







正则表达式(Regular Expression)是一种文本模式,包括普通字符(例如,a 到 z 之间的字母)和特殊字符(称为"元字符")。
正则表达式是由普通字符及特殊字符组成的文字模式。
下面的图文来自菜鸟教程:http://www.runoob.com/regexp/regexp-syntax.html
普通字符
普通字符包括没有显式指定为元字符的所有可打印和不可打印的字符,这包括所有大写小写字母、所有数字、所有标点符号和一些其他符号。
非打印字符
非打印字符也可以是正则表达式的组成部分:
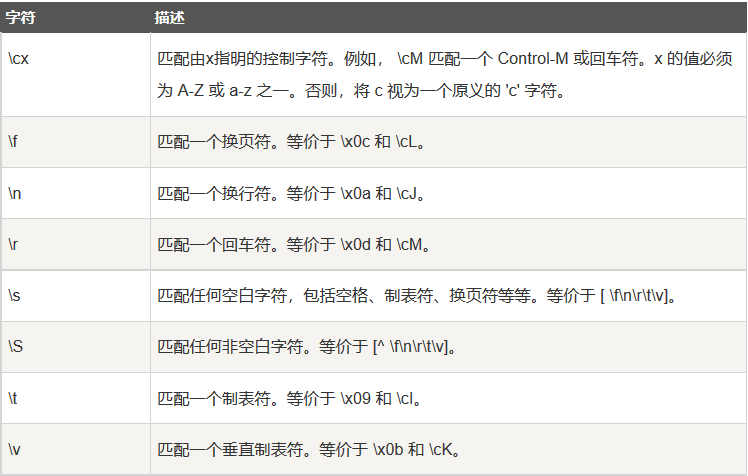
特殊字符
具有特殊含义的字符,如果想要匹配这些特殊字符,需要在它们前面加上反斜线"\"表示字符转义:
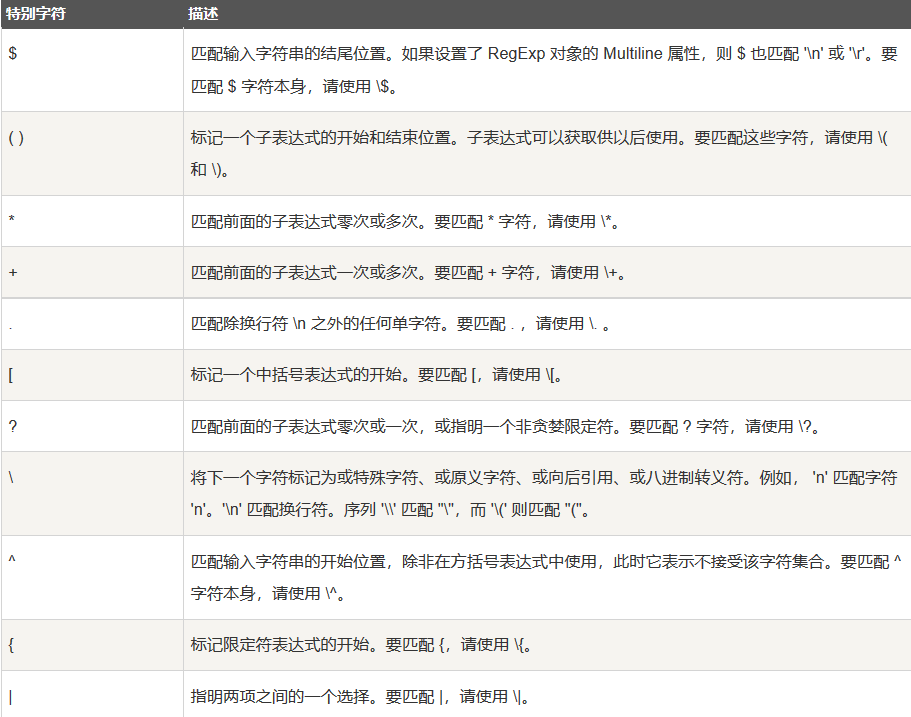
限定符
限定符用来指定正则表达式的一个给定组件必须出现多少次才能满足匹配:

*、+限定符都是贪婪的,它们会尽可能多的匹配文字,只有在他们后面加上一个?就可以实现非贪婪或者最小匹配。
定位符
定位符可以将正则表达式固定到行首或者行尾:

注意:不能将限定符和定位符一起使用,比如不允许出现^*之类的字符。
菜鸟教程资料结束
java中正则表达式的使用主要涉及到两个类:java.util.regex.Pattern和java.util.regex.Matcher。
Pattern是一个正则表达式经过编译后的表现模式;
Matcher是一个状态机器,依据Pattern对象为匹配模式对字符串展开匹配检查。
首先讲解一下Pattern类
这是正则表达式的编译表示,必须先将正则表达式(指定为字符串)编译为此类的实例。所得的实例可以用来创建一个Matcher对象以匹配任意字符序列。执行匹配的所有状态驻留在Matcher中,所以许多Matcher实例可以共享相同的Pattern。使用代码来描述就像下面一样:
Pattern p = Pattern.compile("a*b");//创建一个模式
Matcher m = p.matcher("aaaab");//创建"aaaab"字符串和"a*b"这个正则表达式的匹配
boolean b = m.matches();
boolean b = Pattern.matches("a*b","aaaab");由于Pattern实例的不可变性,这个类的实例是线程安全的。来仔细看看Pattern类常用的方法:
public static Pattern compile(String regex) throws PatternSyntaxException 给指定的正则表达式编译为模式
public String pattern() 返回编译此模式的正则表达式
public Matcher matcher(CharSequence input) 通过Pattern对象调用此方法返回Matcher类的实例,多个Matcher共享一个Pattern。
public static boolean matches(String regex, CharSequence input) throws PatternSyntaxException 编译给定的正则表达式,创建给定输入的匹配,当一个Pattern实例被多次使用的时候,编译一次并且重用他更好。
再来讲一下Matcher类,通过调用Pattern实例的matcher方法从Pattern实例创建Matcher实例,创建之后可以使用Matcher实例执行三种类型不同的匹配操作:
1、matches方法尝试对输入序列和模式进行匹配。
2、lookingAt方法尝试将输入序列从区域开头开始与模式相匹配。和matches方法类似的是总是从该区域的开头开始匹配,不同的是,它不要求整个区域匹配。
3、尝试找到匹配模式的输入序列的下一个子序列。仔细看一看Matcher类常用的方法:
public Pattern pattern() 返回该匹配器解释的模式
public MatchResult toMatchResult()将此匹配器的匹配状态返回MatchResult,结果不受此匹配器上执行的后续操作影响。
public Matcher usePattern(Pattern newPattern)更改这个匹配器对应的模式,返回新的匹配器。
public Matcher reset()重设这个匹配器,丢弃所以显式状态信息,将其附加位置设置为0。
public int start() 返回上一个匹配的起始索引。
public int end()返回最后一个字符匹配后的偏移量。
public String group()返回上一个匹配的输入子序列。
public String group(int group)返回上一次匹配操作期间由给定组捕获的输入子序列。
public int groupCount()返回此匹配模式中捕获组的数量。
public boolean matches()尝试整个区域与模式进行匹配。
public boolean find()尝试找到匹配模式的输入序列的下一个子序列。
public boolean lookingAt()尝试将输入序列和区域开始与模式相匹配,但是不要求整个区域匹配。
public String replaceAll(String replacement)将此模式匹配的输入序列的每个子序列替换为指定字符串。
public String replaceFirst(String replacement)将此模式匹配的输入序列的第一个子序列替换为给定的替换字符串。
下面来看一个简单的例子:
package test;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class ReTest {
public static void main(String[] args) {
String str = "Today is 2008-08-08, and tomorrow is 2008-08-09";
String regEx = "(\\d{4})-((\\d{2})-\\d{2})";
Pattern r = Pattern.compile(regEx);
Matcher m = r.matcher(str);
while (m.find()) {
int count = m.groupCount();
for(int i =0;i<=count;i++){
System.out.println(m.group(i));
}
}
}
}
对regex这个字符串进行编译之后的模式与字符串str进行匹配,简单看一下这个表达式:
(\\d{4})-((\\d{2})-\\d{2}),首先\d表示是数字,等价于[0-9],但是前面有一个转义字符\,因为\d中的\本身也需要进行转义,而{4}表示\d出现四次,后面同理。然后括号表示捕获组,整个匹配的子序列为捕获组0,(\\d{4})表示捕获组1,((\\d{2})-\\d{2})为捕获组2,{\\d{2}}表示捕获组3。
m.find()表示匹配到的子序列,匹配到一次之后会继续匹配下一个子序列。
然后使用m.group(i)输出捕获组i。
输出结果如下:

最后复习一下预定义字符类,别忘了在Java中前面还有个转义字符\:
















 12万+
12万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









