







 该博客介绍了基于Python3.6的jieba分词组件和Scikit-Learn库,利用朴素贝叶斯算法进行中文自动分类的程序。流程包括文本预处理、外部特征描述、内部特征标引、信息资源分类。程序功能包括HTML标签去除、分词、构建TF-IDF词向量空间及多项式贝叶斯分类。遇到的问题包括Python2到Python3的语法转换,以及分类评估因数据集结构问题无法进行。
该博客介绍了基于Python3.6的jieba分词组件和Scikit-Learn库,利用朴素贝叶斯算法进行中文自动分类的程序。流程包括文本预处理、外部特征描述、内部特征标引、信息资源分类。程序功能包括HTML标签去除、分词、构建TF-IDF词向量空间及多项式贝叶斯分类。遇到的问题包括Python2到Python3的语法转换,以及分类评估因数据集结构问题无法进行。
实验主题:大规模数字化(中文)信息资源信息组织所包含的基本流程以及各个环节执行的任务。
基本流程:
如下图所示,和信息资源信息组织的基本流程类似,大规模数字化(中文)信息资源组织的基本流程也如下:1信息资源的预处理、2信息外部特征描述、3信息内部特征标引、4信息资源的分类、5得到序化的信息资源
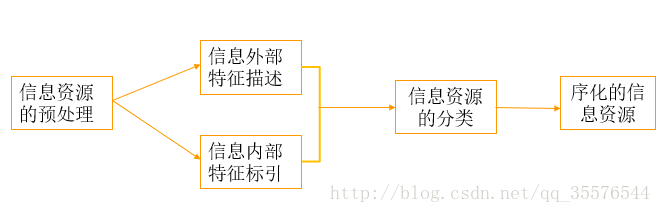
图1
1.1在信息资源预处理环节,首先要选择处理文本的范围,建立分类文本语料库:训练集语料(已经分好类的文本资源)和测试集语料(待分类的文本语料)。其次要转化文本格式,使用Python的lxml库去除html标签。最后监测句子边界,标记句子的结束。
1.2在信息外部特征描述环节,大规模数字化信息资源信息组织关注的不多,主要是对信息资源的内容、外部表现形式和物质形态(媒体类型、格式)的特征进行分析、描述、选择和记录的过程。信息外部特征序化的最终结果就是书目。
1.3在信息内部特征标引环节,指在分析信息内容基础上,用某种语言和标识符把信息的主题概念及其具有检索意义的特征标示出来,作为信息分析与检索的基础。而信息内部特征序化的结果就是代表主体概念的标引词集合。数字化信息组织更注重通过细粒度信息内容特征的语义逻辑和统计概率关系。技术上对应文本自动分类中建立向量空间模型和TF/IDF权重矩阵环节,也就是信息资源的自动标引。
1.4在信息资源分类环节,注重基于语料库的统计分类体系,在数据挖掘领域称作文档自动分类,主要任务是从文档数据集中提取描述文档的模型,并把数据集中的每个文档归入到某个已知的文档类中。常用的有朴素贝叶斯分类器和KNN分类器,在深度学习里还有卷积神经网络分类法。
1.5最后便得到了序化好的信息资源,接下来根据目的的不同有两种组织方法,一是基于资源(知识)导航、另一种是搜索引擎。大规模数字化(中文)信息资源信息组织主要是一种基于搜索引擎的信息组织,序化好的信息资源为数字图书馆搜索引擎建立倒排索引打下基础。

图22程序文件的目录层次结构
功能说明:
(1) html_demo.py程序对文本进行预处理,即用lxml去除html标签。
(2) corpus_segment.py程序利用jieba分词库对训练集和测试集分词。
(3) corpus2Bunch.py程序利用的是Scikit-Learn库中的Bunch数据结构将训练集和测试集语料库表示为变量,分别保存在train_word_bag/train_set.dat和test_word_bag/test_set.dat。
(4) TFIDF_space.py程序用于构建TF-IDF词向量空间,将训练集数据转换为TF-IDF词向量空间中的实例(去掉停用词),保存在train_word_bag/tfdifspace.dat,形成权重矩阵; 同时采用同样的训练步骤加载训练集词袋,将测试集产生的词向量映射到训练集词袋的词典中,生成向量空间模型文件test_word_bag/testspace.dat。
(5) NBayes_Predict.py程序采用多项式贝叶斯算法进行预测文本分类。
1.分词程序代码#!/usr/bin/env python
# -*- coding: UTF-8 -*-
import sys
import os
from importlib import reload
import jieba
# 配置utf-8输出环境
reload(sys)
# 保存至文件
def savefile(savepath, content):
with open(savepath, "w", encoding=' 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









