







总览:
无论是现今的大数据还是企业内部的小数据,都存在一些普遍的问题,如数据格式不对需要转换,一个单元格内包含多个含义的内容,包含重复项等等,虽然我们也可以使用excel解决,但是excel天生有诸多限制,比如其为直接对数据进行操作,容易导致误操作;数据量大会处理缓慢;透视表功能太过简单;无法进行高级的数据分类分析。而OpenRefine很好的解决了以上问题,最重要的一点是它还是免费的!!
附:
英文原著下载链接:http://pan.baidu.com/s/1mi3FkO4
OpenRefine2.7安装包:http://pan.baidu.com/s/1jIzF2HC
英文原著随书源码示例文件:http://pan.baidu.com/s/1gfcfb7l
注意:直接访问官方网站是无法访问的,因为被墙了,所以如果想访问,就只能某宝上买个翻墙软件,现在淘宝也在封关键词,我试了下,搜vp能够找到大笑
《使用OpenRefine》
目录
第一章:初识OpenRefine 5
介绍OpenRefine 5
要点1:安装OpenRefine 6
WINDOWS 7
MAC 7
LINUX 7
要点2:创建一个新项目 7
OpenRefine支持的文件类型 9
要点3:探索数据 10
要点4:操纵列 11
列隐藏和展开 11
移动列 12
重命名或删除列 13
要点5:使用项目操作历史 14
要点6:导出项目 16
要点7:获取更多的运行内存 18
Windows 18
Mac 18
Linux 18
小结 19
第二章:分析和修改数据 19
点1-数据排序 20
对行进行重新排序 22
点2-数据透视 22
文本透视 23
数字透视 25
定制透视 28
对标星和标旗行进行透视 31
点3-重复检测 31
点4-应用一个文本过滤 34
点5-使用简单单元格转换 35
点6-删除匹配行 38
小结 41
第三章:高级数据操作 41
点1:对多值单元格的处理 41
点2:行模式和记录模式的转换 44
点3:相似单元格聚类 47
点4:单元格值转换 50
点5:增加源列 53
点6:拆分列 54
点7:行列转换 56
小结 58
第四章:数据集关联 59
•点1-使用Freebase解析值 59
•点2-安装扩展包 63
•点3-增加解析服务 65
•点4-与关联数据进行解析 67
•点5-抽取单名称项 70
小结 73
第五章:正则表达式和GREL 74
对文本应用正则表达式 74
字符集 75
数量符 77
锚符 79
可选符 79
组符 80
小结 80
GREL 81
数据转换 82
创建自定义透视功能 83
GREL排障 85
第一章:初识OpenRefine
本章中,我们会说明OpenRefine是用来干什么的?为什么我们需要用它?并且怎么用它。简单介绍后,我们会通过七个基本小点让你初尝OpenRefine的魅力。
◎安装OpenRefine
◎创建一个项目
◎探索你的数据
◎操纵列
◎使用项目历史
◎输出项目
◎充分利用内存
虽然每个点都相对独立,我们还是建议新读者按照我们的顺序学习,最起码开始的几点需要如此,因为这几点中我们提供了软件操作的重要信息。有经验的高级读者可以按照自己喜欢自由选择。
介绍OpenRefine
我们需要承认这样一个事实:你的数据是不完美的,所有的数据都是不完美的。无论你多么小心地建立数据,错误总会偷偷溜进你的数据中。如果是多人共同创建或者已经几经转手,那么错误更加无法避免。无论你的数据本来就是数字化的,还是通过传统刊物数字化转换而来的,无论它们存储在excel表中还是数据库中,数据中的错误总是无法避免。
确认错误是保证数据质量的第一步,主要包括数据画像和数据清洗。
数据画像 Olson定义为:使用统计方法发现数据的结构、内容、质量。换句话说,这是一种对你的数据进行画像,预发现包含的错误信息的方法。
数据清洗 用半自动化的方式改正画像过程中发现的错误,比如:删除缺失和重复值、行过滤透视、值聚类及转换、单元格拆分等等。
鉴于后续章节都需要保证数据已经画像清洗过,数据转换工具(IDTS)能够快速廉价的在一个操作界面内处理大量的数据问题,即使处理人员缺乏专业技术背景,所以IDTS也就成为了首选。
OpenRefine就是这样一个IDTS工具,其能够对数据进行可视化操作处理。它很像传统的excel软件,但其工作方式更像数据库,因其并不是处理单独的单元格,而是处理列和字段。这意味着OpenRefine对于增加新行内容表现不佳,但对于探索、清洗、整合数据却功能强大。
第一章的要点介绍将帮助您熟悉OpenRefine的主要功能,从导入导出数据到数据探索,从历史操作使用到内存管理。
要点1:安装OpenRefine
本点中,您将学习如何下载最新版本的OpenRefine和如何在你喜欢的操作系统中运行软件。
让我们开始吧:请从http://OpenRefine.org下载软件,OpenRefine原来叫做Freebase Gridworks。后来几年使用名称为Google refine。2012年10月后,这个软件被社区接手,使其真正成为开源软件。
OpenRefine2.6是使用新名称后的第一个版本,如果你对开发版本感兴趣,可以访问:https://github.com/OpenRefine。
OpenRefine基于JAVA环境,也就是说和操作系统无关,你只需要保证你的电脑上安装了最新版的JAVA环境(可以到http://java.com/download下载),然后根据你的操作系统按对应步骤操作:
WINDOWS
1、下载zip压缩包
2、解压到指定文件夹
3、双击OpenRefine.exe运行
MAC
1、下载DMG压缩镜像文件
2、打开压缩镜像文件,把OpenRefine图标拖到程序文件夹
3、双击OpenRefine图标打开
LINUX
1、下载gzipped压缩包
2、解压到根目录
3、在命令行窗口输入./refine打开
我们需要了解,默认情况下,OpenRefine会分配1G内存给JAVA,处理小数据集是足够用了,但是处理大数据集就会捉襟见肘。在要点7:充分利用内存 中,我们会讨论如何让OpenRefine处理更大的数据,不同的操作系统有不同的方法。
要点2:创建一个新项目
在本点中,你会学到如何导入数据到OpenRefine,可以是新建一个项目并导入数据集,也可以是打开一个项目或者是导入别人创建的项目。
如果你按照 要点1 已经成功安装了OpenRefine并打开,你会发现OpenRefine是在你的默认浏览器中打开的,但是你需要知道:程序是在本地运行的,除了在本书附录中要使用额外功能(如正则表达式、openrefine内建函数语言GREL)外,你并不需要上因特网。在使用因特网时,请确保敏感数据不会被在线存储或分享。OpenRefine使用本地电脑的3333端口,这也意味着,你可以键入http://localhost:3333或http://127.0.0.1:3333打开软件。
以下是你第一次打开OpenRefine的界面:
左侧有三个标签页:
●Create Poject(创建项目):这个选项将载入一个数据集到OpenRefine中,这也是你第一次使用OpenRefine想要做的,如上图所示,有多种可选形式让你导入数据。
◎This Computer(本机):选择本机中存储的一个文件
◎Web Addresses(URLs)(网址):从在线资源导入数据
◎Clipboard(剪切板):通过复制-粘帖方式输入数据
◎Google Data(Google数据):从Google sheet或Fusion Table导入(这两个类似于excel,不过是在线的,所以需要有因特网连接)
●Open Project(打开一个项目):这个选项帮助你定位先前创建的项目,下次你打开OpenRefine,会出现一个已存在项目的列表,你可以选择一个继续先前的工作。
●Import Project(导入一个项目):使用这个选项,我们可以直接导入一个已有的OpenRefine存档,其可以让你打开别人创建的项目,并且包含项目创建后所有的数据操作记录。
OpenRefine支持的文件类型
以下是部分OpenRefine支持的文件格式:
●csv、tsv及其他*sv
●xls/xlsx、cdf、ods
●JSON
●XML
●行文本格式(比如log文件)
如果你需要打开其他格式文件,你可以通过OpenRefine扩展功能打开。
创建OpenRefine项目十分简单,只需要三步:选择文件、预览数据内容、确认创建。让我们通过点击“创建项目”标签页、选择数据集、点击下一步来创建新项目。
虽然我们鼓励你在OpenRefine中使用你自己的数据集,不过使用本书中的例子可能学习起来更高效。为了能够做到这点,案例中的数据均基于悉尼的PowerhouseMuseum组织,可以登录账户并在http://www.packtpub.com中下载(chapter1.tsv)学习,后续章节数据也可以下载获得,如何你是从其他地方购买本书,你也可以在http://www.packtpub.com/support注册并通过email获得本书数据。
下一步你会看到一个数据集预览界面,在右侧底部,你可以看到如下数据解析选项界面:
默认情况下,第一行数据会被解析为列名称,我们使用的Powerhouse数据集中的数据也显然符合首行为列名称。OpenRefine同时也会猜测单元格类型,给其赋予整数、日期、网址等等,这在你后续整理排列数据的时候十分有用(比如如果你将单元格设为文本格式,那么10就会排在2前面)
另一个选项是“引号在原数据中用来分隔列”选择项,如果选中,则原数据中引号用来分隔列,否则就需要去掉勾选框以使得OpenRefine能够正确读取。在Powerhouse数据集中,引号是用来表明物体名称和说明信息,所以此情况下,引号没有分隔列的意思:所以这里我们需要去掉勾选。剩下的选项在某些情况下需要设置,试着勾选或者去掉勾选来看看如何影响数据。另外,请确保编码正确,以使得显示正确。当所有都设置好后,点击创建项目来加载数据。
要点3:探索数据
本点中,你将通过查看数据界面的所有区域:总行数、不同的显示参数、列名称及菜单、实际单元格数据来探索数据。
一旦你的数据被加载,你将获得类似如下的界面内容:
上图中标明1~4的四个区域,我们按照顺序介绍:
1、总行数:如果你没有忘记去掉“引号有意义”选项(参照要点2-创建一个新项目),那么你会看到Powerhouse文件包含75814行数据。当数据按照某个参数进行过筛选,这里的显示会变成类似于找到123匹配行(总共75814行)。
2、显示选项:试着点击下,将行变成记录来查看区别,事实上变化并不大,只不过该区域显示为75814条记录而已。行数量一般情况下等于记录数量,但在后续情况中还是不一样的。该区域可以让你选择按5、10、25、50每页显示,并且你也可以在这里跳转页。
3、列名称及菜单:你会发现数据加载后的第一行被解析为列名称,在Powerhouse数据集中,列包含Record ID, Object Title, Registration Number等等(如果你在创建时去掉了“将第一行解析为列名称”的勾选,那么列名称区域会显示为Column1、Column2等等)
4、单元格内容:此处显示实际单元格数据
在开始剖析清理数据前,十分重要的一点是确保OpenRefine较好的载入显示了数据:查看列名称被解析正确(数据显示较宽时请使用水平滑动条)、单元格类型是否正确等等。将行显示项改为每页显示50条以查看数据不明显矛盾(理想情况下,你应该在创建项目前的预览界面时处理这些工作)。当你已经熟悉了操作界面,你就可以继续下一步了。
要点4:操纵列
本点中,你将学习列在OpenRefine如何隐藏和展开、按需要转换、以及重命名和删除。
列是OpenRefine中的基本元素:其是具有同一属性的成千上万的值的集合,可以按照很多方法查看处理。
列隐藏和展开
默认情况下,所有的列在OpenRefine中都是展开的,大都数情况下显得数据太冗长复杂了。如果你想暂时的隐藏一列或几列以方便观察操作,那么点击列下拉菜单,选择View,有四个可选项:
• Collapse this column隐藏这一列
• Collapse all other columns隐藏除该列外的所有列
• Collapse columns to left隐藏该列左边的所有列
• Collapse columns to right 隐藏该列右边的所有列
下图就是对Powerhouse数据集中Categories 列进行View|Collapse all other columns 处理后的结果。要重新展开列,只需要在列上点击一下。要展开所有以恢复到初始状态,参阅下点中的“移动列”
移动列
有时候改变原数据中列的顺序十分重要。比如,为了将两列放在一起比较。为了做到这点,选择需要处理的一列然后在列菜单中选择Edit column 。子菜单中会出现如下四种选项:
• Move column to beginning移动该列到开头
• Move column to end移动该列到结尾
• Move column to left向左移动该列
• Move column to right 向右移动该列
如果你对所有列操作,可以使用第一列名称为ALL的列。这一列可以使你同时操作多列。View菜单可以让你快速的隐藏和展开列。选择Edit columns|Re-order / remove columns… 可以通过通过拖动重新对列进行排列,还可以将将列拖动到右侧来去除该列,如下图所示:
重命名或删除列
在Edit column 菜单中,你还可以做到:
• Rename this column重命名列
• Remove this column 删除列
你可以使用重命名功能将Description 列标题中结尾的“.”删除。删除一列比隐藏一列来的彻底,但是就像你将在要点5:使用项目操作历史中学到,一切都是可以恢复原来的状态的。
要点5:使用项目操作历史
本点中,你将学习到如何返回到任一个项目历史操作点,并且学习如何在项目重新打开后查看历史操作信息。
OpenRefine一个特别有用的功能是可以在项目创建后保存所有的操作步骤。这也就意味着你不需要害怕做数据变换尝试:你可以随意按照自己的想法变换数据,因为一旦你发觉做错了(即使是几个月前做的),你也可以撤销该操作以恢复数据。
为了使用项目操作历史功能,请单击左侧顶部Facet / Filter 旁边的Undo / Redo 标签页,如下图所示:
为了恢复历史数据,单击你想保留的最近一个步骤操作。比如,为了取消上图第3步及以后的操作,可以单击第2步使其高亮显示,这样第3~5步就会变灰。这意味着选中项后的操作都将取消。如果点击第0步,那么所有操作都将取消。点击第4步,那么第3和第4步的操作将被执行,而第5步将撤销。
请注意,撤销某几步操作后再做出新的操作的话,原来的后续操作内容会丢失.比如,如果你从第5步回退到第2步,然后对Description 列执行左移操作,那么会显示第3步操作3. Move column description to position 1 ,而先前的灰色操作项(第3-5步)会丢失:因为我们不能在同时拥有两种互相矛盾的操作历史记录。记得多尝试下上面的步骤,省的以后带来严重的困扰。
记住,只有对数据有实际影响的操作才会出现在项目历史操作表中。数据透视比如:交换行列视角、在一页中改变显示数目、隐藏或展开列并不改变原来数据,所以也就不会出现在操作历史表中。以上操作也就无法随着项目信息传递:当你重新打开一个项目,无论原来是否隐藏,这时所有的列默认都是展开的,但是对于重命名列和删除列这类操作会出现在操作历史表中。在第二章,分析和修改数据中,我们会看到还有一些类型的操作会存在在操作历史表中:比如单元格和列的变换、但是过滤和透视操作则不会。
操作历史也可以以JSON格式导出,可以点击Undo / Redo页中的Extract…
,在打开界面中可以选择需要导出的步骤(注意只有通用的操作才能够导出,而对某个特定单元格的操作则无法导出)。上述操作能够获得JSON格式代码从而可以让你复制粘帖到他处。第1和第2步操作的代码如下:
[
{
“op”: “core/column-move”,
“description”: "Move column Registration Number to position
1",
“columnName”: “Registration Number”,
“index”: 1
},
{
“op”: “core/column-rename”,
“description”: “Rename column Description. to Description”,
“oldColumnName”: “Description.”,
“newColumnName”: “Description”
}
]
在上面代码中,op代表操作,description描述了具体操作是什么,余下的是操作用到的参数。我们可以点击Undo / Redo页中的Apply…按钮,然后将先前保存的JSON格式的操作代码粘帖上去,从而可以在不同的项目之间传递操作。最后,如果你已经有成百上千个操作记录,你可以在Filter输入框中输入字符来查找某个操作。比如输入remove或者rem就能够定位到第3步和第5步。
要点6:导出项目
本点中,我们将学习如何将修改后的数据用到其他项目中,包括将导出的格式定制为模板。
虽然你可能已经移动、重命名或者删除了列,但其实原始数据并没有被修改(也就是要点1:安装OpenRefine中的文件chapter1.tsv并没有被修改)。事实上,不像有些电子表格软件直接将改动写进文件,OpenRefine只是对数据文件的一份拷贝进行操作。因为存在这个保险措施,所以你在需要将数据导出分享或者嵌入其他应用程序时,你只需要在界面右上角点击Export按钮进行操作:
大部分弹出的选项能够让你将数据导出为常用格式,比如csv、tsv、excel和open document格式、还有不常用的RDF格式。让我们往下看:
• Export project: 这个选项能让你导出OpenRefine格式的压缩包,你可以用来和其他人共享或者仅仅用来备份。
• HTML table: 这个选项可以让你方便的将文件发布到互联网。
• Triple loader 和MQLWrite: 这个选项有一些扩展功能,能够让你将数据转换成支持Freeebase规则的样式(参照附录:正则表达式和GREL)
• Custom tabular exporter and templating:可能这是最吸引你的部分。OpenRefine可以让你对你的数据导出有更精细的控制,比如对列进行选择和排序、忽略空白行、正确选择日期格式以得到更有效的数据(参见附录:正则表达式和GREL)。如下图所示:
• Templating…为了获得更多的控制,你可以使用你自己的代码来限定格式,其会作用到所有的单元格。如代码cells[“Record ID”].value表示Record ID列的值,下面的代码表示将列值转换成JSON格式:
{
“Record ID” : {{jsonize(cells[“Record ID”].value)}},
“Object Title” : {{jsonize(cells["Object
Title"].value)}},
“Registration Number” : {{jsonize(cells["Registration
Number"].value)}},
"Description. " : {{jsonize
(cells["Description. "].value)}},
“Marks” : {{jsonize(cells[“Marks”].value)}},
“Production Date” : {{jsonize(cells["Production
Date"].value)}},
}
要点7:获取更多的运行内存
最后一点,我们将学习如何如何分配更多的运行内存以操作更大的数据集。
对于大数据集,你会发觉OpenRefine会运行缓慢或者提示内存不够。这表明你需要分配更多的内存给OpenRefine。和我们上面学习的内容相比,这个内容稍显复杂,因为这需要牵扯到一点底层修改。但是不要担心:我们会指导你如何去做。具体的操作步骤根据不同的操作系统有所不同。注意:你可以分配给OpenRefine多大内存取决于你的电脑和JAVA版本是32位还是64位。如果不清楚究竟需要分配多少才合适,就试着慢慢的增加运行内存数量来看看效果(如果每次增加1G)。
Windows
Windows平台,你可以在OpenRefine的文件夹中找到openrefine.l4j.ini文件,找到以-Xmx(对于JAVA来说表示最大内存数)开始的那行,默认情况下分配内存为1024M。稍稍改大点,比如2048M。保存后下次你打开OpenRefine就能够生效。
Mac
对于Mac平台就有点复杂,因为Mac电脑的操作系统将配置文件隐藏了。首先关闭OpenRefine,按住control键然后点击OpenRefine图标,在弹出菜单中选择Show package contents,然后在Contents文件夹中找到info.plist文件并打开,然后在其中找到VMOptions项(这就是JAVA虚拟机设置项)。找到以-Xmx开头的设置项,将默认的1024M按你的需要修改,比如-Xmx 2048M。
Linux
你可能会觉得奇怪,修改运行内存在Linux中十分简单,平时你打开OpenRefine是使用命令./refine,试着使用./refine –m 2048M。这里的2048M就是想分配的内存。如果你想永久的修改运行内存,你可以在根目录中找到隐藏文件.bashrc,然后在其中添加一个alias别名即可,代码如下:
alias refine=‘cd path_to_refine ; ./refine -m 2048M’
这里的path_to_refine是OpenRefine的安装目录,下次你依旧只需要使用./refine命令打开OpenRefine,其自动就会分配2048M内存。
小结
通过本章内容的学习,你已经了解了OpenRefine,一种新的具有数据画像、清洗、转换等等功能的工具,现在你已经在你的电脑上安装上了OpenRefine,并且已经了解如何在创建新项目中导入数据和如何在完成操作后导出数据。行、列的运行机制你也已经了解,并且已知道如何使用项目历史记录。另外你也对内存分配进行了操作,这能够让你操控更大的数据集。
虽然在开始操作你的数据集前好好的对你的数据进行全局性的观察十分重要,但你可能已经迫不及待了。如果是这样,那么你已经对第二章:分析和修改数据做好了准备,这章中,你将学习到如何分析和修改你的数据所需要的基本操作的方方面面。
第二章:分析和修改数据
本章中,我们将更加深入的学习OpenRefine的数据分析和修改功能,主要的内容包括下面六点:
*点1-数据排序
*点2-数据透视
*点3-重复检测
*点4-应用一个文本过滤
*点5-使用简单单元格转换
*点6-移除匹配行
和第一章:初识OpenRefine一样,本章可以让读者按照自己的需要或爱好选择阅读顺序,并不需要按照顺序阅读。按照顺序阅读也可以,但并不是必须的。
各个要点内容长短不一,有些很短,但有些却不止一两页,比如要点2-数据透视,包括了数据透视的方方面面,这个要点包括了很多页内容并且有很多子内容。
本章学习中,我们建议你使用Import Project 导入项目chapter2.openrefine.tar.gz 。当然你也可以使用第一章中使用的示例文件chapter1.tsv
点1-数据排序
本点中,我们将学习如何使用排序功能来作为观察数据的手段,以及在进一步处理数据前如何对行进行排序。
因为排过序的值更加容易理解和分析,某些时候你需要使用OpenRefine的排序功能,你可能是想用来观察下数据或者就是想对数据进行排序.我们以Record ID 列为例进行排序,选择列菜单中的Sort… ,将弹出如下窗口:
单元格值可以按照文本(区别大小写或者不区别)、数字、日期、布尔值排序,对每个 类别有两种不同的排序方式:
• Text: 文本:从a到z排序或者从z到a排序
• Numbers数字: 升序或者降序
• Dates: 日期升序或者日期降序
• Booleans: false值先于true值 或true值先于false值
还有我们可以对错误值和空值指定排序顺序。比如错误值可以排在最前面(这样容易发现问题),空值排在最后(因为空值一般没有意义),而有效值居中。
对Record ID列通过按数字升序排列为例,我们就会获得一列以7、9、14等等标识的列,而打开时是以267220、346260、 267098标识顺序的,下图对排序前后的情况做了比对:
如果按照Text: 文本排序的话,会得到以100、1001、10019开始的一列。同时应该关注的一点是:排序并不会被记录在项目操作历史中。你可以在屏幕左侧顶部的Undo / Redo 页中确认下。
那是因为排序并不会改变数据,其仅仅是改变了显示方式,比如行列互换、隐藏不想显示的列(就像excel的排序过滤功能)。所以每次对某列进行排序,你就会面对三种抉择:取消排序回到原来状态、暂时保持、永久改变。
你无法能在列菜单中做到上面三种要求,但是你可以在屏幕顶部的快捷菜单Sort来做到:
对行进行重新排序
Sort菜单可以让你移除排序操作或者永久对行进行排序。另外,该功能还能提醒你究竟对哪些列进行了排序,还能够对多列进行组合排列操作(见上图)。举个例子,你可以先对Registration Number排序,然后再对Object Title列排序,过会你还可以去掉按Registration Number排序的操作(通过菜单Sort | By Registration Number | Remove sort ),最后再将排序永久保存。每个排序的子菜单还能够通过点击一次来改变排序顺序(比如升序变降序) 。
记得如果你想将排序后的结果再进行后续操作,一定要将排序结果永久保存,比如对于空白单元格或者填充单元格,为了避免前后不一致的错误,在点3-重复检测中,我们将学习如何利用排序的预处理手段来移除重复值。
点2-数据透视
OpenRefine最常用的功能可能就是数据透视了。数据透视并不改变数据,但是可以让你获得数据集的有用信息。你可以把数据透视看作是多方面查看数据的方法,就像从不同的角度观察宝石一样。数据透视可以获得数据中一个变化后的子集,比如只显示某个参数要求下的行。
本点中,我们将学习如何按照你的要求或者数据具体的值来透视数据:对字符串进行文本透视、对数字和日期进行数字透视、几个预定义的透视功能、最后还有标星和标旗功能。OpenRefine的强大之处也在于这些透视功能的组合使用。
文本透视
如果你的数据集中包含城市或者国家名称的列,而你想大致了解下这个字段都有些什么值和这些值的统计次数有多少,那么就可以用文本透视。当然,只有该列中的类别总数不是特别大的时候文本透视才有用,因为文本透视并不是为了列出所有的信息,全部列出并没有多大意义,同时透视结果也不会出现相同的两个类别(除非又重复项,我们将在下一点中说明)
对于Powerhouse数据集中Categories列最适合做文本透视,其是从一个严格设计的词汇中选择(称为powerhouse museum object name thesaurus),简单来讲,Categories列包含了几千个常用事物的描述信息。
让我们试试看,点击Categories列菜单,选择Facet | Text facet ,结果会出现在屏幕左侧的Facet/Filter 页中。可惜的是,OpenRefine提醒我们总共有14,805个分类,已经超过了我们的电脑显示内存。事实上,透视不能超过2000个分类,当然你可以通过点击Set choice count limit设置成15000,但是这很可能将使得软件运行缓慢,特别是你哈没有改变JAVA内存分配数量(参见1初识OpenRefine中的要点7:获取更多的运行内存)
如果你选择提高弹出窗口中限制数的最小值,OpenRefine其实是改变了JAVA变量中ui.browsing.listFacet.limit 的值,但是大都数情况下你并不需要对这么复杂的值过多关注,其实提示窗口的出现也就意味着分类数太多了,需要减少。其实OpenRefine在超出时完全有办法提高限制数,但实际情况下往往我们想减少限制数的,太多的分类对于我们毫无意义。如果想这么做,可以访问系统参数:http://127.0.0.1:3333/preferences ,编辑ui.browsing.listFacet.limit,然后调低到想要的值。如果想恢复默认值2000,直接删掉这个值即可。
点击下面的Facet by choice counts 链接,将打开二级透视界面。新的透视也是对Categories的透视,这里可以让你对透视显示范围进行限定。当第一次打开的时候,OpenRefine会显示所有分类,无论分类数量只有1次还是有几千次。因为有太多的分类会被显示,所以一般开始的时候只显示数量较多的分类就比较有意义。
拖动左边的滑块从最小值0到1000,文本透视情况将自动更新,现在将只显示大于1000数量的Categories分类。这里只有7个,这就比先前大大减少了。为了观察方便,可以选择对count(计数项)排序(降序)来替代按字母排序。
下图显示你得到的透视图:
如果你想导出最多的7个分类名称,可以点击上图中的7 choices链接,会得到一个TSV格式的内容,你可以复制粘帖到你喜欢的文本编辑器或者电子表格软件中。然而你会觉得奇怪,比如Photographic prints|Photographs 并不是一个分类名称,其实包含两个分类,被“|”分开了。
这就是为什么我们第一次透视会出现这么多的分类。Glass plate negatives|Gelatin dry plate negatives|Photographs, Glass plate negatives|Photographs和Glass plate negatives被区分为不同的分类,但是其实他们都属于一个分类。这就是多义单元格的困扰,我们现在暂不去管这个问题,我们将在第三章:高级数据操作学习,第三章我们还将学习一个有趣的按钮Cluster,因为现在我们刚开始学习,所以现在我们暂且忽略。
因为对于Categories列的 透视 看上去 不是特别整齐,让我们在对数值列进行透视前来看看另一个文本透视操作。Height虽然并不是特别明显,但是我们也可以看到这个列并不仅仅包括数值,比如还有一些带单位的数字990mm,这意味着我们不能使用数值透视(最起码不能直接用),但是我们可以试试文本透视,希望能够看出端倪。
幸运的是,我们在对Hight列进行透视操作(Facet| Text facet)时,我们发现只有1313个分类,低于2000限制数,用count代替name排序,我们发现164mm的数量有1368,而第二位的215mm只有400,如下图所示:
在上图列表底部,我们可以看到Hight列中空值有45501,也就是说这些值缺失。但是我们将不在这里处理,因为OpenRefine提供了一个处理空值的透视功能,我们将在下面说明定制透视时说明。
数字透视
找到一个列可以用来做数字透视比文本透视简单,因为数据中往往包含许多数字,如果你在项目导入时勾选Parse cell text into numbers, dates…,那么数字也可以通过绿色来快速识别。本例中Record ID就是个很好的例子,通过对其透视可以看出ID的分布,并且可以看出是否每条记录都有一个ID。
点击Record ID列菜单,选择Facet | Numeric facet,然后看看左侧Facet/Filter页出现了什么。文本透视会返回一个不同分类数量的列表,而数字透视则是某个数值范围的分布,就像我们通过频数来透视一样。
我们可以看到Record ID的值域从0到510,000,在270,000至280,000之间有个小缺口,在410,000至500,000有个大缺口。通过滑动滑块,我们可以看出有533行的值大于500,000。
在图的下方,我们可以看到值类型被分成四种:Numeric, Non-numeric,Blank和 Errors。这是因为一些错误所导致的。在我们操作前可以看到Errors(错误值)为0,blanks(空值)数也是0,说明每一行都被分配了一个ID,有三行的值为Non-numeric(非数字),不能用作ID。让我们只勾选Non-numeric来看看情况。
现在右侧我们能够看到这三行的内容了。这三行不光ID缺失,其他很多列也是空白,除了persistent link和license information列,但是这些信息也是自动产生的。这几行并没有什么实际意义,所以我们可以删除(本章最后内容会介绍为什么会产生)
但是这里有个问题,如果这三行ID确实为空,那么为什么会被分类到Non-numeric,而不是分类到Blank?其实是空格导致的,我们可以通过编辑这几个单元格来验证。我们可以将鼠标移到单元格上,会出现edit标记,点击进入你就会看到包含一个单独的空格,如下图所示:
为了改正这个错误,可以单击Backspace或Delete键删除这个空格,然后点击Apply to All Identical Cells 按钮或者按Ctrl_Enter。OpenRefne 会弹出一个黄框提示你有多个Record ID 列值被修改。最后,左侧的透视图会自动刷新,有问题的三行也会归到Black分类。
在我们学习定制透视技术前,让我们快速学习下和数字透视相关的两种透视方法:时间轴透视和散点图透视。
时间轴透视要求数据为日期格式,所以类似17/10/1890 的文本字符串需要改为日期格式。你可以用Production Date 列练手,但是请注意,真实的时间很少是确定的,比如仅仅包含年份的1984,或者一个时间范围如2006到2007.我们可以对某列做如下操作:Edit cells | Common transforms | To date
将79个单元格转换成日期格式。比如17/10/1890 会被转成1890-10-17T00:00:00Z ,其中这些0标识一天中的小时、分钟、秒。
很显然,79个单元格跟总数75,814比起来太少了,但是时间轴透视结果还是能够让我们了解到这些物品的生产日期起码跨度为1880年2月26日至1952年1月31日。虽然大部分值要么不是日期格式(19,820),要么是空白(55,915)。
下图显示了将Production Date 列转换成日期后的时间轴透视图:
最后,散点图透视能够让我们对值的图形分布作了解。我们不会对这点细节展开,你试试看就知道了。
定制透视
我们现在已经学习了两种主要的透视方法-文本透视和数字透视。但其实还有很多透视方法存在,你甚至可以按照你的想法自如的透视数据。定制透视就可以让你做到这点,无论是文本类型(比如透视字符串的首字母)或者数字类型(比如透视数字的平方根)。当然,你需要对General Refine Expression language(openrefine内建函数语言GREL)有基本的了解,我们将在附件:正则表达式和GREL中介绍。
当然,openrefine也提供一些预定义透视选项,其可以给大多数用户提供有用的透视功能。下面,我们将查看这些透视项,着重对其中重要的东西作下介绍。让我们先看一下Customized facets子菜单的内容,我们可以在列菜单Facets菜单中找到。
Word facet(单词透视)列出了字段中所有不同的单词,一个单词被定义为两个空格之间的字符。这在你想对数据小子集进行分析时十分有用,因为大数据的话统计频数会很快增加到很大,比如对列Description进行单词透视,会显示212,751个不同的单词,这很容易导致软件奔溃。
举个例子,单词透视可以用来对categories进行透视,因为普通的文本透视只会告诉你有多少个体表现为数量极小的长尾,而单词透视则会将内容分成两个单词,这能够让你分析不同的长尾,同时也能够让你将长尾间联系起来考虑(就好像既能够分析整套衣服也能够分析配饰)
Duplicates facet (重复项透视):可以让你检测重复项,我们将在下一点来介绍
Numeric log facet (数字对数透视):对数字的对数值进行透视,这在数字符合幂分布时特别有用。1-bounded numeric log facet(1阶数字对数透视)也一样,只不过其不能应用于小于1的数字。
Text length facet(文本长度透视)针对的是字符串中的字符个数,以Object Title列为例,选择该列菜单Facet| Customized facets|Text length facet,我们可以看到该列中的内容字符个数从0到260,你可以看到有92个标题内容中内容小于10个字符数(无内容的占大多数,这毫无意义),你还可以看到2007个标题内容超过250个字符数(一般情况下一定需要精简了)
对descriptions列进行文本长度透视也十分有趣,但是我们看到这个分布实在太广了点(从0到4100,虽然85%数量的内容小于500个字符数),这导致我们很难了解其规律。这时候我们可以使用文本长度对数透视,如下所示:
Unicode char-code facet(Unicode字符集透视)并不计算字符串的长度,而是列出了所有字符串中使用的字符UNICODE码数。在Object Title列尝试下;大部分英语字符UNICODE码数小于128,一些源于欧洲语言的古文UNICODE码数会达到256,阿拉伯文或中文甚至更大。如果你发觉字符UNICODE码数特别大,可能是OpenRefine没有正确的识别出编码。碰到这种情况,可以新建一个项目然后选择手工指定正确的编码方式。
最后,我们还可以按照错误来透视(如果有的话),或者按照空值来透视。按照空值来透视在了解字段填充分布时十分有用,一般常用来与另一个透视结果作比较。我们看到Marks列开头几行就为空,所以我们通过点击Facet| Customized facets| Facet by blank来了解该列,透视结果提示我们18,986个为FALSE(也就是非空),86,846个位TRUE(也就是空值)。换句话说,只有四分之一的部分有内容。
还要明显的列是Weight(在屏幕右边,使用水平滑动条滑动可见),只有179个有内容,而99.998%的内容为空。对Object titles列进行空值透视发现,有118行是无效行,它们都有一个RECORD ID跟着一个链接和无效的信息,但是其他列却都是空值,所以它们并不代表一个有效记录。
对标星和标旗行进行透视
在1初识OPENREFINE中,我们简要的提到了最左边ALL列中的标星和标旗功能。现在该介绍如何利用这些功能来透视数据了。星星一般用来标识良好的行或者感兴趣的行,我们可以在今后随时找到它们;相反的,旗帜可以用来表示不好的行或者有问题的行,这些行我们应该在后续处理中注意。当然这只是建议,你当然可以赋予星星和旗帜不同的意义。
要标星或者标旗,只需要在对应的符号上点击即可。大都数情况下,你可能想同时标注多行。在标注前,你需要将需要标注的行分离显示出来,一般也是通过一个透视过程实现。比如,你可以通过对Registration Number列执行Facet| ustomized facets| Facet by blank来检测出空值,然后点击true来显示出118行空行。然后点击ALL列菜单中Edit rows | Flag rows。标星功能也同样,并且你也可以在菜单中去掉多行的星星或旗帜。
现在假设你想显示要么diameter字段有内容或者weight字段有内容的行。如果你对这两列都做了空值透视,然后分两次点击结果是false的内容,你将得到29行匹配,但其实这29行指的是diameter字段有内容而且weight字段也有内容,这和我们的目的不符,我了按要求取到数据,解决方法是分两步:先对diameter列进行空值透视,得到2106行为false(也就是diameter内容存在),然后使用All| Edit rows| Star rows标星,清除透视并且对weight列进行空值透视,得到179行(你会注意到只有150行被标星,因为29行已经被标星,其weight和diameter都有内容而已)。再次清除透视,然后选择All| Facet| Facet by star获得数据,当然使用旗帜功能也可以。
喔,我们总算介绍完了本小点,你可能觉得这个小点怎么这么长,但是确实透视是OpenRefine的基础,所以花点时间还是值得的。
点3-重复检测
在本点中,我们将学习什么是重复数据,如何检出,为什么需要处理重复值。
上一小点定制透视中唯一没有介绍的内容就是重复项透视。重复值是数据集中出现两次或更多次的恼人数据。重复数据不仅浪费存储空间,并且会导致干扰。所以我们希望能够删除重复值。重复项透视就是一种能够检测重复的简单办法。但是其也有限制性,比如其只能对字符串进行重复检测,最起码不能直接对非字符串进行操作(如何能够对整数也能作重复检测,请参照附录:正则表达式和GREL)。
因为上面的原因,我们无法对Record ID列进行重复项透视,这里最好的选择就是对registration numbers列(内部标识)进行重复项透视,当然其准确度不如Record ID,因为数据数据收集人员会赋予其额外的意义。不管怎样,让我们试着对Registration Number列进行重复项透视:Registration Number | Facet | Customized facets | Duplicates facet;281行被标注为重复项,点击左侧中的true显示这批数据。
现在鼠标滚动下查看这些重复项。我们发现一个问题:重复项中包含空白行,这些实际上确实完全一样,但是和有效行的重复是完全不同的。为了剔除这118行空白行,我们需要再对Registration Number列作一次空值透视:Registration
Number |Facet |Customized facets |Facet by blank.点击false保留163行真正的重复数据,我们发现结果自动刷新了。
最后,再增加一个透视,这次是一个简单文本透视,列出数据集中有多个相同registration numbers的项,按照计数项排序,我们看到79项中,77项确实是严格的重复项(重复2次),(2008/37/1)出现了3次,(86/1147-3)甚至出现了6次,如下图所示:
现在让我们回到RECORD ID列的讨论来,因为重复项透视不能用于整数,所以我们将采取一个迂回的办法来检测该列。首先,我们对ID列进行排序:Record ID | Sort…,其中参数项选择numbers和smallest first。我们在1初始openrefine中介绍过,排序只是一种视觉的改变,所以为了让数据永久改成排序状态,我们需要选择Sort菜单(就在Show: 5 10 25 50 rows右边),点击Reorder rows permanently.如果你忘记做了这一步,后续的操作其实会忽略排序这个动作,从而导致不可知的结果。
现在我们已经得到了排序后的数据,ID重复项一定是在一起的。所以我们选择进行如下操作:Record ID| Edit cells| Blank down,重复项中的ID会被空白替代(所有重复项中第一个保留,后续的空白填充)。然后进行一次空值透视:Record ID | Facet|Customized facets| Facet by blank,我们将得到86个冗余行(如果你删除过空白行,也可能是84),其中二次重复项会出现1个,三次重复项会出现2个,六次重复项会出现5个。这86个重复项就是保留1项后剩余的需要删除的冗余项。我们将在点6:删除匹配行中介绍如何删除它们
点4-应用一个文本过滤
本点中,我们将学习如何使用文本过滤来寻找符合某个条件的值。
当你想寻找那些匹配某个特定字符串的行时,最简单的方法是使用文本过滤功能。让我们以一个简单的例子开始。假如你想找出Object Title列中所有和美国相关的所有标题。选择Object Title| Text flter,我们将在左侧看到一个对话框,就在上节中透视对话框相同的位置。现在输入USA。OpenRefne 提示匹配到1,866行,勾选case sensitive (区别大小写),那么比如karakusa和Jerusalem之类的就会被排除,这样我们降低到1,737行。
另外,我们并不能确保这些匹配项里面是否都正确,比如大写的字符JERUSALEM,为了解决这个问题,我们可以试着在USA前后加上空格,但是还是有可能丢失类似以[USA] 和 /USA开头或结尾的内容。以“ USA ”(前后有空格)作为过滤项只会返回172个匹配,只占全部能取到量的1/10左右,大部分都没有取到。
另外,这样简单的文本过滤并没有考虑到拼写方式,比如遗漏了U.S.A. (201 个匹配), U S A (29个匹配)或 U.S.A (22个匹配)。很快你就会发现处理这些问题会让人烦不胜烦,而且你还需要每次都标星以最后将它们组合起来。
这时候就需要用到正则表达式了,正则表达式十分强大,但是需要你对这些表达式中的奇怪符号有基本的认识,这样才能发挥其功效。比如,表达式\bU.?S.?A\b(文本过滤时需要勾选regular expression)将匹配上面所有需要包括的内容,并且把干扰项排除,最后将返回1,978项匹配。
本小点不会教你如何使用正则表达式,可以参考附录:正则表达式和GREL
文本过滤的另一个应用是检测分隔符的使用,在Categories列种,管道符”|”被用来分隔目录,让我们对Categories列应用一个文本过滤,过滤符为“|”,OpenRefine显示匹配到了71105行,这说明大部分内容里面含有至少两个目录(因为单个目录不需要管道符分隔)。
现在再增加一个管道符:||,检测到9个问题行,其包含双管道符,而不是一个。在第三章:高级数据操作中,我们将介绍如何使用GREL来改正这个错误。另一个问题是单元格内容以管道符开始或者结尾,解决这个问题也需要借助于正则表达式。所以我们均将在附录:正则表达式和GREL中探讨。
点5-使用简单单元格转换
本点中,我们将学习如何利用OpenRefine内建的转换功能来修改数据子集。
我们已经学习了透视和过滤,已经基本能够做到按照不同要求进行数据的显示,只不过我们并没有对数据进行过改变。现在到了修改它们的时候了,我们将学习强大的Edit cells菜单。在我们检测数字重复值的时候我们已经用到过了Blank down菜单。另外的转换功能比如分割合并单元格、聚类、计算值相对来说较复杂,所以我们将在下一章学习。其他的转换功能比较简单,所以我们将先学习Common transforms子菜单下的功能,如下图所示:
Trimming whitespace(删除首尾空格),对数据进行删除多余首尾空格操作是提升数据质量的很好的开始。这保证了不会因为首尾处的空格使得相同的值为误认为不同。这些空格导致的值不同肉眼是很难发现的,进行这步可以让你的数据更加整洁。当然该操作也可以减少不需要的字符从而压缩数据集大小。虽然单独一个空格影响不大,但是几千个空格就有差别了,并且可能会导致大的错误。还记得上节中因为一个空格就导致空值被识别成了non-numeric非数字类型。
唯一标识符也不应该有空格;让我们对Registration Number列作下检查:Registration Number | Edit cells| Common transforms| Trim leading and trailing whitespace,我们发现有2,349个单元格被处理,这也就意味着这个操作是必要的。但是记住我们不能对Record ID列进行操作,因为删除首尾空格的操作只能针对字符串,而不能对整数操作。如果你去试试,也会发现所有整数会被删除。
Consecutive whitespace(连续的空格)的产生一般是因为输入时太快导致。我们可能会预见到object titles 或者descriptions这类有很多文本内容的列一定会有这个问题。但是奇怪的是,操作后并没有发现。倒是对Production Date列进行Collapse consecutive whitespace(连续空格只保留一个)操作,发现有7671个值被处理,但其实这大部分只不过是将整数转化成了字符串。对其他的列也试试看,这个操作很安全,而且证明总是对数据清洗有益的。
如果你的数据是从互联网应用中获取来的,那么内容中很可能包含HTML代码,在HTML代码中,字符被解析成HTML实体。比如法语字符é会被编码成é;或者é 这取决于使用什么范例表示方法。
因为浏览器在解析的时候经常会碰到编码问题。如果解析不对的话会变得难以辨认(比如é就可能被解析成é)。所以,如果你碰到一些值是以&开始并且以;结束的话,试着使用菜单项功能:Edit cells | Common transforms| Unescape HTML entities,这样内容就能够被正确解析。
下一个转换功能是case transformations(大小写转换),通过这个功能,我们能够将文本字符串转换成全部小写、全部大写或者首字母大写。举个例子,我们发现registration numbers列没有小写,但是对其进行操作:Registration Number|Edit cells |Common transforms |To uppercase.却发现有2,349个单元格值有变化,一般来说,这应该意味着有很多大小写问题,但其实却并没有。这些值的变化主要是因为整数被转换成了字符串(因为数字被认为没有被大写)。你可以试着对registration numbers列先做一次数字透视,然后进行大小写转换来看看这些数字的变化,程序提示你没有数字,也就是说这次大小写转换将数字转成了字符串。
同样的,我们也可以用To lowercase来验证persistent link URL列种没有大写字母,或者用To titlecase 来规范categories列的拼写、统一Didactic Displays 和Didactic displays的书写。To titlecase只会将空格后的字符串首字母大写,所以Spacecraft|Models|Space Technology会变成Spacecraft|models|space Technology,有些时候我们并不想这么做,但是别担心,因为第三章:高级数据操作中我们将介绍一个更好的处理这种情况的方法:clustering聚类。
在点2:数据透视中,我们碰到过一种数据转换方式。事实上,你可能记得,就是将应该是时间类型的数据转换成日期格式(OpenRefine日期格式:yyyy-mm-ddThh:mm:ss),因为进行时间轴透视必须要求是日期格式。还有就是将值转换成文本或者数值。比如我们为了去重可以把record ID列转换成文本,但是在我们对其进行排序或者数字透视时就需要将值转换为数字,不然排序就会出现10排在2前的错误。
预定义转换方式的最后一个Blank out cells就有点简单粗暴了,它将删除该列所有的内容。当然最好只对数据子集使用。一个科学的方法是先将有问题的值标上旗帜标识,然后使用All| Facet| Facet by flag分离出来,最后使用Blank out cells删除。
我们已经介绍完了常用的转换方式,但是请注意这些只是转换功能的冰山一角,转换的方法不可计数,这你会在第三章:高级数据操作和附录:正则表达式和GREL体会到。打开菜单Edit cells | Transform…就会打开Custom text transform 窗口,你可以在这里使用GREL自定义转换,你可能会觉得太难太复杂,但是学好以后你会觉得值得这么去做。
点6-删除匹配行
在本点中,我们将学习如何处理问题行(前面通过透视和过滤发现的)。
检测重复或者将冗余行标上旗帜标识是需要的,但还不够。某些时候,你可能需要从单纯的数据分析转到数据清洗中来。在实际情况中,这意味着那些有问题的行需要从数据集中删除,因为它们的存在是对数据质量的损害。
在删除行前,请确保你已经做过了一个透视或者过滤,不然你可能会误将所有数据删除。让我们从项目数据集的最初状态开始(重新导入或者在Undo / Redo页中选择0. Create project以恢复默认),另外,请确保OpenRefine是以行rows显示而不是以记录records显示。
我们将首先删除RECORD ID中没有内容的行。首先对Record ID列进行操作:Record ID|Facet |Numeric facet ,在左侧弹出面板中去掉Numeric 勾选,这样我们就只剩下Non-numeric数据,这里我们有3条。记住这里如果使用Facet by blank操作并不会起作用,因为这些行其实并不是空白,而是包含了一个空格。现在使用All| Edit rows| Remove all matching rows删除这个行。
很好,这样我们已经将数据集减少了3行,non-numeric类型的RECORD ID数据被删除了(透视图也刷新了),数据质量也提高了一点。现在清除透视后我们发现数据行数量下降到了75,811行。
下一步,我们将处理数据集中registration number列有问题的行。该列没有空格(你可以对Registration Number列应用一个简单的文本过滤,输入一个空格字符,我们发现没有匹配行)。所以我们对该列进行空值透视:Registration Number| Facet| Customized facets| Facet by blank。选择为true的值,得到115条匹配行。这些就是空行,我们可以用Remove all matching rows删除。
就像你看到的那样,删除空值行十分简单;现在我们将处理重复行。重复行就稍显麻烦点,但我们还是需要删除它们的,可能你需要回顾下点3:检测重复项,对Registration Number列执行:Registration Number| Facet| Customized facets| Duplicates facet。选择true得到163行匹配行。问题是,如果你直接删除这些行,那么不光重复项会被删除,那个唯一的值同时也会被删除。换句话说,如果某行出现了两次,那么删除匹配行就会把两条都删除而不是仅仅删除一条。不过即使你误删除了,你也可以通过项目历史恢复。
所以我们需要做到既去除多余重复项,同时还能够保留一项。我们可以这么做:对Registration Number进行排序,选择text和a-z选项(case sensitive不必勾选,因为该列只有大写),然后选择Sort| Reorder rows permanently来固定排序。最后,使用Registration Number | Edit cells| Blank down将多余的重复项使用空白填充。最后有84个单元格被修改。
如果你的重复项透视界面还打开着,那么你会注意到重复项刷新为84行。这是因为去重后的值(163条中的一部分)被摘出了,这时候它们已经不再是重复项了,所以在重复项透视中被识别为false。而真正的重复项则被填充成了空白,它们具有同一个值:空值。这就是出现84项重复的原因。现在你可以将这些项删除,并且能够保留下原值。
正常情况下,你现在将还有75,612行数据。我们还可以进一步处理,但是你可能已经知道如何去做了,这些就留给你们去实验。最后看下Undo / Redo页中项目历史究竟我们做了哪几步。
我们首先删除了3行,然后删除了115行看上去record ID为空的行。为了删除84行重复项,我们对Registration Number列进行了排序,固话排序后我们用空值进行了填充。我们总共删除了202行,我们的数据集更加干净了。你可能注意到了:文本透视和排序操作并没有出现在历史操作中,这是因为这些操作并没有改变数据,而是仅仅是为删除做的一些准备工作。
小结
在本章中,我们学习了如何使用OpenRefine来分析和修复数据的基本操作,这是数据分析和清理的最基本技能。
分析数据包括排序和各类透视功能,还包括文本过滤和检重。
修复数据步骤则包括排序、单元格转换、删除。
下一章中,我们将学习OpenRefine更深层次的内容,我们将学习高级数据操作。
第三章:高级数据操作
上一章中,我们介绍了OpenRefine的一些基本的操作。然而这些仅仅提供了你初级的数据分析处理技能。只有OpenRefine高级特性才能让你领略其真正的强大之处,本章就将介绍这些内容:
• 点1:对多值单元格的处理
• 点2:行模式和记录模式的转换
• 点3:相似单元格聚类
• 点4:单元格值转换
• 点5:增加源列
• 点6:拆分列
• 点7:行列转换
以上要点你可以自由选择学习。在本章学习前,你需要使用已经清理过的数据集,这可以在PACKT网站下载。学习这些要点中的任何部分都可以让你成为OpenRefine高级用户。但是请注意:有些数据操作特别重要。
点1:对多值单元格的处理
在很多表格数据中有一个普遍的问题:如果一个单元格中有多个值怎么办?举个例子,如果有一张包含名字、地址、电话号码的客户信息表格。录入人员正在对这张表格进行信息录入,当其发现有一个名字为Mr.Thompson的人有两个地址信息,并且每个地址信息对应一个电话号码,一般情况下录入人员会选择下面三种可能的操作:
• 只增加一个地址信息:这是最简单的做法,这减少了一般的录入工时。但是,这也意味着丢失了一般的信息,所以表格信息完整性被降低了。
• 增加两行:虽然现在表格信息是完整了,但是数据却出现了冗余。数据冗余也不好,因为这很容易导致错误:这两行可能会被认为是两个不同的都叫Mr.Thompson的人的信息,但如果这是Mr.Thompson不同时间所留下的信息,就容易导致错误。另外,因为这两行没有什么联系,如果其中一行信息被更新了,另一行并不能自动更新。
• 在一行中添加所有信息:这种情况下,两个地址信息和两个电话信息都被添加到对应字段中一个单元格内。但是对于原先字段的定义来说,我们这样操作可以说是信息超载了。当然这样操作对于信息来说是符合完整和非冗余,但是也会有个问题。对于我们人类来说我们可以毫不费力的识别出这些信息含义,但是计算机却做不到。想象下一个写信的人在信封上写了两个不同的地址;或者是一台自动拨号机,其是通过将一个单元格的所有内容作为一个电话号码来进行拨出。上面两种情况都会产生错误。所以字段确实丢失了语义上的精确性。
虽然我们知道我们有很多种技术方法可以解决多值单元格问题,比如表格关联。但是,如果数据模型你不能控制,那么你也就只能选择上面三种中的一种。
幸运的是,OpenRefine可以做到多值单元格的识别。当然因为OpenRefine是一种自动化软件,所以其需要在操作前指定某个字段为multi-valued多值字段。在Powerhouse Museum数据集中,Categories列就包含多值单元格,因为其单元格内容可以属于不同的分类。在我们进行操作前,我们必须告诉OpenRefine这个字段是有点不同的。
假如我们想了解Categories列中究竟有多少不同的分类,并且哪个分类数量最多。那么首先让我们看看,如果我们对Categories进行文本透视会发生什么(Facet| Text Facet),如下图所示。你可能会记得我们在第二章:分析和修改数据中的经历,这样做并不有效,因为会出现太多的分类。对于OpenRefine来说,其会提示“总共有14,805个分类,数量超出了现实范围”。当然你可以通过点击Set choice count limit.来增加最大显示数,但是我们强烈建议你不要这么做。因为首先这可能导致OpenRefine运行变慢。其次,OpenRefine也只会直接列出多值分类内容(比如Hen eggs|Sectional models|Animal Samples and Products)。这无法让我们了解所有单独的分类内容,而我们感兴趣的恰恰在此。
为了解决这个问题,我们先不要关闭左侧透视窗口,选择Categories下拉菜单:Edit Cells | Split multi-valued cells…,如下图所示:
OpenRefine现在提示What separator currently separates the values?(分隔符是什么?)。我们可以从最初几行看出,值是被管道符分隔,也就是我们讲的垂直线。因此,我们在对话框中输入“|”。如果你在键盘中找不到这个符号,那也可以在单元格中复制然后粘贴到对话框中,然后点击OK.
几秒钟后,你可以看到OpenRefine已经分割好了单元格值,并且对Categories的透视界面也刷新了,显示了单独的分类。默认情况下是按照字母顺序显示的,如果我们按照频数显示的话我们能够获得更加有用的信息。我们可以将Sort by 选项从name改为count。这样我们就能够发现出现数最多的分类。
下面还需要做的是那些还没有变为单值的分类,我们需要将分类名称修改下,这样所有的行都会更新。比如,修改分类名Clothing and Dress,在透视界面中移动到该分类名上方,点击edit,如下图所示:
输入一个新的名称比如Clothing,然后点击Apply。OpenRefine 就会把所有Clothing and Dress名称修改为Clothing。并且透视界面也立即刷新了。
一旦你已经将分开的值编辑好了,那么你可以把他们重新组合在一起。点击Categories列的菜单:Edit cells |Join multi-valued cells…,然后输入你想要得分隔符。这次的分隔符并不一定要和原来的相同,有很多字符可以使用。比如,你可以使用逗号后面跟一个空格来做分隔符。
点2:行模式和记录模式的转换
现在让我们看下OpenRefine是如何处理多值单元格的。当我们按照上一点的操作步骤对一个列进行了分割后,我们发现OpenRefine做了两件事情。一方面,多值内容中的第一部分被替换放回原来的位置,另一方面,剩下的值被放到下一空行中对应的位置。举个例子,如下图所示,你可以看到ID7-ID9的记录基本是空行,只有Categories对应的单元格有内容,只有第一行(ID6)中其他单元格内有内容(ID6):
row是指数据集中的一行。
Record包括一个主体中的所有行。第一行所有单元格非空,标识一条记录;后续行中相同内容为空,表示这些行隶属于同一条记录
虽然这种处理方式避免了信息的重复和错误,但是也使得比较难分辨隶属于哪个主体。比如,如果我们对Categories列进行了文本透视(参照前一点),我们可以点击每个类别名称来看究竟有哪些行属于这个分类。但是,如果我们这么做的话,我们会发现许多空行:
产生上图结果的原因是:OpenRefine其实确实显示了所有分类值为Numismatics的行,这些行中包括那些Numismatics不是首个分类名称的行。但是对于某个主体中的其他行却并没有包括。这在我们关注某个主体中的所有行时就会产生问题。比如,我们可能想对所有类别为Numismatics的行进行标星操作,从而想对其进行后续操作时就会产生问题,我们可以试着这么做然后看看发生什么情况。
选中文本透视视图中的Numismatics,点击ALL下拉菜单中Edit rows | Star rows,然后点击文本透视视图中的reset来看看发生什么情况。我们发现只有值为Numismatics的行被标星了,而隶属于主体的其他行却并没有被标星。很显然我们丢失了信息。所以,让我们通过Undo / Redo标签页撤销标星操作。
OpenRefine可以让我们将隶属于同一个主体的所有行集合成一个单独的record(记录)。这样做的话,可以让我们在分割多值单元格的同时确保这些行还能够被认为是一个整体。我们可以在Show as 中将rows 改成records。你立即会发现行中颜色的改变。其会从以每个row进行颜色区隔变为以每个record进行颜色区隔。
如果我们在records模式中,在Categories透视图中选中Numismatics,我们可以发现包含Numismatics的所有主体都被选中了。如果我们通过ALL下的Edit
rows |Star rows进行标星,我们发现所有包含Numismatics的主体都被标星了。
以上说明,在records模式下,操作对整条记录有效,记录起码是一行以上。总结下,我们可以这么说,rows模式只是各个独立的行,而records模式则是一个整体,可以包含数行。
多参数下的记录匹配
如果你想匹配既在目录名称为Numismatics中又在目录名称Medals中的记录该怎么办呢?为了做到这点,首先请确保我们在records模式下,然后我们对Categories进行透视,首先我们选择Numismatics,然后再做一次透视,这次选择Medals,这样我们就获取到了我们想要的记录。
现在如果切换回rows模式会怎么样呢?突然,没有记录获得匹配。你起初可能感到疑惑,但其实很正常:没有一行是同时既等于Numismatics又等于Medals的,每一行最多只有这两项中的一项。因此,多重选择必须在records模式下。
另外请注意,本书其他章节请切换到rows模式,否则可能出错。如果出现不可预料的错误,请先检查下模式是否正确。这能减少很多麻烦。
点3:相似单元格聚类
多亏了OpenRefine,我们并不需要担心数据创建过程中产生的一些问题。如果你在分割多值单元格后对分类进行了分析,你会发现同样的分类并不一定有相同的拼写。比如,Agricultural Equipment 和 Agricultural equipment(大小写不同),Costumes 和 Costume(单复数区别)等等。好消息是这类问题可以借助OpenRefine自动处理。OpenRefine确实让你的工作变得简单。
找到拼写有微小区别的内容的过程叫做clustering(聚类),在你分割好多值单元格后,你可以点击Categories列下拉菜单:Edit cells | Cluster and edit….,OpenRefine会打开一个对话框,这里可以选择不同的聚类方法,不同的方法都提供了很多相似的功能。打开时默认参数为key collision和fingerprint选中。
稍等一会后(如果数据量大可能耗时较多),OpenRefine会完成对Categories列的聚类算法计算,最后其会列出所有的聚类项,每一项都包含拼写有微小差别的行,并且会提供一个整个聚会项的建议值,如下图所示:
请注意OpenRefine并不能完全自动的合并聚类值。事实上,OpenRefine需要你确认是否这些值真的指向同一个内容。这个措施可以名称相似但意义不同的内容被合并。
在我们开始操作前,让我们先学习下界面中的列代表什么。Cluster Size列代表某个名称有多少种不同的拼写方式被找到。Row Count列代表有多少行数据被找到。Values in Cluster列指明不同的拼写方式并且其数量,另外,这些拼写方式可以被点击,所以你可以确定那种是正确的,如果你将鼠标移动到某个拼写上方,会出现Browse this cluster 链接,你可以点击查看所有这类型的数据。Merge?列包含一个勾选框,如果你选中它,那么所有的值将会修改为New Cell Value列中的内容,但你需要点击Merge Selected按钮确认。当然,你也可以手工指定一个值,如果自动出现的值并不符合你的要求。
那么,让我们开始第一次聚类操作吧。我强烈建议你仔细的检查列表,不然会把不同的值聚类到一起。在本例中,聚类算法表现很好:事实上,所有的建议聚类项都是正确的。所以我们可以不必点击每个Merge?勾选框,我们可以直接点击Select All按钮,然后点击Merge Selected & Re-Cluster按钮,这个操作可以让我们将所有聚类项进行聚类操作并且不会关闭界面,这样我们还可以试试其它聚类算法。
OpenRefine立即用相同的算法进行了聚类,结果会显示没有需要聚类项了。让我们尝试下换种聚类算法,点击Keying Function菜单,选择ngram-fingerprint.这里我们需要设置一个新的参数Ngram Size,我们可以尝试改大获改小来获得一个合适的聚类。我们发现OpenRefine又发现了几个新的聚类。你可能急着想点击Select All合并了,但是请记住我们要求仔细检查所有的列表,你能发现错误吗?仔细看看下图:
确实,这种聚类算法将Shirts和T-shirts 认为是相同的,但是这可能并不对,所以,要么手工选择所有正确的建议,要么不要勾选不正确的项。最后点击Merge Selected & Re-Cluster按钮。
除了我们可以尝试不同的算法,我们也可以尝试不同的聚类模式。Method菜单中点击选择nearest neighbor. 我们将看到新的聚类参数 (Radius和Block Chars,我们先使用默认参数). OpenRefine 又发现了新的聚类项,但是这里就有点过头了,事实上有一些建议是错误的,比如Lockets / Pockets / Rockets聚类,另一个聚类是合适的,比如"Photocopiers"和 “Photocopier”,这种情况下,最好的办法是在这许多错误项中手工选择正确项。
假设我们已经找出了所有的需要聚类的项,点击Merge Selected & Close按钮,我们将把所有项进行聚类,并且退回到OpenRefine主界面。如果现在你再观察数据或者对Categories列再进行一次文本透视,你会发现先前出现的那些问题都没有了。
什么是聚类模式?
OpenRefine提供两种不同的聚类模式,key collision和nearest neighbor,这两种模式原理不同。对于key collision,我们使用键函数来影射某个键值。相同的聚类有相同的键值。比如,如果我们有一个移除空格功能的键函数,那么A B C, AB C,和 ABC就会有相同的键值:ABC。事实上,键函数在构建上更加复杂和高效。
而Nearest neighbor使用的是一种技术:值与值之间使用来distance function衡量。比如,如果我们将每一次修改成为一个变化,那么Boot 和 Bots变化数是2:一次增加和一次修改。对于OpenRefine来说,其使用的distance function称为levenshtein
在实际应用中,很难确定究竟哪种模式和方法组合最好。因此,最好的方法是尝试不同的组合,每次都需要小心的确认聚类项是否真的可以合并。OpenRefine能够帮助我们进行有效组合:比如,先尝试key collision ,然后 nearest neighbor。
点4:单元格值转换
在第二章:分析和修改数据中,我们学习到OpenRefine可以自动修改一列的单元格内容,比如去除多余空格。上一点中,我们学习到聚类是另一种修改列单元格内容的方法。然而,以上方法都仅仅是单元格值转换通用方法的一部分。你可以通过不同的稍显复杂的方式修改单元格值。虽然这看起来像是EXCEL公式,但是你会惊讶于其功能的强大。
举个例子,假如你不喜欢使用管道符作为Categories列单元格值得分隔符,你想替换成为逗号后面加个空格作为分隔符。当然你可以先把多值单元格拆分然后再组合实现,但其实我们可以一步完成上述操作,点击Categories列下拉菜单选择Edit cells | Transform…. 会出现如下的转换对话框:
以上界面中最重要的部分是Expression(表达式), 这里可以输入小脚本,用来修改值。Language 项可以让我们选择表达式的语言,现在支持的语言有General Refine Expression Language(GREL), Jython (Java环境的Python语言), 和Clojure(函数型语言,类似Lisp语言),如果你对后两种语言较熟悉,你会发现书写表达式十分简单。但是,GREL是设计特别用来作简单转换的,所以本书我们将使用GREL。
在Preview页,我们能够同时看到初始值和转换后的值,这可以让你实时的调试转换表达式,能够立即看到效果。History页保存了你曾经用过的表达式,这样你后续可以直接重用原来的公式。History页还可以对公式打上星标,这样你还可以在Starred页找到它们。最后Help页对大多数表达式做了简介。
对话框底部,我们可以确定如果表达式在某个特定单元格中运行结果出错时怎么办。你可以选择保持原值、置空、使用错误值。另外,你也可以选择将转换表达式对单元格进行重复应用的次数,这个很有用,可以对处理结果再进行处理。比如,如果你有一个表达式,用来将首字母大写的单词删除,那么就可以利用这个重复功能将单元格中所有大写单词均删除。
回到我们的任务:将管道符修改为逗号后面加个空格。表达式处默认值是value,就像你猜到的那样,这代表原始值。让我们做个小实验看看会发生什么:输入1234作为新单元格值 。预览界面会更新,显示所有单元格值变为1234。这当然没什么意义,但对于你理解功能肯定有用。我们真正要做的是对原值按照我们的意愿进行替换。在Help页,我们找到实现上面意图的GREL函数叫做replace。因为我们想把管道符替换成逗号,所以我们输入value.replace("|", ", ")。这里我们对字符加了双引号,因为它们是字符串而非数字。预览界面会刷新单元格值,我们发现就是我们想要的结果,所以点击OK。只需要很短的时间,OpenRefine就转换好了Categories列的单元格内容,所有的管道符已经被替换。
在修改分隔符时需要特别小心,因为有可能分隔符恰恰是值内容中的一部分。比如:分类Cup, saucer and plate sets中包含逗号,所以如果对这个字段进行替换则很有可能导致错误。但是,我们这里举例的时候还是会用逗号。
为了让我们更加熟练值转换操作,我们再尝试下,这次假设我们想把Provenance列中的分号修改为逗号。点击Provenance(Production)下拉菜单Edit cells, Transform…,然后输入表达式value.replace(";", “,”)。表达式本身并没有错,但是我们在预览窗口中发现有许多错误提示。这刚刚可以让我们试着设置On error参数设定(我也建议你试试看),当然更重要的是我们要知道究竟出了什么问题。错误信息如下:Error: replace expects 3 strings, or 1 string, 1 regex, and 1 string。所以错误的原因是我们传递replace参数时出错了。如果我们检查下出现错误的单元格,我们发现是有些单元格为null所导致。确实,因为null并不是字符串,所以我们并不能对其中的字符进行操作。所以我们需要告诉OpenRefine只转换非空的单元格。点击Cancel,关闭对话框,再点击Provenance(Production)列下拉菜单选择Text filter.虽然我们可以选择Facet by blank功能,但是我们可以通过直接选择包含分号的单元格来节省时间,在文本过滤中输入”;”就能够筛选出我们需要的内容。现在再试着进行单元格转换,我们发现筛选出的单元格内容都进行了替换,并且没有任何出错提示。
最后,为了展示单元格值转换的强大功能。我们将做一些复杂点的操作。虽然管道符已经被替换成了逗号,但是Categories列还有一些其他问题存在。确实,有一些值内容中就包含重复内容,比如第14条记录:Didactic displays, Pearl hells, Buttons,Didactic displays。我们无法采用上面的重复项处理来解决,因为这里的重复是在一个单元格内的。幸运的是,我们可以使用GREL来解决。打开Categories列的值转换窗口,输入如下表达式:value.split(", “).uniques().join(”, ")。这个表达式看起来有点复杂,但是分开解读还是比较容易理解的。首先第一个我们将值按照“,”分割(逗号后面跟一个空格),然后使用uniques函数去重,最后再把内容重新连接到一起。当你点击OK后,OpenRefine会完成操作并且提示你有多少单元格进行了该项操作。
掌握GREL是简单的
本小点介绍了一些例子,如果这里还无法满足你的要求,那么附录:正则表达式和GREL将完整的介绍GREL,学习后你将可以自己书写表达式。
点5:增加源列
有时候你可能希望在单元格值转换的时候保留原单元格值。当然你可以在操作错误的时候通过Undo / Redo页恢复原值。但是如果能够同时显示原值和转换后的值得话一定会更好。因此,OpenRefine提供了增加一列,并且该列是基于其他列创建的功能。
假设我们希望增加一列,这一列是对应分类单元格中分类计数。点击Categories列,选择Edit column-> Add column based on this column…会弹出一个类似单元格转换的对话框。不过,这次其提示需要一个列名。在New column name中输入Category Count。现在我们可以创建分类计数的表达式了。因为分类是被某个字符分隔的(管道符或者逗号,如果你学习过上一点的话),我们可以简单的将它们拆分然后计数。表达式如下:value.split(",").length() ,Preview 面板会显示结果,如果发现没有问题,那么点击OK.确认。
OpenRefine增加了一列新列,这样我们就可以使用Category Count列来分析我们的数据。比如,我们可以对Category Count列进行文本透视:Facet| Text facet. 因为我们只是想对每个独立的计数数量进行分析,而不是分析其值域。所以这里使用文本透视比较简单,虽然这列数据是数字格式。左侧透视界面会显示究竟分类数如何分布,如下图所示:
我们发现有一点比较奇怪:有一栏的值是(blank)。如果我们点击下,我们发现所有的记录Categories字段为空,那么为什么Category Count不显示为0呢?答案是对于空值单元格,这个转换表达式会导致一个错误,因为没有值可以被分割。上一点的学习中,我们可能能够做到在转换前把这些行过滤掉了。不过我们这里尝试修复这些行。在透视界面中点击(blank),点击Category Count 下拉菜单: Edit cells| Transform…. 如果我们在表达式窗口中输入0并且点击OK,那么这些空值单元格就会变成0。那些行会消失,别奇怪,因为我们在透视中还选中着blank,点击过滤项 0(或者其他你像选择的),你就能 得到你想要的数据。
从数据分析角度考虑,我们对于每条记录中分类数计数中那些是最普遍的比较感兴趣。在Category Count透视界面中,选择Sort by:设置成 count.我们发现每条记录中分类数为2的最普遍,不过请注意只有这些值已经聚类和去重后才是比较准确的,就像上一点所介绍的。有一次,我们感受到了GREL的强大。
点6:拆分列
本章开始的时候,我们演示了如何将一个单元格中的多值内容拆分成多行。但是,有时候这并不能解决问题。现有例子中,单元格中的多个分类其实属于同一个属性:分类间比较相似,并且顺序可以互换。但是如果多值单元格中的内容属于不同的类别的话情况就不同了。比如,当一个clients表格包含电话字段但是没有email字段,而某一个客户却同时又上面两种信息。结果这个人的电话信息和email信息可能会被放在一起,用斜杠分隔。
在Powerhouse Museum数据集中,我们也在很多列种发现这种情况。比如,在Provenance字段,我们能够同时发现designers, makers等等信息。如果我们能够把它们拆分成不同的列的话,我们分析就会更加有意义。我们可以点击Provenance (Production)列下拉菜单: Edit column| Split into several columns….,我们能够看到如下的拆分对话框:
我们可以选择按照曾经介绍的by separator(按分隔符)分割, 还可以按照by field lengths.(按长度)分割。按长度分割在数据结构固定的时候特别有用,如1987 en-us,X/Y这样的类型,其没有固定的分隔符(或者根本没有)。当然,本例中我们使用分隔符。一个有趣的选项是设置一个限制,因为可能有分割成很多列,所以设置下限制比如5会比较明智。千万不要忘记设置一个分隔符,比如这里设置成“|”。你可以选择让OpenRefine猜测下分割后的单元格类型(比如分割后可能会出现数字),还可以让OpenRefine删除原来的列。
在你点击OK后,你会发现OpenRefine将原来叫做Provenance (Production) 的列被替换成为了很多叫做 Provenance(Production) 1, Provenance (Production) 2等等的列。这些列可以后续按照实际含义修改名称。并不是所有列都有内容,只有那些至少含有5项的单元格分割后才会所有单元格都有内容。虽然分割后不会超过你设置的最大列数目,但是还是会产生分割前的单元格分项较少,导致无法填满所有的列的情况。
我们再对Object Title列进行分割,我们发现该列中有些单元格是以数字开头的。如果把数字从中剥离出来应该十分有意义。首先,让我们先过滤出这些数字开头的项。点击Object Title 下拉菜单中的Text filter.我们这里写上以数字开头的正则表达式\d.这个表达式告诉过滤器从开头()进行查找并且寻找数字(\d)。别忘了勾选regular expression 。否则 OpenRefine 会把正则表达式当成字符查找。现在我们就得到了那些以数字开头的项。
点击Object Title下拉菜单,然后选择:Edit column |Split into several columns…. 现在我们使用一个空格作为分隔符,设置我们最多要2列然后点击OK. 数字和标题被分割成了两列。
分割列比分割多值单元格功能更加强大,因为其有很多配置选项。你甚至可以使用正则表达式来定义分隔符,这样我们可以做到不同的内容应用不同的分隔符。另外,如果你对本小点中的正则表达式有些疑惑,别忘了参考附录:正则表达式和GREL,那里介绍的非常详细。
点7:行列转换
有时候数据并不是以你料想的方式在行和列中分布。确实,有很多种数据排布方式,这取决于具体的情况。比如在Powerhouse Museum数据集中,有一些很多维度的列:Height, Width, Depth, Diameter和Weight.但是,并不是所有这些列中都有数据,所以如果按照这种方式排布耗时耗力。一个替代方法是将这5列转换成2列:一列包含维度名称(比如Height 或 Weight),另一列包含量度值(比如35mm 或 2kg)
这里我们想做的就是将这些列转换成行。为了做到这点,点击Height 列下拉菜单: Transpose | Transpose cells across columns into rows…,会弹出如下对话框:
左侧From Column栏中选择需要转换的开始列,Height 列已经被选中是因为我们就是点击这一列开始操作的。To Column 栏选择停止转换的列。这两列中间的所有列就是需要转换的列(所以你需要首先将这些列放在一起).这里我们选择Weight,所以这两列及其中间的列将会被转换。
右侧,我们可以选择转换列中的变化内容。Two new columns栏有两项设置, Key column包含的是原来列的名称 (Height, Weight…),Value column包含的是原来的值(35mm, 2kg…). 你可以设置新列的列名,比如Dimension和 Measurement. 另外One column栏可以将名称和值都放到一个单元格中,但是这样做后续分析可能比较麻烦。当所有设置项设置好后,点击Transpose 开始转换。5列数据将转换成2列,如下所示:
请注意,这里OpenRefine需要设置成records模式以保证信息关联。所以,如过某行有不同的量度信息,那么转换后它们会占据多行。可能你希望能够看到所有5个值,即使有些是空值。那么你可以选择在转换对话框中去掉Ignore blank cells勾选。
我们还可以通过执行Transpose |Columnize by key/value columns…来实现反向转换。但是,这个操作对于空单元格十分敏感,所以必须小心。你可能已经能够将Provenance列(名称/值配对出现)转换成全列格式。
小结
本章介绍了一些高级的数据操作。对于多值单元格我们有很多处理方法:当它们的值属于同一类型的话,我们可以将它们分割成多行;当它们意义不同的话,我们可以将它们分割成多列。另外我们也学习了OpenRefine中的一种特殊模式:records模式。在records模式下,属于同一主体的多个行被认为是一个整体,这样就能让我们进行更高效的操作。
我们也介绍了聚类,这在单元格值本身含义一样但是拼写不同时非常有用。你甚至可以定义自己的转换操作,或者基于已存在的列创建新列。最后,我们学习了如何进行合适的行列转换。总的来说,本章介绍了OpenRefine的高级操作,这些操作隐藏在简单的界面下面。到现在为止,你基本可以称得上是OpenRefine高手了。
第四章:数据集关联
数据集之间并不是互相独立的。总在某些时候,可能在你预想不到的地方,数据之间互相关联,比如,如果你的数据集有一列是关于国家的数据,那么这列就和国家地理数据库有关联。一个书籍数据库中关于作者的列就和人物传记数据库有关联。所有的数据集都有这种联系,但是可能你并没有觉察到,有时候计算机也没有。举个例子,书籍数据库中某条关于The Picture of Dorian Gray的记录可能列出作者是Wilde, O,但是人物传记数据库中可能只有一条关于Oscar Wilde的记录。虽然它们都指向同一个人,但是具体表达式是不同的,这也导致很难对它们进行关联。另外,确实很难对所有数据集进行关联,因为实在数据量太大了。
所以,我们的目的是找到单元格值得唯一标识符。这里就是URL(统一资源定位符)。我们这里不再用名称Oscar Wilde来唯一标识,而是使用URL地址 http://en.wikipedia.org/wiki/Oscar_Wilde.来代替 。这样不光 我们 能够使用URL来 唯一标识作家Oscar Wilde(不会与碰巧叫同一个名字的人搞混),而且还可以通过点击链接来访问更多的信息。因此,URL可以使得我们能够把不同的数据集互联起来。在本章中,我们将学习如何把 与URL进行关联,具体的内容有以下几点:
•点1-使用Freebase解析值
•点2-安装扩展包
•点3-增加解析服务
•点4-与关联数据进行解析
•点5-抽取单名称项
和以前一样,你也可以直接阅读你感兴趣的点。但是请确保在学习后三点前学会如何安装OpenRefine扩展包。学习每一点前请使用原始的Powerhouse Museum数据集,其中Categories列已经扩展成了多行。
•点1-使用Freebase解析值
当你想将单元格值从一串简单字符串转换成URL时,你有很多的选择,因为一个确定的内容可以被很多URL所解析,这些不同的URL指向同一个主题。只要每个URL都清晰无误的指向一个单一的内容就没有什么大的问题。但是,我们还是得确定一个我们所要使用的URL。在互联网上,有很多关于内容的数据库,最出名的是Wikipedia。对于人类来说有很多这样的数据库,当然对于电脑来说也有很多。有一个例子是Freebase。这是一个共创知识集,基于对机器可读的特性,基本上覆盖了现有大部分主题。
在openRefine以前叫做Google Refine的时候,其是被Freebase创建者MetaWeb拥有的,并且它的名称叫做Freebase Gridworks。作为一个处理大数据集的工具,其天生就和Freebase结构化数据相契合。
因此,我们将把单元格值解析成Freebase URL。因为Freebase 解析是OpenRefine内置的,所以我们可以直接尝试。记得我们在对Powerhouse数据集进行处理的时候Categories列已经被分割成多行。这很重要,我们必须确保每个单元格包含单个值,这个值将于一个Freebase主体匹配。多内容字段比如Description就不合适用来直接解析。(对于这种情况,可以使用本章最后一点:抽取单名称项来解决)
点击Categories 列下拉菜单:Reconcile|Start reconciling…. 开始对单元格进行解析。OpenRefine 会弹出解析对话框。在对话框左侧你可以看到解析服务项,有两个Freebase解析项是内置的:
• Freebase Query-based Reconciliation: 当列值已经是Freebase IDs (比如 /en/solar_system) 或者 GUIDs(十六进制标识符)时特别有用。
• Freebase Reconciliation Service:此项不要求严格与Freebase标识符对应,用来应对更加一般的情况。
很显然我们需要选择第二项:Freebase Reconciliation Service.进过一会,OpenRefine会在右侧显示服务参数配置界面:
你的OpenRefine打开界面可能和上图略有不同,因为你可以自己安装解析服务,我们将在下一点中介绍
有三个选项可以用来设置。首先,你需要确定什么类型的记录需要解析。这个能够限制只搜索特定的主题,这在你的列只包含城市或者人名时十分高效。这样设置的话解析会很快,并且发生错误解析的可能性较低。在你选择解析服务并开始解析后,OpenRefine会与解析服务器你选择的部分数据进行交互,并且尝试猜测你列的数据类型。这里恰恰不凑巧,这里提供的Categories列的两个选项:人名和地址并不与该列明显相关。当然我们也可以选择Reconcile against type.来自己设定,但是这里我们并不能确定是否数据集中的categories列是否属于某个特定的类型,所以我们只选择Reconcile against no particular type.
第二个可以选择的选项是Auto-match candidates with high confidence。解析服务会返回一个匹配分数,这个分数来指示匹配的程度。这个选项默认是选中的,这表明如果分数足够高,OpenRefine会假设这个选择正确并且申明这个匹配。对于其他单元格(如果你去掉了该选项勾选),那么你就得手工确认匹配项。我们的建议是你还是保留勾选,因为这能够节省大量的时间。
第三个也是最后一个选项能够让我们发送额外列数据到解析服务器。这不同于匹配单列值,这个选项可以让我们考虑多个列内容。你需要指定某个合适的列。对于Powerhouse Museum数据集,并没有这样相关的列存在。但是如果你有一个数据集,包含国家名称和国家码,那么将它们同时发送到解析服务会比较好。
选中Reconcile against no particular type ,点击Start Reconciling.解析进程需要一段时间完成,因为OpenRefine需要对每一个单元格值进行解析以找到一个URL。顶部黄色的提示条会告诉你进度。
解析过程需要时间,你可以休息一下或者干其他工作,而让解析过程在后台运行。解析结束后,你会发现OpenRefine自动创建了一列:judgement并且显示了best candidate’s score透视图。
judgement 透视图将数据集中的行分成“已解析到”和“未解析到”,另外还有Categories列中的空值单元格(这些本来就无法解析)。你可能会感到奇怪,这里只有 (blank)和none ,那已解析到的行呢?
很不幸运,这表明,用Freebase解析的结果是没有找到匹配项。是不是意味着我们做错了呢?不是,这只是表面我们的数据Freebase并没有涉及到。那是不是以为这Freebase不是一个好的解析方式呢?当然不是,这只不过碰巧不适合我们的数据。你可能在其他数据集中得到结果,所以值得一试。
让我们撤销透视,点击RemoveAll 按钮,或者通过Undo / Redo菜单撤销(你可以通过Categories下拉菜单| Reconcile |Facets.重新获得透视图)。下一点我们将介绍如何使用其他的解析服务。
某些时候,你可能仅仅想看下解析服务如何运作。那么是不是意味着每次都需要对全部数据进行解析呢?如果你使用透视功能就不需要!我们可以尝试对一小部分数据进行解析来了解是否需要对所有数据也进行解析。我们可以作下随机选取,比如,我们可以对Record ID列运行文本透视,输入比如4.因为所有ID是按自然数顺序增加的,所以我们大概可以选出10%左右的数据。如果这些数据还是过大,那你可以增加数字位数知道数据量减少到几百左右,比如,413就比较合适。
•点2-安装扩展包
虽然OpenRefine能够让你简单的开始解析服务,但是这些服务必须以其规定的方式运行。其实,还有很多不同的解析服务,如果你想使用它们,你就需要以扩展包的方式添加到OpenRefine中。所以在我们介绍如何使用这些解析服务前,我们首先需要学习如何安装这些扩展包。当然并不是所有的扩展包都是用来提供解析服务的,所以这里只介绍一般的安装过程。在写本文时,有许多OpenRefine扩展包可用,比如下面:
• RDF 扩展包( Digital Enterprise Research Institute(DERI)),这个包提供了对RDF导出格式的支持,对SPARQL 终端查询功能的支持,我们将在下一点中介绍。
• Named-Entity Recognition (NER) 扩展包,此包是本书作者之一所写,可以让你从多内容单元格中抽取URL。本章最后一点将会介绍。
和OpenRefine一样,扩展包也是免费的。最新可用扩展包清单可以在https://github.com/OpenRefine/OpenRefine/wiki/Extensions查到,也可以通过此页面的链接下载。因为扩展包多种多样,所以你可能会疑惑如何安装。本点将介绍如何安装它们。
首先,你需要找到扩展包安装的路径。这个取决于你的操作系统,当然OpenRefine能够帮助你找到。在开始界面的底部 ,有一个链接叫做Browse workspace directory
如果你点击这个链接,你会打开OpenRefine的软件安装目录(起码win和mac系统如此,linux的话请看后面)。在这个目录中,如果没有一个文件夹叫做extensions,那么就创建下,这就是你需要安装扩展包的目录。不同的操作系统,可能是下面的不同显示格式:
• Windows:
C:\DocumentsandSettings(yourusername)\ApplicationData\OpenRefine\extensions 或者可能在 Local Settings 文件夹,那么显示可能是 C:\Documents and Settings(your username)\LocalSettings\ApplicationData\OpenRefine\extensions
• Mac OS X: /Users/(your username)/Library/Application Support/OpenRefine/extensions 或者根目录下/Users/(your username)/Library/Application Support/OpenRefine/extensions
• Linux: /home/refine/webapp/extensions
下一步是下载一个扩展包并且放到此文件夹中。这里让我们安装RDF扩展包。我们可以到http://refine.deri.ie/下载。下载下来的是ZIP文件。使用你的解压文件解压,会得到一系列的文件夹,我们需要的是rdf-extension。
将这个文件夹我们创建的OpenRefine的 extensions文件夹中,这样在extensions文件夹中我们就会有一个rdf-extension文件夹,里面包含一些其他的文件夹,如images, MOD-INF, scripts和 styles。
现在重启OpenRefine以使扩展包生效。只关闭浏览器是不够的。你必须在屏幕底部图标上点击选择close才行。然后再次打开OpenRefine并且创建一个项目。当项目创建后,右侧顶部会显示RDF按钮 ,这表明 安装 已经成功。
如果你没有看到这个按钮,请检查下,是否扩展包文件夹位置对不对,还有OpenRefine是不是重新启动了。
你可以尝试对其他扩展包进行上述安装步骤。下一点中我们将用到RDF扩展包,所以请先安装。最后一点中,我们还将用到NER扩展包,所以现在也安装好吧。
•点3-增加解析服务
本小点中,你应该已经安装好了RDF扩展包。如果没有请参考上一点。如果已经装好了,那么你可能会对RDF 和SPARQL代表什么意思感到疑惑,因为这两个词汇一只出现,现在让我们解释一下:
Resource Description Framework (RDF) 是一种可以被机器读取的数据模型。因为人类能读懂互联网上的HTML格式,而机器却不能,所以需要为机器准备其能够读懂的格式。不会引起歧义是很重要的一方面;比如Washington是个城市还是人名,或者究竟是哪个人?为了解决这个问题,RDF使用URL或者URI来唯一确定。就如我们在OpenRefine进行解析一样。这就是为什么用RDF进行解析比较有用的原因。
SPARQL Protocol and RDF Query Language (简称SPARQL),是一种查询RDF数据源的语言。传统的关系型数据库试用SQL为查询语言;RDF数据库解析通讯就使用SPARQL语言。
如果你想将你的数据与一个RDF数据源进行解析,那么你就必须告诉OpenRefine与这个数据源的通讯方式。当你安装好RDF扩展包后,你就已经给OpenRefine添加了SPARQL语言支持。但是,在我们可以将单元格值解析成URL前,我们必须配置好数据源。单击右侧顶部的RDF按钮,选择Add reconciliation service| Based on SPARQL endpoint…. ,你也可以使用本地RDF文件进行解析,这样当然更加便捷。OpenRefine 会显示Add SPARQL-based reconciliation service对话框:
这个对话框首先让你选择SPARQL服务端点的名称,服务端点的细节(位置及工作模式),以及什么样的信息用来匹配单元格值与URL。你可以使用自己的SPARQL服务端点或者http://www.w3.org/wiki/SparqlEndpoints.中列出的公开服务端点。
在本例中,我们将使用我们已经建立的服务端点。这包含了Library of Congress SubjectHeadings(LCSH) 数据集的最新公开版本。为了使用这个服务端点,我们按如下参数设置:
• Name: LCSH
• Endpoint URL: http://sparql.freeyourmetadata.org/
• Graph URI: http://sparql.freeyourmetadata.org/authoritiesprocessed/
• Type: Virtuoso
• Label properties:只勾选 skos:prefLabel
Endpoint URL 是服务端点具体的位置, Graph URI指明了究竟是用该服务端点中哪个数据集。Type 指明服务端点所使用的软件。这并不需要一定指明,但是知道这些细节能够极大提升底层解析速度。最后, Label properties指明了用那些字段来解析单元格值。在RDF中,这些属性一般有一个通用的名称(事实上一般就是URL地址),一旦设置完毕,点击OK确定。
现在并没有发生什么变化,你可能会疑惑我们该如何知道这个新的解析是否正确添加好了。你可以通过在Categories 列下拉菜单中选择Reconcile | Start reconciling…. 来验证。在弹出对话框左侧应该将看到新的服务名称。现在让我们进入下一点学习,你一定迫不及待了。
•点4-与关联数据进行解析
在上一小点 中 ,我们简单介绍了RDF 和 SPARQL,但是并没有深入。所以本小点我们将深入介绍。大概2000年左右,互联网研究者和工程师发现人类并不是互联网唯一的使用者;越来越多的机器客户端以及软件基于不同目的开始使用互联网。但是,每个软件必须为了某个特定的任务进行编码,软件也无法理解互联网中用自然语言写成的文档。因此,一种Semantic Web(语义网)的概念形成了,这是一种可以被机器解析的网络。这就是RDF 和 SPARQL的开端。
但是,这个概念实在对于大多数人太过抽象。很多概念是基于本体论和推理学的。互联网发明者以及Semantic Web概念提出者之一的Tim Berners-Lee发现了这个问题,所以发起了数据链接准则(http://www.w3.org/DesignIssues/LinkedData.html),这些准则关注于基于语义网络的数据集互联。其主要的准则如下:
1、 使用URI作为名称
2、 使用HTTP URI,使得用户能够查询这些名称
3、 当某人查询一个URI时,使用标准化的方式(RDF, SPARQL)提供有用信息。
4、 包含链接到其他URI,这样我们可以发现更多的东西。
第一条准则要求使用无歧义的标识符来表示内容,第二条准则明确了URL来对应HTTP URI。我们对数据集进行解析都将用到这些准则。第三条准则明确了数据集发布的准则。事实上,RDF扩展包能够让我们导出数据集为RDF格式。第四条准则是关于数据集互联的,这也是数据解析所要做到的东西。
闲话少说,让我们开始解析。就像点1-使用FREEBASE解析值一样,选择Categories列下拉菜单:Reconcile | Start reconciling…, 这将打开解析对话框,这次我们选择左侧LCSH reconciliation service,上一小点中我们已经安装完毕了。OpenRefine 会猜测单元格值类型。几秒以后,其会提示建议值为skos:Concept.这是正确的,因为Category列确实是一些事实内容。你可以让其他的设置保持默认然后点击Start Reconciling.
就像前面所介绍的,你可以使用数据子集才尝试上述步骤以节省时间。或者,你可以在其处理时休息一下。
当解析结束后,你会发现三处情况。首先,OpenRefine创建了透视图包含两项透视项,一项是匹配到的行,另一项是未匹配到的行。第二,你可以在Category列顶部看到一个绿色指示条,这指示了有多少数据被成功解析。第三,单元格值内容会显示不同;某些是蓝色,另一些有新的选项。
让我们首先关注显示为蓝色的已解析项。这些项越多表示解析的越成功(顶部绿色条越长)。显示为蓝色是因为它们是链接项;如果你点击这些链接,你会打开该URL对应的页面。比如,你点击链接Specimens,我们就会打开http://id.loc.gov/authorities/subjects/sh87006764.html此链接,所以这就是我们创建的链接数据。对于电脑来说,现在不再是面对一个单独的字符串Specimens,而是被OpenRefine解析好的一个URL地址。这个地址能够被机器所解析,因为这个URL地址链接到了其他地址,所以机器能够很好的理解其意义。
你看见的黑色的值表示未被解析项,表示这些项目未被找到。这些值不是链接,所以OpenRefine并未自动找到一个URL匹配项。未解析有两个方面问题;首先,找到了多个建议项,但是OpenRefine无法确定究竟是哪个,这时其会列出一些可选项给你,如果某一项是正确的,那么你就可以单击该项,这样该项内容就会替换当前值,也可以双击该项,那么所有具有相同内容的项都会被替换成该项内容。这需要很仔细,因为很有可能某些项其实是指向其他链接条目的。记得可以点击这个建议项的链接,这样会打开相应页面以方便确认信息。
未解析项的产生还有一个原因,那就是OpenRefine没有找到匹配项。这种情况,我们只能说是运气不好。可能是你的数据中的条目并没有在解析数据库中,或者是名字上有区别导致匹配不到。这种情况下,你只能手工给其指定一个URL。可以点击search for match链接,打开的对话框可以帮助你找到正确的匹配。
最后一个可选动作是点击Create new topic 链接(或者在Search for Match对话框中选择New Topic)为单元格值创建一个新的主题,这并不是在LCSH 数据库中创建一个新的URL(本身你也没有权限这么做),其只不过将这些单元格值标成new.这样你就可以在judgement透视界面进行其他操作,比如,你可以使用其他的数据集对这些值重新解析,以看看是否能够找打匹配。
我们如何才能获取解析结果中的URL地址?同时,如何保留原始category列内容。正确的做法是基于Categories列创建一个新列,就像我们以前曾经做过的一样,点击Categories列下拉菜单: Edit Column | Add column based on this column…. 我们将这一列命名为Category URLs. 输入URL转换表达式cell.recon.match.id.这段GREL代码将单元格解析后的信息中的ID(这里就是URL)抽取出来。那些没有匹配到的项会出现错误提示,所以请确保勾选set to blank(对于错误项),点击OK后,你将看到包含对应URL地址的新列。
当你做完解析过程及抽取到需要的URL后,你可能想将Categories列恢复原貌。毕竟,解析数据还在那里,可能对我们产生干扰。为了清除它们,再次点击Categories 列下拉菜单: Reconcile| Actions| Clear reconciliation data. 这样categories 列就会恢复原貌。当然,你还可以通过点击左侧透视窗口顶部的Remove All按钮恢复原貌。
•点5-抽取单名称项
解析服务在你的数据集中只包含单个条目时工作良好,比如人名、国家或者工种。但是,如果你的列内容包含的是一小段文字时解析往往不奏效,因为其只能在数据库中搜索单个条目。幸运的是,另一种技术named-entity extraction(抽取单名称项)可以用的上。抽取算法会对包含多个单元素(比如人名,地址,值,组织或其他一般的东西)的文本进行搜索,其不光能够抽取单项,很多算法还能够进行歧义甄别。举个例子,如果算法在文本中发现了Washington,其会尝试识别这个究竟是城市还是人名,这样就避免了必须对每个单独抽出项才能进行解析的情况发生。
OpenRefine本身并不支持抽取单名称项,但是我们可以增加抽取单名称项扩展包。在继续学习前,请先到 http://software.freeyourmetadata.org/ner-extension/下载安装,如果安装成功,那么我们将在屏幕右侧顶部看到Named-entity recognition按钮。
本小点学习中,你需要保证数据集中categories列未被分割,因为抽取单名称项会在发现记录为多内容时创建多行。如果你已经分割成多行的话会导致混乱。
查看Powerhouse Museum数据集,我们发现Descriptions列是进行抽取单名称项尝试的很好的样本,因为其包含多内容文本。如果我们想把这些内容与数据库互联,那么我们首先需要进行抽取工作。点击Descriptions列下拉菜单选择Extract named entities…对话框如下:
扩展包并不包含抽取单名称项算法,而是使用在线服务代替,就好像解析功能一样。你可以选择喜欢的解析服务。但是和解析服务不同的是,解析服务都是开放的,但是某些抽取单名称项服务却需要注册,但还是免费的,某些服务还提供中级账号,这样能够提供更多的好处,比如更快的抽取或者不限抽取数量。
DBpedia Spotlight服务不需要注册,所以能够直接使用,勾选此选项然后点击Start extraction。OpenRefine就会开始抽取进程,这需要一些时间。因此,就像我们以前介绍的一样,先对一个子集进行抽取实验会比较明智。如果你同时勾选了多个抽取服务,那么抽取速度也就和其中最慢的服务速度一样。
当抽取单名称项进程结束后,你可以看到OpenRefine 在Description列旁边创建了一个新列:DBpedia Spotlight.
在新列中,我们看到了已抽取出的项,如果是多内容单元格,则会分割成多行,你可以在行模式和记录模型之间切换。上图显示DBpedia Spotlight列中,记录162中发现了2条,记录173没有项被发现,记录184发现1项.你可以看到这些项显示为蓝色,这表明这些是链接。举个例子,如果你点击Leeds Town Hall,你就会打开相关资源的链接,这就是数据相互链接起来了,原来人类才能理解的内容现在可以被机器所理解了。
但是,你会发现有些单元格没有相关链接内容。让我们看看其他抽取服务是不是有效。这里,我们需要为这个服务添加账号。点击屏幕顶部右侧按钮Named-entityrecognition ,选择Configure API keys…. 会打开如下服务配置对话框:
举个例子,如果你想使用Zemanta来进行抽取单名称项,在对应字段中增加Application programming interface (API) ,如果你没有API,则点击configuration instructions,这会打开Zemanta的API注册页面。所有的服务都有一个免费选项,所以你可以注册然后对数据进行尝试,而不需要付费。某些服务还有额外的配置选项,可以按照配置指导进行配置。
当你完成配置,对Description列再次尝试抽取单名称项后,你可以同时选择多个服务项了。每个服务会创建一个独立的列,所以你会得到两列:Zemanta 和AlchemyAPI,每一列都会有抽取项。所以多尝试下吧。
小结
本章中,我们学习了如何使互相孤立的数据集建立联系。一方面,你可以对单内容字段进行解析,这样可以使得这些单元格与URL对应,并且能够在线查询详细信息。你也可以使用内置的Freebase解析或者安装RDF扩展包 来实现对链接数据的解析。另一方面,你也可以使用扩展包进行抽取单名称项,这可以使OpenRefine对单元格内的内容进行查询,并且找到每个内容小项的URL。最后,你的数据集会与其他数据集建立丰富的联系,使之在发布时变得很有价值。
第五章:正则表达式和GREL
OpenRefine中有两个很强大的工具: regular expressions(正则表达式) 和 GREL. Regular expressions 是我们在处理大量数据时用来匹配和替换文本的有效工具。General Refine Expression Language, GREL, 是当需要进行数据特别处理时预定于函数。这一章我们将介绍这两个工具。
对文本应用正则表达式
OpenRefne 提供了很多查找所需数据的方法。但是如果你并不知道确切的文本,或者是大数据集中模糊的要求,又或者是单元格间有微小的差别该怎么办呢?因为单是查找一个字母a是比较简单,但是查找那些包含一个数字(更差的情况是,一个字母后面跟一个数字)的值就困难的多了。这时候正则表达式就该登场了。
正则表达式能够定义一个文本样式,而不需要指定一系列精确的文本集。这可以让你做到指定比如“一个字母后面跟一个数字”及更复杂的东西。正则表达式通过建立一些字符集,这些字符集可以代表你需要查找的内容,与数量符,锚符,可选符和组符配合使用就可以满足你的查找需求。
在OpenRefne中使用正则表达式十分简单。对任何列进行一次文本过滤(Powerhouse Museum数据集中的Object Title 列就特别有趣),通过点击Object Title 列下拉菜单中的Text filter执行.在新创建的过滤窗口中勾选regular expression (正则表达式)选项。现在数据就可以按照你书写的表达式进行过滤:
字符集
正则表达式使用字符集(字母,数字,空格等)来查找字符。比如,如果你要查找字母或者数字,你可以直接输入:
• 使用Aar来查找,那么就会查找所有文本,其中文本中包含一个大写A后面跟小写的a和r。如果区别大小写选项case sensitive未被勾选,那么查找就不会区别大小写。
• 使用123来查找,那么将查找所有文本,其中包含这些数字。记得41235同样也会被查找到,因为123同样是其的一部分。
• 上面的内容,我们发现就是一般的文本匹配。但是如果使用正则表达式,那么我们就可以指定那个任何的字母或数字。我们可以使用方括号[ ]来指定一系列的待选字符集。我们还可以在方括号内使用 - 来指定字符域范围
• [0123456789]匹配其中任何一个数字。
• [0-9]和上面是一个意思,只不过这个更加紧凑。意思是0-9之间的数字都可以。
• 同样的,[a-z]匹配了所有小写字母(如果区别大小写选项未勾选,则大写字母也会被匹配)。[A-Z]匹配了所有大写字母。[a-zA-Z]匹配了所有字母,无论大小写。
• 如果你想匹配字母和数字,可以使用[0-9a-zA-Z]。代表某个字符,可以是0-9之间的任何数字,可以是a-z之间的任何字母,也可以是A-Z之间的任何字母。
• 早些介绍的例子中,我们可以把所有的可能匹配项放在一起,如analy[sz]e将匹配美式拼写(analyze)和英式拼写(analyse)。
• 同理,[0-9][a-z]代表一个数字后面跟至少一个小写字母。[a-z][0-9][0-9][0-9]代表一个字母后面跟至少三个数字。
• 如果你想匹配到如1 cm 或25 in,那么使用上面的办法将无法匹配到,因为中间有个空格。幸运的是,空格也是一个字符,所以可以使用[0-9] [a-z] 。记得两个方括号之间有一个空格,并且这个匹配也能匹配到如12345 meters之类的长字符。事实上,其匹配了所有一个数字后面跟一个空格,然后再跟一个字母的样式。12345 meters其实匹配到了5 m。其余数字或者字母其实并没有多大关系。
• 如果你想查找所有以inches为单位的内容,那么可以使用[0-9] in。
• 每次都写[0-9]可能比较麻烦。所以我们可以用到简化字符集。它们是一些代替字符集的符号。比如,\d代表任何数字,其实就是等同于[0-9],书写更加简便。\D代表非数字,可以是字母或者其他字符。不幸的是,没有代表任何字母的简化字符集,但是有一个代表任何字母、数字或下划线的字符集:\w,其代表一个任何字符。相反的是,\W代表一个字符,其不是字母、数字或下划线。
• \d[a-z]代表任何一个数字后面跟一个小写字母。
• \d\d\d代表至少有3个连续数字
• \D\D代表至少有2个连续非数字。如果你看到匹配项中也有数字可能会感到奇怪,其实原因是:其只保证匹配到的项中至少有2个连续非数字,但是并不表示一定不包括数字。当然,如果文本内容中只有数字,那么就不会被匹配到。其实这个表达式代表的意思是:“我在查找至少有2个连续非数字的内容,有吗?”
• 你可能想知道\D如何工作的。是不是其需要查找所有不包含数字的字符。其实答案很简单,其在括号中第一个字符前使用,代表括号中的字符不得出现,所以\D其实就是[0-9]。
• [^a-zA-Z0-9] 代表不是字母且不是数字。很多字符会被匹配到,比如连续的空格和标点符号。但是,空值是不会被匹配的,因为这里至少需要一个字符,且这个字符不是字母和数字。
• [a-zA-Z0-9]\d[a-zA-Z0-9]代表任何一个数字,且其前后都有一个字符,这个字符不是字母及数字。举个例子,圆括号中单个数字(3)会被匹配到,而如(123)不会。因为这个表达式表示的就是需要单个数字。
如果你确实想匹配任意一个字符,那么可以使用点“.”,这个字符匹配任何字符(除了换行符\n)。当然单个使用并没有多大用处,但是和其他字符集配合使用的话就十分有用了。
• a.a.a将匹配到至少连续出现三次字母a,并且两个a之间有一个任意字符,比如,dulcamara, alabaster, salamander都会被匹配到。
• 19… (其前后各有一个空格)将匹配到所有20世纪的年份。
• 但是,使用点还是需要慎重:19… 同样也会匹配19th和19M$。因为点代表任何字符,所以如果你想代表年份的话,19\d\d会更加精确。
现在,你可能想知道如何匹配到一个真实的点、方括号或者真实的反斜杠加字母d。办法是告诉正则表达式你不想使这些字符代表特殊意义。对于字母、数字、空格及一些其他字符,一般不会产生歧义,但是对于有特殊含义的字符,可以在前面再加上反斜杠,点可以表示为.。反斜杠可以表示为\。
• 可以使用...表示三个连续的点(当然还有更高效的办法,我们将在下节介绍)
• 可以使用\来匹配反斜杠\。(本数据集中没有这种情况)
• 可以使用[
]来匹配文本包含左方括号[或者右方括号]。这看起来比较复杂,但其实还是很容易理解的:最先的左方括号和最后的右方括号代表“任意此放括号中内容将匹配”。但是此方括号内的内容为真实的左右方括号,所以需要特别指定,使用
和
。
• [2]代表匹配数字2(方括号内的任意内容被匹配,这里只有2)。使用
2
将匹配真实的2,且前后分别有一个左方括号和右方括号(“[2]”)。因为这次被特别解释了,所以方括号也就失去了其特殊的意义。
数量符
到现在为止,我们介绍了正则表达式中单个字符的表示。但是,我们可能会遇到需要匹配一个未知字符多次的情况。比如,我们如何表示“单引号里面一个数字”,我们可能会使用’\d’,但是这只会包括类似于0,1,5之类的单位数数字,多位数数字如23和478将不会被匹配。因为,计算机解释’\d’就是:一个单引号,一个数字,再一个单引号。
数量符能够用来表示重复。有三种简单的数量符:加号+,代表重复1次及以上;星号*,代表重复0次及以上;问号?,代表重复0次或1次;它们只是针对直接的左侧字符起作用。
• bre+d匹配了bred, breed, 或 breeed等任何数量的e,只要e起码出现1次。
• bre*d匹配了brd,bred, breed, 或 breeed等任何数量的e,可以看到没有e也会被匹配,记住brd会被星号匹配,但是加号则不会被匹配。
• 我们可以组合使用,br?e+d匹配了bed, bred, beed, breed,beeed, breeed等等。
• 另外,你可以使用花括号{最小值,最大值}来表示字符的重复区间。你可以确定重复的最大值和最小值。其中任何一个可以为空,如果没有最小值或者最大值。但是你必须将逗号保留,以保证OpenRefine能知道是最小值还是最大值。如果你仅仅输入一个数字但是没有逗号,那么将仅仅匹配这个数字的重复次数。
• N\d{5,8},将匹配字母N开头,后面跟5位或6位或7位或8位数字,然后是一个逗号。
• N\d{5,},将匹配字母N开头,后面跟5位或5位以上数字,然后是一个逗号。
• N\d{,8},将匹配字母N开头,后面跟最多8位数字,然后是一个逗号。
• N\d{5},将匹配字母N开头,后面跟5位数字,然后是一个逗号。这等同于N\d\d\d\d\d,但是书写更加简洁(特别是数字位数多的情况)。
• 还有一点需要明确,数量符和括号是特殊字符,所以如果你只是想匹配这些字符,那么你就需要在其前面加上反斜杠。比如,将问好?作为字符的话可以输入?
锚符
有时候,你不是要表达有多少字符被匹配,而是想确定字符串哪个位置被匹配。这时候就可以使用锚符anchors。补字号表示必须在开始匹配,美元符号$表示必须在最后匹配。(不要与方括号[]内的补字符搞混,这个表示的是否定意义,这和括号外的^意义不一样)。另外,\b可以指定匹配的区间的开始和结束。
• ^\d匹配开始为一个数字。
• ^\d$匹配结束为一个数字。
• ^\d.*\dKaTeX parse error: Expected group after '^' at position 66: …,结尾为一个数字。如果我们使用^̲\d+,则表示这是一个数字(任意长度)。
• \b\d{3}\b匹配至少含有三位的数字,因为\b设定了区间。如果某个内容包含四位数字但是没有三位数字,那么将不匹配(如果移除\b,则会匹配)。
• ^\d{3}\b匹配开始为三位数字,第四位为非数字。
可选符
我们已经学会了如何指定可选内容。方括号可以让我们选择其中字符中的任意一个:[a-z123]匹配任意一个小写字母或数字1或2或3。大多数情况,待选的内容可能不止一个字符,有可能为多个字符。这种情况下,管道符”|”就派上用场了,其起的就是或操作的作用:
• glass|wood|steel 将匹配glass或者wood或者steel
• \d+|many|few 匹配任意数字或者many或者few
• N\d{5},|N\d{8}, 匹配以N开头以“,”结尾,中间要么是五位数要么是八位数,其他不匹配(如中间是六位数就不匹配)
组符
最后需要介绍的就是组符groups,如果对一组字符应用数量符,就需要把他们用圆括号“( )”括起来:
• la+匹配了la,laa,laaa等等。而(la)+匹配了la,lala,lalala等等。
• analyz|se会匹配任意包含analyz或者se的文本。这可能并不是特别有用。而analy(z|s)e 会匹配包含analyze 或者 analyse。这里其实等同于analy[zs]e,我们只需要对z和s二选一。而analyz(e|ing)将匹配包含analyze 或 analyzing.
• 因为原括号有特殊意义,所以如果括号仅仅是普通字符,那么我们就需要使用反斜杠指出。
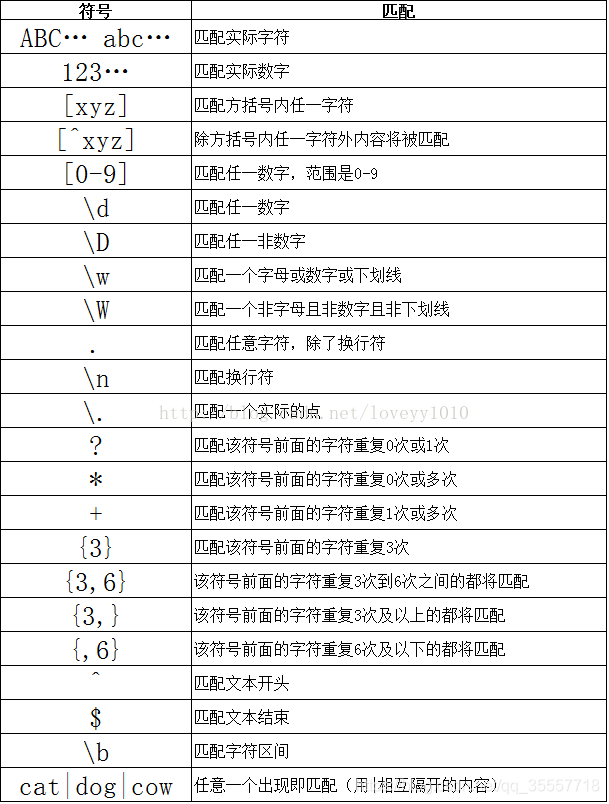
下表列出了正则表达式中的一些特殊符号应用:
GREL
正则表达式的强大功能并不限于数据查找,还可以用作数据管理。GREL提供了利用正则表达式完成函数操作的可能。GREL是用来操作数据的简单函数语言。其是OpenRefne内置的,并且包含函数参数设置。前几章我们已经简要的接触过了,这里我们将教你如何构建你自己的GREL表达式。
数据转换
在你需要对数据进行转换的时候就需要用到GREL。你可以直接对数据进行修改(通过点击相应列菜单:Edit cells | Transform… )或者创建基于某列的新列数据(通过点击相应列菜单:Edit column | Add column based on this column… )。我们将对Object Title 列进行操作演示。
当你打开转换对话框后,你会发现默认有一个GREL表达式叫做value,其作用就是返回源值。这当然并没有多大用处,但是我们可以以此为基础进行扩展。举个例子,GREL表达式"TITLE: " + value + “.” 在源值的前面增加了文本TITLE:,在最后增加了一个点。但是注意这里的文本必须括在双引号或者单引号内,不然的话OpenRefne会理解错误。在你输入完成后你就会发现预览窗口显示了数据更新。
更有用的功能是改变文本。举个例子,我们可以用value.replace(“stone”, “stones”) 将字符串stone替换为 stones。这里我们通过在value后加小点来调用replace函数。我们这样就是告诉了OpenRefne将所有值的stone的替换为stones。
对于上面,如果我们组合上正则表达式,那么将更加强大。你可以看到,有一些单元格值是以数字开头的。我们可以用value.replace(/^\d+ /, “”)将这些数字删除。这里正则表达式被正斜杠“/”包含,要替换成的值用双引号包含。
我们还可以使用组符来增强功能。其不光可以将多个字符标识为一个单元,还可以后续使用这个单元以做更多用处。这样的话,我们就可以将开头的数字替换成更加容易理解的内容。举个例子:我们需要将234 替换成 Object 234: ,我们就可以使用如下表达式:value.replace(/^(\d+) /, "Object $1: ") 。你是用美元符号跟一个数字来定义组,第一组叫做$1,另外$0代表整个表达式的结果。
表达式可以完成任意功能,只不过取决于表达式的复杂程度。比较难的例子是我们曾经对Categories 列中的多值内容分析时,有些包含空值。举个例子,"|Stones||Bones|||Buildings" 实际上只包含三个值,但是如果你针对管道符进行拆分时,你会得到七个值(包括四个空值),这是因为这里有六个管道符。我们可以剔除这些多余管道符。值开始的管道符必须删除,所以我们可以先用value.replace(/^|/, “”)。这看上去有些复杂,因为这里的管道符必须使用反斜杠,以防止被认为是正则表达式中的特殊字符。将连续出现的多个管道符改为一个,我们可以使用value.replace(/|+/, “|”) 。记得在正则表达式中管道符需要使用反斜杠,而替换字符串位置不需要,因为替换字符串位置不可能存在特殊的意义。
OpenRefne除了replace函数外还有大量其他函数,你可以在表达式编辑窗口中点击Help 页查看,或者也可以访问https://github.com/OpenRefine/
OpenRefine/wiki/GREL-Functions。比如split函数,我们对Categories 列使用value.split("|").length() ,可以计算每个单元格中有多少不同的值。这里,我们首先让OpenRefne按照管道符“|”进行分割,然后使用length函数计算分割后的值数量。你甚至可以创建更加复杂的表达式:value.split("|").uniques().join("|")。这个表达式可以一次解决我们在第三章:高级数据操作 介绍过的移除重复值的所有操作。
创建自定义透视功能
现在该到介绍一些曾经略过未说的内容了:每次你创建一个透视,你实际上是执行了一个GREL表达式。比如,让我们点击Object Title 列下拉菜单:Facet | Customized Facets | Facet by blank. 。然后在出现的透视窗口右侧顶部中点击change 链接, OpenRefne就会显示隐藏的表达式窗口,这里你就可以自定义透视表达式,如下图所示:
我们看到空值透视的表达式是isBlank(value) 。实际上,如果值为空值的话,isBlank函数会返回true,如果非空,则返回false。我们可以做下修改。比如,我们想知道是否标题是以数字1开头的,那么这个表达式子就可以是value.startsWith(“1”) ,这样我们就能够得到一个透视,如果内容以1开头则返回true,反之返回false(出现(error)表示是值为空)
这是一个学习GREL的好机会。因为每一个透视其实都创建了一个GREL表达式,你可以学习其底层的工作方式。比如Duplicates 透视就会教你学习facetCount 函数。如果你有疑问,记得所有的表达式都可以重新编辑,你也可以通过Help页学习具体函数的用法。
如果你想创建自己的透视,完全不需要从已存在的透视再修改的方式进行。比如,如果你想对categories 列中分类数量进行透视,你可以点击Categories 列下拉菜单:Facet, Custom text facet…. 输入表达式value.split("|").length() 然后点击 OK.你会发现左侧出现了一个 Categories 透视窗口,你可以在此选择分类数量。这里你发现表达式输出的都是数字,所以你可能想做一次数字透视来替代,那么只需要选择菜单:Facet | Custom numeric facet… 这样你就可以按照数字方式进行透视了。自定义透视是探索数据细节的好方法,并且不怕数据会被误操作。
GREL排障
最后,如果你的表达式未能够满足你的要求该怎么办呢?比如,我们在第2章:分析和修改数据中,对Registration Number列应用重复透视的时候效果良好,但是对Record ID列就不怎么样,让我们修复这个问题。点击Record ID 列下拉菜单:Facets | Customized facets | Duplicates 。
请确保数据为未经过清理的源数据,否则重复项如果已经去除就无法继续操作了。
就像你预料的那样,OpenRefne 没有检测出重复项。所以让我们修改表达式,点击Change 链接,我们发现表达式如下:
facetCount(value, ‘value’, ‘Record ID’) > 1
产生这个问题的原因是value值这里是数字,而facetCount 函数只对字符串有效。解决的办法是将value 转换成字符串,如下:
facetCount(value.toString(), ‘value’, ‘Record ID’) > 1
这样就能够检测出重复项了。
你可能会有疑问:我怎么样才能找到这种解决办法呢?方法就是不断的练习和尝试。你使用OpenRefne 分析、清洗、链接了越多的数据集,你就会越加有处理感觉。另外,你也会获得越多的正则表达式和GREL知识,进而成长为一个专家。从此以后,你就可以一步步处理更复杂的数据集。本书就为你指明了方向,现在就看你的了。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









