







两种基于层次语境信息的汉语语音合成表达风格建模方法
HIERARCHICAL CONTEXT INFORMATION
Abstract
以往关于表达性语音合成的研究主要集中在当前句current sentence。由于忽略了相邻句子的语境,导致同一篇文章的说话风格呆板,缺乏言语变化。在本文中,我们提出了一个分层的框架来从语境建模说话风格。本文提出了一种基于层次结构的语境编码器,该编码器考虑了语境中的结构关系,包括短语间关系和句子间关系,以探索更广泛的语境信息。此外,为了鼓励编码器更好地学习风格表示,我们引入了一种新的基于知识蒸馏的训练策略,为编码器的训练提供了目标。对汉语讲座数据集的客观和主观评价都表明,该方法能显著提高合成语音的自然度和表现力。
Introduction
文本到语音(text -to-speech, TTS)旨在从文本中生成可理解的、自然的语音。随着深度学习的发展,基于神经网络的TTS模型已经能够合成具有中性说话风格的高质量语音[1-3 tacotron2=DeepVoice3=Fastspeech2]。由于重复的中性语体话语逐渐使使用者感到疲劳,因此对更富表现力的话语的需求越来越大。因此,如何塑造富有表现力的说话风格已经引起了学术界和工业界越来越多的关注。
近年来,一些研究致力于通过模仿说话风格来提高生成话语的自然度和表现力。在[4,5 韵律说话人查找表内容建模组合=GST模型]中,使用参考编码器以无监督的方式从给定的参考音频中提取说话风格表示。类似地,[6VAE基础方法]将变分自编码器(VAE)[7]集成到Tacotron 2中,以学习具有更好风格解缠的潜在表示。这些方法可以生成表达性语音,但需要在推理中使用辅助输入,如人工确定标记权重和参考语音。
针对这一不足,提出了文本预测全局风格标记(TP-GST)模型[8文本直接预测音频风格],直接从文本中预测说话风格。得益于预先训练的语言模型强大的语义表示能力,例如双向编码器表示来自于transformer (BERT)[9中文预训练表征模型],一些最新的作品[10,11字符序列输入BERT得到输出结果作下游任务]使用BERT衍生的文本表示来预测说话风格。然而,在TTS数据有限的情况下,TTS模型很难以这种隐式的方式直接从文本中学习说话风格。同时,上述的文本预测方法在合成时只考虑当前的句子,不足以对表达性的说话风格进行建模。对于同一输入文本,这些模型未能捕捉到相邻句子的不同语境可能带来的不同语音变化(如语调、节奏、重音、情绪等),导致合成语音语音风格不灵活[12]。这与人们认为当前讲话的说话风格在很大程度上应受语境的影响的过程是相悖的。一些研究也表明,考虑更广泛的语境信息有助于表达性言语合成[12,13]。
在本文中,我们提出了一个分层的框架来从语境建模说话风格,以提高合成语音的表达能力。引入分层上下文编码器,提取更有效的上下文信息,预测当前话语的说话风格。编码器试图从两个层面探讨上下文中的结构关系,一个是句子中的短语间关系,另一个是包含多个句子的较长的上下文窗口中的句子间关系。受并行工作[14]中知识提炼的启发,我们进一步引入了一个参考编码器,从语音中提取风格嵌入,并使用它来明确而不是隐式地指导语音风格的预测

对汉语讲座数据集的客观和主观评价都表明,该模型可以合成表达能力更强的语音,并能更好地模拟语音变化。我们还构造了一个简单的上下文编码器,不使用句子间的关系进行比较。评价结果验证了分级上下文编码器的有效性。
Method

我们提出的模型的体系结构如图1所示。它由三个主要部分组成:参考编码器、层次上下文编码器和基于FastSpeech 2[3]的序列到序列声学模型。使用参考编码器从参考语音中提取风格嵌入,使用层次上下文编码器从上下文中预测风格嵌入。受到知识蒸馏的启发,使用参考编码器的输出来指导分层内容编码器的培训。然后将风格嵌入添加到音素编码器输出中,并传递给声学模型的方差适配器,以便更准确地预测语音变化,生成具有表达风格的语音。各组成部分的详细信息如下。
2.1 Reference encoder
2.2 XLNet and Hierarchical Context Encoder
为了提高合成语音的表现力和自然度,我们结合XLNet和分层上下文编码器,从固定数量的过去、现在和将来的句子中预测说话风格。图1(b)说明了该模块的实现过程
2.2.1 XLNet
XLNet[17]是最近提出的一种预训练语言模型,在许多自然语言处理任务中取得了优异的性能,尤其是在阅读理解和文本分类方面[18]。与BERT相比,XLNet可以直接处理较长的文本,甚至段落级别的文本,不受长度限制,从而获得考虑更广上下文范围的语义信息。因此,我们使用更适合我们的任务的XLNet来派生出更好的文本表示作为输入

2.2.2 Hierarchical Context Encoder
由于训练任务的限制,预训练语言模型的短语级表示没有明确考虑上下文的结构关系。以往在TTS中预测风格的尝试[8,10]更多的是以一种简单的方式利用文本,仅通过使用递归神经网络(RNN)或注意模块对短语间关系建模。这很难捕捉到短语和句子之间的层次关系。为了提取更有效的上下文信息,我们设计了一个层次式的上下文编码器,用于预测当前句子的说话风格,灵感来自[19]。
sentence level attention:
每个句子对整篇文章的类别贡献不一样,所以给sentence添加attention机制,有权重地选择哪个sentence对文章的贡献。
word level attention:
再细分,每个sentence包含多个word,每个word对sentence的贡献也不一样,所以在word级别再添加一层attention。

层次化语境编码器包含注意网络的两个层次,即短语间和句子间,如图1©所示。这两个注意网络具有相似的架构,包括双向的GRU[15]和缩放的点积注意模块[20]。短语间注意网络根据句子中的每个短语和短语间关系获得句子级表征。首先,将句子中的短语嵌入传递给一个双向GRU,得到考虑时间关系的短语级表示;并不是所有的短语对句子意义的贡献都是相同的,因此引入一个比例的点积注意力来计算每个短语的权重,并将它们聚合到一个句子级嵌入中。这可以表述为

同样,整句间注意网络根据上下文中的句子嵌入和句间关系预测说话风格。与短语间注意网络相比,双向GRU的相应输出中增加了一个额外的位置编码,该编码对我们的实验性能有较大的影响,提供了句子的相对位置信息。最后,整句间注意网络输出当前话语的说话风格嵌入。值得注意的是,这个层次结构编码了短语间和句子间的关系,这有助于成为一个层次信息感知模型。
2.3 Acoustic Model
我们采用FastSpeech 2作为声学模型,并进行了一些改变,如图1所示。首先,将来自参考编码器或层次上下文编码器的风格嵌入复制到音素层,并添加到音素编码器的输出中,然后传递到方差预测器,如图1(b)所示。这种修正允许方差预测器更准确地预测持续时间、音调和能量。其次,将长度调节器移动到方差预测器之后,以预测音素水平上的变化而不是帧水平上的变化,进一步提高了语音质量???
2.4 Model Training
一般来说,在TTS数据有限的情况下,声学模型从文本中隐式学习说话风格是具有挑战性的。为了鼓励分层上下文编码器更好地学习样式表示,本文提出的模型采用知识蒸馏策略,分三个步骤进行训练。
第一步,利用配对数据对声学模型和参考编码器进行联合训练,以无监督的方式得到训练良好的语音风格提取器。然后从训练集中所有话语中提取的风格嵌入可以看作是ground truth speaking风格表示。
在第二步中,我们利用知识蒸馏将知识从参考编码器转移到层次上下文编码器。也就是说,我们使用ground-truth风格嵌入作为目标,指导从语境预测说话风格表示,仅用于训练层次式语境编码器。
最后,我们以较低的学习速率联合训练声学模型和分层上下文编码器,进一步提高合成语音的自然度。
3. EXPERIMENTS
3.1 Training Setup
所有的模型都是在一个内部的单讲汉语讲座数据集上训练的,该数据集包含了一位以汉语为母语的男性的大约7小时的演讲。说话风格因话语而异,语速、音高和能量在话语中波动很大。数据集共有4700个音频片段,其中200个用于验证,100个用于测试,其余用于培训。在特征提取方面,我们将原始波形转换为采样率为24kHz、帧大小为1200、跳大小为240的80dim mel-spectrogram。每句话开始和结束时的沉默被修剪。音素持续时间由Montreal Forced Aligner[23]工具提取。实验使用了一个开放源代码的汉语短语级预训练模型XLNet-base model。现在句的语境由两个过去句、两个将来句和现在句本身组成。然后将原始文本转换为音素序列,并以一些韵律标记作为声学模型的输入。我们先用180k步训练声学模型和参考编码器,然后用20k步训练分层上下文编码器,用20k步适应分层上下文编码器和声学模型。所有的培训都是在NVIDIA V100 GPU上进行的,批处理大小为16。采用Adam优化器,β1 = 0.9, β2 = 0.98。热身策略是在4000步之前使用的。此外,使用训练有素的HIFI-GAN[24]作为声码器生成波形。
3.2. Compared Methods
本文实现了两种基于FastSpeech 2的模型进行比较,详细描述如下:
FastSpeech 2:原始FastSpeech 2,与2.3节中提出的模型有一些变化。
XLNet-FastSpeech 2:受【10】启发,我们将XLNet与FastSpeech 2结合,建立了端到端TTS模型,同时考虑了上下文信息。在XLNet-FastSpeech 2中,我们构造了一个不使用句子间关系的普通上下文编码器。从XLNet获得的相同短语嵌入直接传递到GRU层,它的最终状态用作样式嵌入。通过这种方式,上下文信息将以一种简单的方式来考虑,而不是层次结构。
3.3. Subjective Evaluation
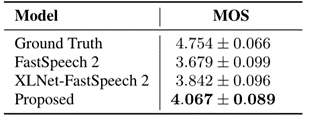
我们使用平均意见分数(MOS)测试来评估生成的演讲的自然度和表现力。在测试集中随机抽取句子。20名母语为汉语的人被要求听生成的演讲,并按1到5分的间隔打分。MOS结果如表1所示。可以看出,FastSpeech 2和Ground Truth之间存在较大的差距,这表明用表达性数据集训练TTS模型是困难的。我们提出的方法实现了最佳MOS为4.067,比FastSpeech 2高出0.388,比XLNet-FastSpeech 2高出0.225。也有研究表明,该方法合成的语音具有更丰富的表现力,尤其是在语调、节奏和重音方面
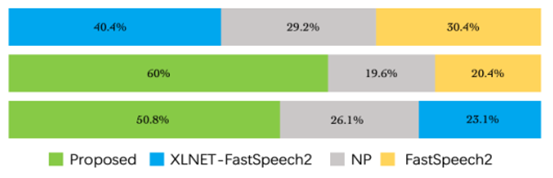
MOS和ABX偏好测试都表明,我们提出的方法在自然性和表现力方面明显优于两个基线。与仅使用带韵律标签的音素序列作为输入的FastSpeech 2相比,我们提出的模型和XLNet-FastSpeech 2的性能都更好,这表明考虑上下文信息确实有助于表达性语音合成。我们提出的模型与XLNet-FastSpeech 2相比,也做了进一步的改进,XLNet-FastSpeech 2只简单地使用了上下文信息。结果表明,引入层次上下文编码器和利用知识蒸馏策略可以更好地为TTS语言风格建模。
3.4. Objective Evaluation
采用基音和能量的均方根误差(RMSE)、持续时间的均方根误差(MSE)和mel倒谱失真(MCD)作为客观评价指标
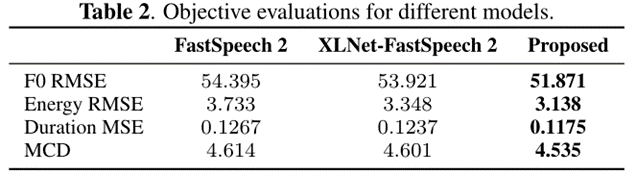
结果表明,我们提出的模型可以合成更接近地面真实的语音,特别是在语音变化方面,如音高、能量和持续时间
3.5. Ablation Study
将知识蒸馏策略从本文提出的方法中移除,即在没有参考编码器引导的情况下预测风格嵌入,得到-0.346 CMOS。**这表明从语境中明确学习口语风格表征更适合这项任务。**此外,我们进一步删除了分层上下文编码器中的整句间部分,即通过普通上下文编码器预测说话风格,我们发现它的结果是-0.609 CMOS,这表明考虑上下文中的结构关系对表达性语音合成的重要性
3.6. Case Study
为了探究语境信息对合成话语表达能力的影响,我们以不同语境为例,合成同一话语:
i)使用ground-truth context(原始语境);
ii)随机选取4个句子及其本身作为上下文(无关上下文);
iii)只使用当前句(没有上下文)。

这些语音的mel-谱图、音高轮廓和持续时间有明显的差异。在原始语境下生成的语音比其他语音包含更丰富的音高变化。
尤其可以发现,原始语境产生的话语通过更高的音高值强调“must”(红框)一词,更符合ground truth。对比没有语境的原文,我们发现语境信息是塑造说话风格的必要条件。
在对比原文和无关上下文时,发现有效的上下文信息比任意的语义信息更有帮助。我们的模型成功地学习了口语风格建模中有意义的语境信息,证明了所提方法的有效性。
案例研究结果表明,从语境中构建说话风格可以有效地影响合成语音的重音、音高和时长。这样,同一句话可以根据语境以多种方式合成,从而达到更自然、更有表现力的语音合成
4. CONCLUSIONS
在本文中,我们提出了一个分层的框架来从语境建模说话风格,以实现表达性语音合成。为了更好地利用上下文信息,引入了层次化上下文编码器。**本文采用一种新的知识蒸馏训练策略,进一步提高了TTS风格预测的性能。**客观评价和主观评价的实验结果表明,该方法能显著提高合成语音的自然度和表现力。在消融研究中,分层上下文编码器和知识蒸馏的有效性也得到了证明















 1101
1101











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









