










创建scrapy的项目请参考:https://blog.csdn.net/qq_35723619/article/details/83614670
items的实现:
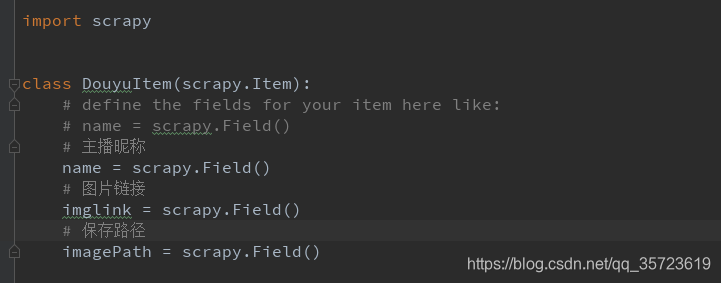
DouyumeinvSpider创建:
这次我们爬去的是json数据包:我们可以通过network监控: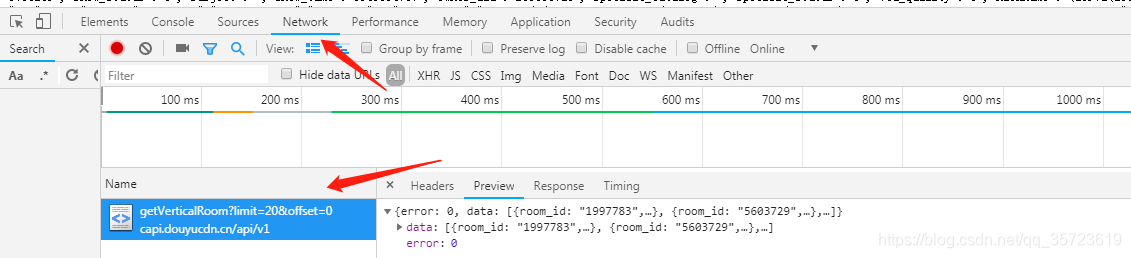
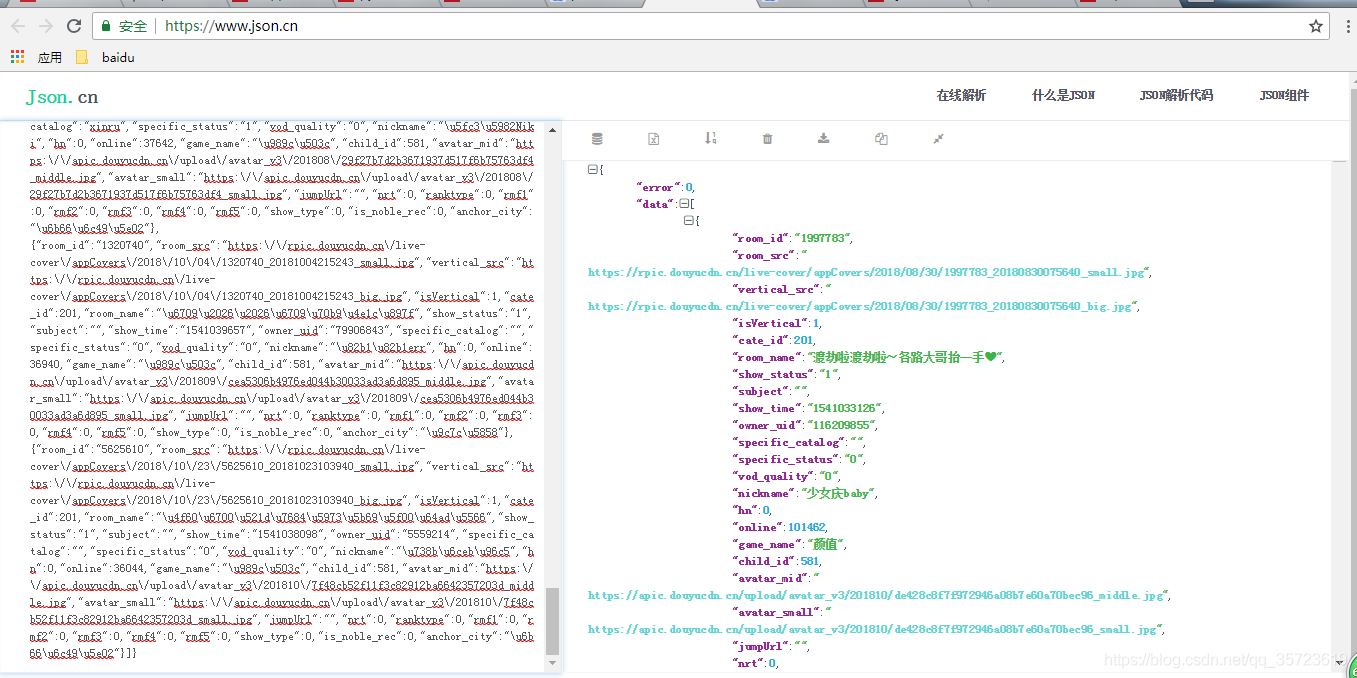
# -*- coding: utf-8 -*-
import scrapy
import json
from douyu.items import DouyuItem
class DouyumeinvSpider(scrapy.Spider):
name = 'douyumeinv'
allowed_domains = ['capi.douyucdn.cn']
offset = 0
url = "http://capi.douyucdn.cn/api/v1/getVerticalRoom?limit=20&offset="
start_urls = [url + str(offset)]
def parse(self, response):
data = json.loads(response.text)['data']
for each in data:
item = DouyuItem()
item['name'] = each['nickname']
item['imglink'] = each['vertical_src']
yield item
self.offset += 20
yield scrapy.Request(self.url + str(self.offset), callback=self.parse)
配置setting
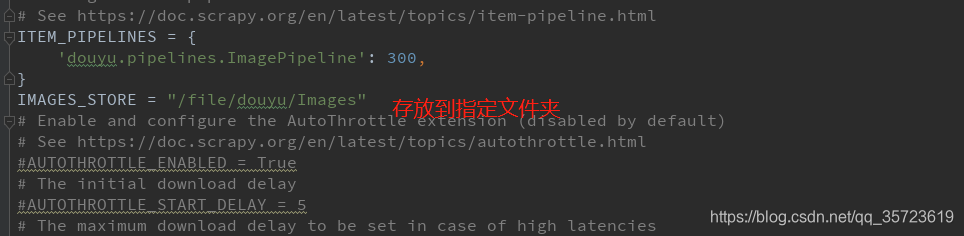
创建ImagePipeline我们这里继承了scrapy处理图片的ImagesPipeline重新构建
get_media_requests(self, item, info)和item_completed(self, results, item, info)方法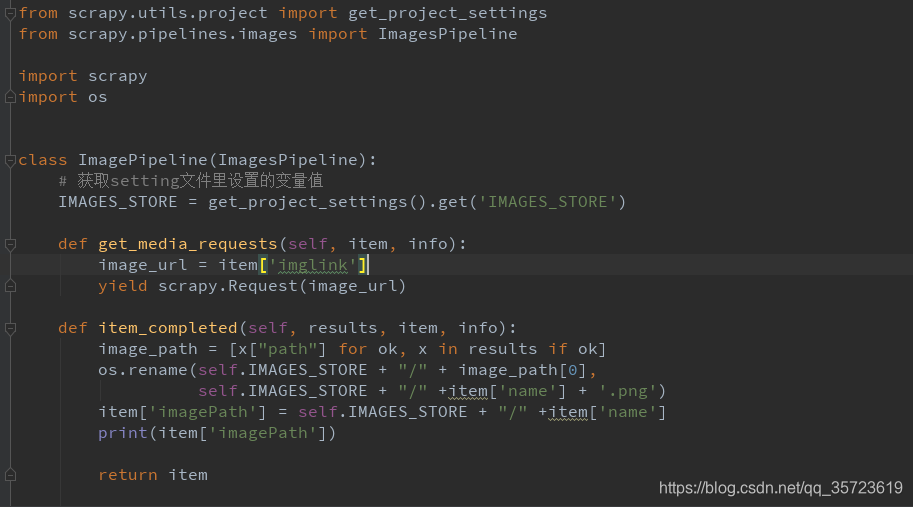
运行结果:
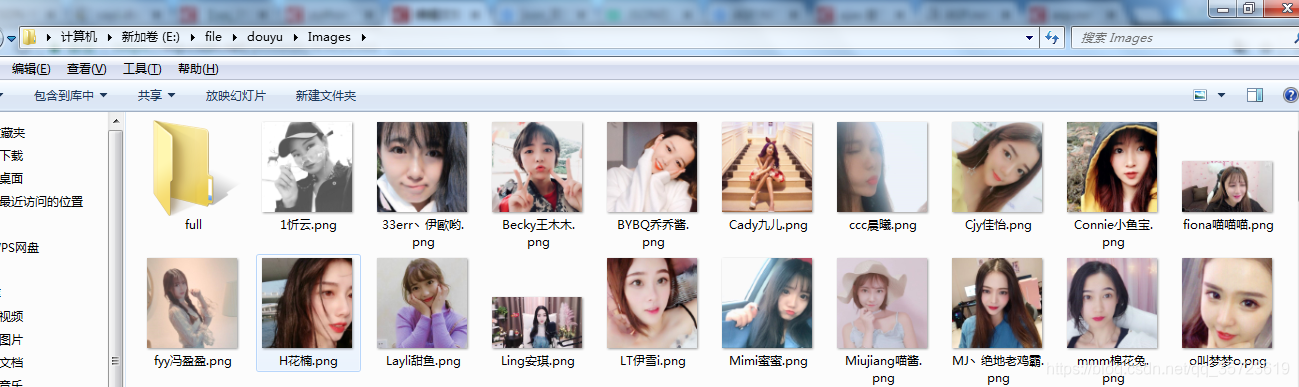
谢谢浏览!!!!














 180
180











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









