






这几天听Di哥的推荐在看Java并发编程的艺术这本书.索性把读书笔记也写到博客里...
1并发编程的挑战
(上下文切换,死锁,资源限制)
(1)
上下文切换的挑战
○用并行执行和串行执行的小实验对比证明并行并不是一定比串行快的,这里我也自己写了一遍书中的代码并亲自测试了一下.先贴代码和结果.
package test;
public class testConcurrencyAndSerial {
static long count = 1000000L;
public static void concurrency() throws InterruptedException {
long start = System.currentTimeMillis();
Thread thread = new Thread(() -> {
long a = 0;
for (long i = 0; i < count; i++) {
a += 5;
}
});
thread.start();
long b = 0;
for (long i = 0; i < count; i++) {
b--;
}
thread.join();
long end = System.currentTimeMillis();
System.out.println("con time" + (end - start) + " a b" + " " + b);
}
public static void serial() {
long start = System.currentTimeMillis();
long a = 0;
for (long i = 0; i < count; i++) {
a += 5;
}
long b = 0;
for (long i = 0; i < count; i++) {
b--;
}
long end = System.currentTimeMillis();
System.out.println("serial time" + (end - start) + " a b" + a + " " + b);
}
public static void main(String[] args) throws InterruptedException {
concurrency();
serial();
}
}
其中 最后的数字是count 前面是时间 可以清晰的看出 并不是所有情况都是多线程快的.
可以用lmbench测量上下文切换时长 使用vmstat测量上下文切换的次数 (留flag 装完虚拟机拿来玩一下)
减少上下文切换:无锁并发编程 CAS算法 使用最少线程 使用携程
无锁并发编程:多线程竞争锁会导致上下文切换,可以想办法替代锁,比如将数据的ID按hash算法取模分段,不同的线程处理不同段的数据.
CAS算法:Java的Atomic包使用CAS算法更新数据不用加锁(其实就是拿主存中的值和副本比 相等就修改 不相等就不改)AtomicInteger类中有valueOffset value expect update
使用最少线程:避免大量线程处于等待状态
协程:单线程实现多任务调度 在单线程中维持多个任务的调度
减少切换线程实战1.1.4(留flag 要做)
(2)
死锁
死锁代码展示,我也试着写了一个.
package test;
public class DeadLock {
static String A="1";
static String B="2";
public static void main(String[] args) {
new DeadLock().showDeadLock();
}
public void starta(){
Thread thread=new Thread(()->{
synchronized (A){
System.out.println("a has A");
try{
Thread.currentThread().sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
synchronized (B){
System.out.println("i can do it");
}
}
});
thread.start();
}
public void startb(){
Thread thread=new Thread(()->{
synchronized (B){
System.out.println("b has B");
try{
Thread.currentThread().sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
synchronized (A){
System.out.println("i can do it");
}
}
});
thread.start();
}
private void showDeadLock() {
starta();
startb();
}
}避免死锁: 避免在一个线程中获取多个锁 避免在一个锁中获取多个资源 使用定时锁 加解锁在同一个数据库连接中
(3)
资源限制
并发时由于资源受限,如下载的带宽 也包含软件资源如Socket连接数和数据库连接数
若受资源限制导致并发变串行会更慢 因为有上下文的切换
硬件限制改硬件,用hadoop或自己搭建服务器集群
软件限制考虑软件资源复用 将socket和数据库连接复用
2java并发机制的底层实现原理
(volatile synchronized)
(1)
volatile
volatile是轻量级的synchrond 它在多处理器开发中保证了共享变量的可见性.volatile比synchronized成本低 不引起线程上下文切换和调度,下面分析在硬件上如何实现的volatile
定义:为确保共享变量准确和一致更新,线程应该确保通过排他锁单独获取这个变量.java线程内存模型保证所有线程看到这个变量的值一致.
术语:memory barriers实现对内存操作的顺序限制 cache line缓存可以分配的最小单位
X86下通过获取JIT生成的汇编指令查看volatile变量被赋值(这里我的老是无法正确bi生成汇编指令 明天去问下d哥东伟哥炳杰哥富豪哥和阿昌哥)
先贴书里的汇编
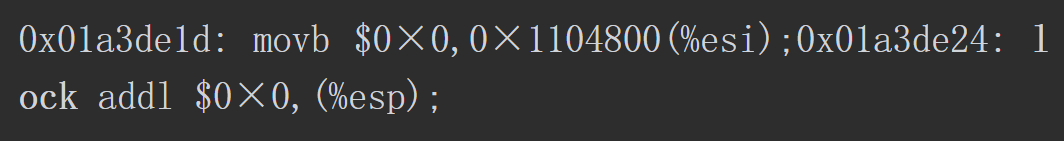
指令前被加了lock,查IA-32架构软件开发者手册(明天整一本瞅瞅),作者知道了Lock前缀指令在多核处理器下引发两件事:将当前处理器缓存行数据写回系统内存 ,这个写会内存操作使其它CPU里缓存了该内存地址的数据无效.
这里作者还写了一段操作系统中的知识,应该是怕读者操作系统课走神没听缓存(为了提高处理速度,cpu快 读内存慢 中间搞点高速缓存,因为很多时候访问的数据就在访问过的地方附近),声明volatile之后如果更新值,JVM加Lock指令,让变量所在缓存行回写内存,为了防止已经读了该变量的处理器乱来实现了缓存一致性协议.:每个处理器嗅探总线上传播的数据检查自己缓存的值是不是过期了,当处理器发现自己缓存行对应内存地址修改,就将当前处理器缓存行设置无效.然后修改的话就重读
LOCK前缀引起处理器缓存回写内存:Lock前缀指令导致指令执行期间 声言处理器的Lock#信号 多处理器环境中 Lock#信号确保声言该信号期间 处理器独占任何共享内存.在最近的处理器中不锁总线 锁缓存 Intel486和pentium总是在总线上声言Lock信号 如果已经缓存 P6和目前的处理器锁定这块内存区域的缓存并回写内存 使用缓存一致性机制确保阻止同时修改两个以上处理器缓存的数据
一个处理器的缓存回写内存会导致其它处理器的缓存无效IA32和Intel64处理器使用MESI控制协议去维护内部缓存和其它处理器缓存的一致性.
volatile的使用优化
大佬Doug lea在JDK7中新增了一个队列集合类Linked-TransferQueue,它使用volatile变量时,用增加字节的方式来优化出入队列的性能.其实就是增加了十五个变量变成了64字节,因为许多处理器的L1L2L3高速缓存是64字节宽 不支持部分填充缓存行 如果不添加字节的话很多节点会被丢到同一缓存行中 而volatile又会导致整个缓存行被锁定 而多线程情况下队列出入队经常修改头尾节点,因此影响效率.
当然 如果缓存行不是64 或者本来就不存在高频繁读写就不应该这么做了
(2)
synchronized
实现原理与应用
对于普通同步方法 锁是当前实例对象
对于静态同步方法 锁是当前类的class对象
对于同步方法快 锁是synchronized 括号里配置的对象
锁存在哪里 锁里存什么信息
synchronized用的锁是存在对象头中的,这里需要看一下Hotspot中java对象的内存模型。
MarkWord—》(size)-》class指针-》对象实际数据-》(字节对齐)
数组的对象头是12字节(3字宽)就是size的原因
其中这里关注的是MarkWord 它不是一个固定的数据结构 它可以动态的去代表重锁 轻锁 偏向锁 无锁 GC等
对于锁的内容来说
JVM基于进入退出Monitor对象实现方法同步和代码块同步
代码块同步是使用monitorenter和monitorexit实现
方法同步是另外一种规范
monitorenter插入同步代码块开始位置
monitorexit插入方法结束处和异常处
monitor被持有之后进入锁定状态
然后看锁的特点
首先是偏向锁 统计发现 很多情况下锁都由同一线程获得,这种情况下频繁加解锁造成了浪费,因此设计了偏向锁,使用时,当一个线程访问同步块时,会在相应对象头和栈帧中的锁记录(了解)存锁偏向的线程id,以后线程进入同步块只需验证对象头中偏向的线程id是不是自己。
是,则获得锁
不是,则检查MarkWord中偏向锁是否设置成1,不是则CAS竞争锁,是则尝试将它指向自己
轻量锁加锁,首先线程在栈帧中开辟锁记录空间,然后复制对象头中的markword到锁记录中,然后尝试CAS将对象头中的MarkWord替换为指向栈帧中锁记录的指针,成功则获得,失败则自旋
轻量锁解锁,尝试CAS将栈帧中MarkWord替换回对象头中,成功解锁,失败说明有竞争,升级为重量锁(这里很多人对轻量锁是否存在抢夺时自旋存在争议 mark一下读一下源码解决一下)
实现原子操作
1.锁总线,多个处理器进行i++操作的经典场景,是因为多个cpu的不同缓存导致的,因此可以通过cpu 在总线声言Lock#信号从而独占共享内存实现原子操作
2.锁缓存,频繁使用的内存回缓存在L1L2L3中因此原子操作可以直接在缓存中进行,内存区域如果被缓存且在Lock处理期间被锁定(这里要专门看一眼lock# lock)则执行锁操作回写内存时,不声言Lock#信号,而修改内部的内存地址并允许它的缓存一致性保证操作原子性,其它处理器回写缓存行时会让缓存行无效。
操作数据跨多缓存行/无法缓存时 无法使用锁缓存 不支持缓存锁定无法锁缓存
循环cas实现原子操作















 1120
1120











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









