daddr; //IPv4的目的地址。
__u32 rcv_saddr; //IPv4的本地接收地址。
__u16 dport; //目的端口。
__u16 num; //本地端口(主机字节序)。
__u32 saddr; //发送地址。
__s16 uc_ttl;//16为有符号 //单播的ttl。
__u16 cmsg_flags;
struct ip_options *opt;
__u16 sport; //源端口。
__u16 id; //单调递增的一个值,用于赋给iphdr的id域。
__u8 tos; //服务类型。
__u8 mc_ttl; //组播的ttl
__u8 pmtudisc;
__u8 recverr:1,
is_icsk:1,
freebind:1,
hdrincl:1, //是否自己构建ip首部(用于raw协议)
mc_loop:1; //组播是否发向回路。
int mc_index; //组播使用的本地设备接口的索引。
__u32 mc_addr; //组播源地址。
struct ip_mc_socklist *mc_list; //组播组列表。
struct {
unsigned int flags;
unsigned int fragsize;
struct ip_options *opt;
struct rtable *rt;
int length;
u32 addr;
struct flowi fl;
} cork;
};
32+32+16+16+32+16+16+4
+16+16+8+8+8+1+1+1
+1+1+32+32+32+
++32+32+32+32+32+32+?+
struct raw_sock
这是RAW协议专用的一个socket的表示,它是在struct inet_sock基础上的扩展,因为RAW协议要处理ICMP协议的过滤设置,其定义如下:
struct raw_sock {
struct inet_sock inet;
struct icmp_filter filter;
};
struct udp_sock
这是UDP协议专用的一个socket表示,它是在struct inet_sock基础上的扩展,其定义如下:
struct udp_sock {
struct inet_sock inet;
int pending;
unsigned int corkflag;
__u16 encap_type;
__u16 len;
};
struct inet_connection_sock
看完上面两个,我们觉得第三个应该就是struct tcp_sock了,但事实上,struct tcp_sock并不直接从struct inet_sock上扩展,而是从struct inet_connection_sock基础上进行扩展,struct inet_connection_sock是所有面向连接的socket的表示,关于该socket,及下面所有tcp相关的socket,我们在分析 tcp实现时再详细介绍,这里只列出它们的关系
struct tcp_sock
这是TCP协议专用的一个socket表示,它是在struct inet_connection_sock基础进行扩展,主要是增加了滑动窗口协议,避免拥塞算法等一些TCP专有属性
struct tcp_sock {
/* inet_connection_sock has to be the first member of tcp_sock */
u16 gso_segs; /* Max number of segs per GSO packet */
* Header prediction flags
* 0x5?10 << 16 + snd_wnd in net byte order
*/
__be32 pred_flags;
* read the code and the spec side by side (and laugh ...)
* See RFC793 and RFC1122. The RFC writes these in capitals.
*/
u64 bytes_received; /* RFC4898 tcpEStatsAppHCThruOctetsReceived
* sum(delta(rcv_nxt)), or how many bytes
* were acked.
*/
u32 segs_in; /* RFC4898 tcpEStatsPerfSegsIn
* total number of segments in.
*/
u32 data_segs_in; /* RFC4898 tcpEStatsPerfDataSegsIn
* total number of data segments in.
*/
u32 rcv_nxt; /* What we want to receive next */
u32 copied_seq; /* Head of yet unread data */
u32 rcv_wup; /* rcv_nxt on last window update sent */
u32 snd_nxt; /* Next sequence we send */
u32 segs_out; /* RFC4898 tcpEStatsPerfSegsOut
* The total number of segments sent.
*/
u32 data_segs_out; /* RFC4898 tcpEStatsPerfDataSegsOut
* total number of data segments sent.
*/
u64 bytes_acked; /* RFC4898 tcpEStatsAppHCThruOctetsAcked
* sum(delta(snd_una)), or how many bytes
* were acked.
*/
u32 snd_una; /* First byte we want an ack for */
u32 rcv_tstamp; /* timestamp of last received ACK (for keepalives) */
u32 last_oow_ack_time; /* timestamp of last out-of-window ACK */
u32 tsoffset; /* timestamp offset */
struct list_head tsq_node; /* anchor in tsq_tasklet.head list */
u32 snd_wl1; /* Sequence for window update */
u32 snd_wnd; /* The window we expect to receive */
u32 max_window; /* Maximal window ever seen from peer */
u32 mss_cache; /* Cached effective mss, not including SACKS */
u32 window_clamp; /* Maximal window to advertise */
u32 rcv_ssthresh; /* Current window clamp */
/* Information of the most recently (s)acked skb */
struct tcp_rack {
u64 mstamp; /* (Re)sent time of the skb */
u32 rtt_us; /* Associated RTT */
u32 end_seq; /* Ending TCP sequence of the skb */
u32 last_delivered; /* tp->delivered at last reo_wnd adj */
u8 reo_wnd_steps; /* Allowed reordering window */
#define TCP_RACK_RECOVERY_THRESH 16
u8 reo_wnd_persist:5, /* No. of recovery since last adj */
dsack_seen:1, /* Whether DSACK seen after last adj */
advanced:1, /* mstamp advanced since last lost marking */
reord:1; /* reordering detected */
} rack;
u16 advmss; /* Advertised MSS */
u32 chrono_start; /* Start time in jiffies of a TCP chrono */
u32 chrono_stat[3]; /* Time in jiffies for chrono_stat stats */
u8 chrono_type:2, /* current chronograph type */
rate_app_limited:1, /* rate_{delivered,interval_us} limited? */
fastopen_connect:1, /* FASTOPEN_CONNECT sockopt */
is_sack_reneg:1, /* in recovery from loss with SACK reneg? */
unused:2;
u8 nonagle : 4,/* Disable Nagle algorithm? */
thin_lto : 1,/* Use linear timeouts for thin streams */
unused1 : 1,
repair : 1,
frto : 1;/* F-RTO (RFC5682) activated in CA_Loss */
u8 repair_queue;
u8 syn_data:1, /* SYN includes data */
syn_fastopen:1, /* SYN includes Fast Open option */
syn_fastopen_exp:1,/* SYN includes Fast Open exp. option */
syn_fastopen_ch:1, /* Active TFO re-enabling probe */
syn_data_acked:1,/* data in SYN is acked by SYN-ACK */
save_syn:1, /* Save headers of SYN packet */
is_cwnd_limited:1,/* forward progress limited by snd_cwnd? */
syn_smc:1; /* SYN includes SMC */
u32 tlp_high_seq; /* snd_nxt at the time of TLP retransmit. */
/* RTT measurement */
u64 tcp_mstamp; /* most recent packet received/sent */
u32 srtt_us; /* smoothed round trip time << 3 in usecs */
u32 mdev_us; /* medium deviation */
u32 mdev_max_us; /* maximal mdev for the last rtt period */
u32 rttvar_us; /* smoothed mdev_max */
u32 rtt_seq; /* sequence number to update rttvar */
struct minmax rtt_min;
u32 packets_out; /* Packets which are "in flight" */
u32 retrans_out; /* Retransmitted packets out */
u32 max_packets_out; /* max packets_out in last window */
u32 max_packets_seq; /* right edge of max_packets_out flight */
u16 urg_data; /* Saved octet of OOB data and control flags */
u8 ecn_flags; /* ECN status bits. */
u8 keepalive_probes; /* num of allowed keep alive probes */
u32 reordering; /* Packet reordering metric. */
u32 snd_up; /* Urgent pointer */
/*
* Options received (usually on last packet, some only on SYN packets).
*/
struct tcp_options_received rx_opt;
/*
* Slow start and congestion control (see also Nagle, and Karn & Partridge)
*/
u32 snd_ssthresh; /* Slow start size threshold */
u32 snd_cwnd; /* Sending congestion window */
u32 snd_cwnd_cnt; /* Linear increase counter */
u32 snd_cwnd_clamp; /* Do not allow snd_cwnd to grow above this */
u32 snd_cwnd_used;
u32 snd_cwnd_stamp;
u32 prior_cwnd; /* cwnd right before starting loss recovery */
u32 prr_delivered; /* Number of newly delivered packets to
* receiver in Recovery. */
u32 prr_out; /* Total number of pkts sent during Recovery. */
u32 delivered; /* Total data packets delivered incl. rexmits */
u32 lost; /* Total data packets lost incl. rexmits */
u32 app_limited; /* limited until "delivered" reaches this val */
u64 first_tx_mstamp; /* start of window send phase */
u64 delivered_mstamp; /* time we reached "delivered" */
u32 rate_delivered; /* saved rate sample: packets delivered */
u32 rate_interval_us; /* saved rate sample: time elapsed */
u32 rcv_wnd; /* Current receiver window */
u32 write_seq; /* Tail(+1) of data held in tcp send buffer */
struct hrtimer pacing_timer;
/* from STCP, retrans queue hinting */
struct sk_buff* lost_skb_hint;
struct sk_buff *retransmit_skb_hint;
/* OOO segments go in this rbtree. Socket lock must be held. */
struct rb_root out_of_order_queue;
struct sk_buff *ooo_last_skb; /* cache rb_last(out_of_order_queue) */
/* SACKs data, these 2 need to be together (see tcp_options_write) */
struct tcp_sack_block duplicate_sack[1]; /* D-SACK block */
struct tcp_sack_block selective_acks[4]; /* The SACKS themselves*/
struct tcp_sack_block recv_sack_cache[4];
struct sk_buff *highest_sack; /* skb just after the highest
* skb with SACKed bit set
* (validity guaranteed only if
* sacked_out > 0)
*/
int lost_cnt_hint;
u32 prior_ssthresh; /* ssthresh saved at recovery start */
u32 high_seq; /* snd_nxt at onset of congestion */
u32 retrans_stamp; /* Timestamp of the last retransmit,
* also used in SYN-SENT to remember stamp of
* the first SYN. */
u32 undo_marker; /* snd_una upon a new recovery episode. */
int undo_retrans; /* number of undoable retransmissions. */
u32 total_retrans; /* Total retransmits for entire connection */
u32 urg_seq; /* Seq of received urgent pointer */
int linger2;
/* Sock_ops bpf program related variables */
#ifdef CONFIG_BPF
u8 bpf_sock_ops_cb_flags; /* Control calling BPF programs
* values defined in uapi/linux/tcp.h
*/
#define BPF_SOCK_OPS_TEST_FLAG(TP, ARG) (TP->bpf_sock_ops_cb_flags & ARG)
#else
#define BPF_SOCK_OPS_TEST_FLAG(TP, ARG) 0
#endif
/* Receiver side RTT estimation */
struct {
u32 rtt_us;
u32 seq;
u64 time;
} rcv_rtt_est;
/* Receiver queue space */
struct {
u32 space;
u32 seq;
u64 time;
} rcvq_space;
/* TCP-specific MTU probe information. */
struct {
u32 probe_seq_start;
u32 probe_seq_end;
} mtu_probe;
u32 mtu_info; /* We received an ICMP_FRAG_NEEDED / ICMPV6_PKT_TOOBIG
* while socket was owned by user.
*/
#ifdef CONFIG_TCP_MD5SIG
/* TCP AF-Specific parts; only used by MD5 Signature support so far */
const struct tcp_sock_af_ops *af_specific;
/* TCP MD5 Signature Option information */
struct tcp_md5sig_info __rcu *md5sig_info;
#endif
/* TCP fastopen related information */
struct tcp_fastopen_request *fastopen_req;
/* fastopen_rsk points to request_sock that resulted in this big
* socket. Used to retransmit SYNACKs etc.
*/
struct request_sock *fastopen_rsk;
u32 *saved_syn;
};
struct inet_timewait_sock
struct tcp_timewait_sock
在struct inet_timewait_sock的基础上进行扩展
struct inet_request_sock
在struct inet_request_sock的基础上进行扩展
客户端发送TCP链接请求的端口,也就是后续建立TCP链接使用的端口,所以一旦TCP链接建立,端口就被占用,无法再建立第二个链接
而服务器端有两类端口:侦听端口 和 后续建立TCP链接的端口。其中侦听端口只负责侦听客户端发送来的TCP链接请求,不用作建立TCP链接使用,一旦侦听到有客户端发送TCP链接请求,就分配一个端口(一般随机分配,且不会重复)用于建立TCP链接,而不是所说的服务器一个端口能建立多个连接。
原始结构体地址
struct sockaddr_in
typedef unsigned short sa_family_t;
// Internet Address
struct in_addr{
__b32 s_addr;
}
//struct describing an Internet socket address
//sockaddr_in 中存放端口号、网路层中的协议类型(ipv4,ipv6)等,网络层的IP地址;
struct sockaddr_in
{
sa_family_t sin_family ; // Address family AF_XXX
__be16 sin_port ; // 端口号
struct in_addr sin_addr ; // Internet Address
/*Pad to size of 'struct sockaddr'*/
...........
};
struct sockaddr;
套接字地址结构
struct` `sockaddr
{
``sa_family_t sa_family; ``// 存放网络层所使用的协议类型(AF_XXX 或 PF_XXX);
``char` `sa_data[14]; ``// 里面存放端口号、网络层地址等信息;
}
从本质上来说,struct sockaddr与struct sockaddr_in是相同的。
但在,实际的使用过程中,struct sockaddr_in是 Internet环境下的套接字地址形式,而struct sockaddr是通过的套接字地址个形式。在linux内核中struct sockaddr使用的更多,目的是使linux内核代码更为通用。
struct sockaddr_in 可以与 struct sockaddr 进行自由的转换
初始化操作(文件操作)
1、socket与sockaddr进行绑定
int kernel_bind(struct socket *sock, struct sockaddr *addr,
int addrlen)
EXPROT_SYMBOL(kernel_bind);
sock : 为通过sock_create()或sock_create_kern()创建的套接字;
addr : 为套接字地址结构体;
addrlen:为套接字地址结构体的大小;
2、将一个套接字(socket)设置为监听状态
int kernel_listen(struct socket *sock, int backlog);
backlog :一般情况下设置为0;
EXPORT_SYMBOL(kernel_listen);
3、将一个套接字设置为监听状态
int kernel_listen(struct socket *sock, int backlog);
backlog :一般情况下设置为0;
EXPORT_SYMBOL(kernel_listen);
4、当把一个套接字设置为监听状态以后,使用这个套接字去监听其他的套接字
int kernel_accept(struct socket *sock, struct socket **new_sock,
int flags);
EXPORT_SYMBOL(kernel_accept);
sock : listening socket 处于监听状态的套接字;
new_sock : 被监听的套接字;
flags: struct socket中的flags字段的取值;
5、把一个套接字连接到另一个套接字地址结构上
int kernel_connect(struc socket *sock, struct sockaddr *addr,
int addrlen, int flags);
EXPORT_SYMBOL(kernel_connect);
sock : struct socket;
addr : 为另一个新的套接字地址结构体;
addrlen : 套接字地址结构体的大小;
flags :file-related flags associated with socket
6、数据收发
int kernel_sendmsg(struct socket *sock, struct msghdr *msg,
struct kvec *vec, size_t num, size_t size)
EXPORT_SYMBOL(kernel_sendmsg);
sock : 为当前进程中的struct socket套接字;
msg : 用于接收来自应用层的数据包;
kvec : 中存放将要发送出去的数据;
num : 见代码;
size : 为将要发送的数据的长度;
struct iovec
{
void __user *iov_base;
__kernel_size_t iov_len;
}
struct msghdr
{
//用于存放目的进程所使用的套接字地址
void *msg_name; // 用于存放目的进程的struct sockaddr_in
int msg_namelen; // 目的进程的sizeof(struct sockaddr_in)
//用于来自应用层的数据
struct iovec *msg_iov ;// 指向一个struct iovec的数组,数组中的每个成员表示一个数据块
__kernel_size_t msg_iovlen ; //数据块数,即struct iovec数组的大小
//用于存放一些控制信息
void *msg_control ;
__kernel_size_t msg_controllen; //控制信息的长度;
//
int msg_flags;
}
struct kvec
{
void *iov_base; //用于存放来自应用层的数据;
size_t iov_len; //来自应用层的数据的长度;
}
发送函数
int kernel_sendmsg(struct socket *sock, struct msghdr *msg,
struct kvec *vec, size_t num, size_t size)
{
iov_iter_kvec(&msg->msg_iter, WRITE | ITER_KVEC, vec, num, size);
return sock_sendmsg(sock, msg);
}
EXPORT_SYMBOL(kernel_sendmsg);
有kernel_sendmsg()的实现代码可知,struct kvec中的数据部分最终还是要放到struct msghdr之中去的
int sock_sendmsg(struct socket *sock, struct msghdr *msg,
size_t size);
EXPORT_SYMBOL(sock_sendmsg);
用法
static int
ip_vs_send_async(struct socket *sock, const char *buffer, const size_t length)
{
struct msghdr msg = {.msg_flags = MSG_DONTWAIT|MSG_NOSIGNAL};
struct kvec iov;
int len;
EnterFunction(7);
iov.iov_base = (void *)buffer;
iov.iov_len = length;
len = kernel_sendmsg(sock, &msg, &iov, 1, (size_t)(length));
LeaveFunction(7);
return len;
}
接收网络进程中的数据
int kernel_recvmsg(struct socket *sock, struct msghdr *msg,
struct kvec *vec, size_t num, size_t size, int flags)
EXPORT_SYMBOL(kernel_recvmsg);
sock : 为接受进程的套接字;
msg : 用于存放接受到的数据;
vec : 用于指向本地进程中的缓存区;
num : 为数据块的块数;
size : 缓存区的大小;
flags: struct msghdr中的flags字段中的取值范围
int kernel_recvmsg(struct socket *sock, struct msghdr *msg,
struct kvec *vec, size_t num, size_t size, int flags)
{
mm_segment_t oldfs = get_fs();
int result;
iov_iter_kvec(&msg->msg_iter, READ | ITER_KVEC, vec, num, size);
set_fs(KERNEL_DS);
result = sock_recvmsg(sock, msg, flags);
set_fs(oldfs);
return result;
}
EXPORT_SYMBOL(kernel_recvmsg);
用法
static int svc_udp_recvfrom(struct svc_rqst *rqstp)
{
struct svc_sock *svsk =
container_of(rqstp->rq_xprt, struct svc_sock, sk_xprt);
struct svc_serv *serv = svsk->sk_xprt.xpt_server;
struct sk_buff *skb;
union {
struct cmsghdr hdr;
long all[SVC_PKTINFO_SPACE / sizeof(long)];
} buffer;
struct cmsghdr *cmh = &buffer.hdr;
struct msghdr msg = {
.msg_name = svc_addr(rqstp),
.msg_control = cmh,
.msg_controllen = sizeof(buffer),
.msg_flags = MSG_DONTWAIT,
int err;
if (test_and_clear_bit(XPT_CHNGBUF, &svsk->sk_xprt.xpt_flags))
/* udp sockets need large rcvbuf as all pending
* requests are still in that buffer. sndbuf must
* also be large enough that there is enough space
* for one reply per thread. We count all threads
* which will access the socket.
*/
svc_sock_setbufsize(svsk->sk_sock,
(serv->sv_nrthreads+3) * serv->sv_max_mesg,
(serv->sv_nrthreads+3) * serv->sv_max_mesg);
clear_bit(XPT_DATA, &svsk->sk_xprt.xpt_flags);
skb = NULL;
err = kernel_recvmsg(svsk->sk_sock, &msg, NULL,
0, 0, MSG_PEEK | MSG_DONTWAIT);
if (err >= 0)
skb = skb_recv_udp(svsk->sk_sk, 0, 1, &err);
if (skb == NULL) {
if (err != -EAGAIN) {
/* possibly an icmp error */
dprintk("svc: recvfrom returned error %d\n", -err);
set_bit(XPT_DATA, &svsk->sk_xprt.xpt_flags);
}
return 0;
}
len = svc_addr_len(svc_addr(rqstp));
rqstp->rq_addrlen = len;
if (skb->tstamp == 0) {
skb->tstamp = ktime_get_real();
/* Don't enable netstamp, sunrpc doesn't
need that much accuracy */
}
svsk->sk_sk->sk_stamp = skb->tstamp;
len = skb->len;
rqstp->rq_arg.len = len;
rqstp->rq_prot = IPPROTO_UDP;
if (!svc_udp_get_dest_address(rqstp, cmh)) {
cmh->cmsg_level, cmh->cmsg_type);
goto out_free;
}
rqstp->rq_daddrlen = svc_addr_len(svc_daddr(rqstp));
if (skb_is_nonlinear(skb)) {
/* we have to copy */
local_bh_disable();
if (csum_partial_copy_to_xdr(&rqstp->rq_arg, skb)) {
local_bh_enable();
/* checksum error */
goto out_free;
}
local_bh_enable();
consume_skb(skb);
} else {
/* we can use it in-place */
rqstp->rq_arg.head[0].iov_base = skb->data;
rqstp->rq_arg.head[0].iov_len = len;
if (skb_checksum_complete(skb))
goto out_free;
rqstp->rq_xprt_ctxt = skb;
}
rqstp->rq_arg.page_base = 0;
if (len <= rqstp->rq_arg.head[0].iov_len) {
rqstp->rq_arg.head[0].iov_len = len;
rqstp->rq_arg.page_len = 0;
rqstp->rq_respages = rqstp->rq_pages+1;
} else {
rqstp->rq_arg.page_len = len - rqstp->rq_arg.head[0].iov_len;
rqstp->rq_respages = rqstp->rq_pages + 1 +
DIV_ROUND_UP(rqstp->rq_arg.page_len, PAGE_SIZE);
}
rqstp->rq_next_page = rqstp->rq_respages+1;
if (serv->sv_stats)
serv->sv_stats->netudpcnt++;
return len;
out_free:
kfree_skb(skb);
return 0;
}
关闭一个套接字
8.关闭一个套接字:
void sock_release(struct socket *sock);
用于关闭一个套接字,并且如果一个它struct socket绑定到了一个struct
inode节点上的话,相应的struct inode也会被释放
文件socket.c
tp));
if (skb_is_nonlinear(skb)) {
/* we have to copy */
local_bh_disable();
if (csum_partial_copy_to_xdr(&rqstp->rq_arg, skb)) {
local_bh_enable();
/* checksum error */
goto out_free;
}
local_bh_enable();
consume_skb(skb);
} else {
/* we can use it in-place */
rqstp->rq_arg.head[0].iov_base = skb->data;
rqstp->rq_arg.head[0].iov_len = len;
if (skb_checksum_complete(skb))
goto out_free;
rqstp->rq_xprt_ctxt = skb;
}
rqstp->rq_arg.page_base = 0;
if (len <= rqstp->rq_arg.head[0].iov_len) {
rqstp->rq_arg.head[0].iov_len = len;
rqstp->rq_arg.page_len = 0;
rqstp->rq_respages = rqstp->rq_pages+1;
} else {
rqstp->rq_arg.page_len = len - rqstp->rq_arg.head[0].iov_len;
rqstp->rq_respages = rqstp->rq_pages + 1 +
DIV_ROUND_UP(rqstp->rq_arg.page_len, PAGE_SIZE);
}
rqstp->rq_next_page = rqstp->rq_respages+1;
if (serv->sv_stats)
serv->sv_stats->netudpcnt++;
return len;
out_free:
kfree_skb(skb);
return 0;
}
关闭一个套接字
**8.关闭一个套接字:**
**void sock_release(struct socket \*sock);**
**用于关闭一个套接字,并且如果一个它struct socket绑定到了一个struct**
**inode节点上的话,相应的struct inode也会被释放**
文件socket.c















 917
917











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









