










一、概述
复合事件处理(简称
Complex Event Processing:CEP)是一种基于动态环境中事件流的分析技术,事件在这里通常是有意义的状态变化,通过分析事件间的关系,利用过滤、关联、聚合等技术,根据事件间的时序关系和聚合关系制定检测规则,持续地从事件流中查询出符合要求的事件序列,最终分析得到更复杂的复合事件。官方文档
特征
- 目标:从有序的简单事件流中发现一些高阶特征;
- 输入:一个或多个简单事件构成的事件流;
- 处理:识别简单事件之间的内在联系,多个符合一定规则的简单事件构成复杂事件;
- 输出:满足规则的复杂事件。

二、核心组件
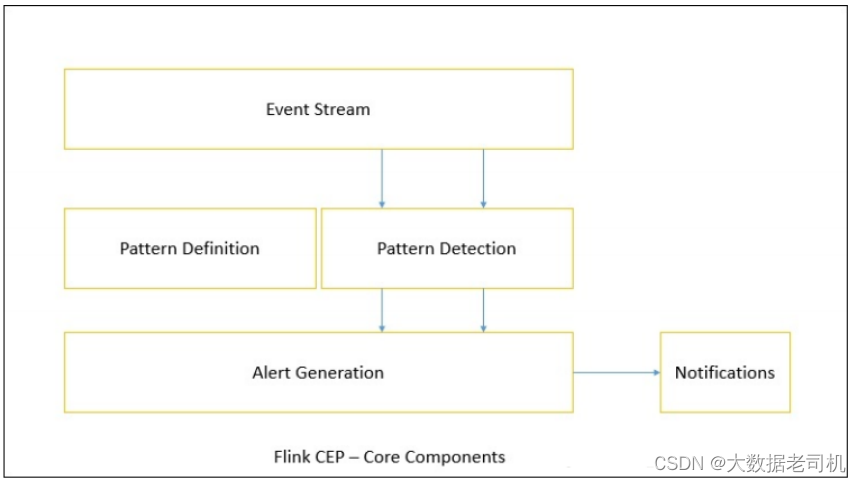
Flink为CEP提供了专门的Flink CEP library,它包含如下组件:
Event Stream、Pattern定义、Pattern检测和生成Alert。
首先,开发人员要在DataStream流上定义出模式条件,之后Flink CEP引擎进行模式检测,必要时生成警告。
三、Pattern API
处理事件的规则,被叫作模式(Pattern)。Flink CEP提供了Pattern API用于对输入流数据进行复杂事件规则定义,用来提取符合规则的事件序列。模式大致分为三类:
1)个体模式(Individual Patterns)
组成复杂规则的每一个单独的模式定义,就是个体模式。个体模式可以是一个单例或者循环模式。单例模式只接受一个事件,循环模式可以接受多个事件。
1、量词
在FlinkCEP中,你可以通过这些方法指定循环模式:
pattern.oneOrMore(),指定期望一个给定事件出现一次或者多次的模式;pattern.times(#ofTimes),指定期望一个给定事件出现特定次数的模式,可以在一个个体模式后追加量词,也就是指定循环次数,更多量词介绍请看下面示例:
对一个命名为start的模式,以下量词是有效的:
// 期望出现4次
start.times(4)
// 期望出现0或者4次
start.times(4).optional()
// 期望出现2、3或者4次
start.times(2, 4)
// 期望出现2、3或者4次,并且尽可能的重复次数多
start.times(2, 4).greedy()
// 期望出现0、2、3或者4次
start.times(2, 4).optional()
// 期望出现0、2、3或者4次,并且尽可能的重复次数多
start.times(2, 4).optional().greedy()
// 期望出现1到多次
start.oneOrMore()
// 期望出现1到多次,并且尽可能的重复次数多
start.oneOrMore().greedy()
// 期望出现0到多次
start.oneOrMore().optional()
// 期望出现0到多次,并且尽可能的重复次数多
start.oneOrMore().optional().greedy()
// 期望出现2到多次
start.timesOrMore(2)
// 期望出现2到多次,并且尽可能的重复次数多
start.timesOrMore(2).greedy()
// 期望出现0、2或多次
start.timesOrMore(2).optional()
// 期望出现0、2或多次,并且尽可能的重复次数多
start.timesOrMore(2).optional().greedy()
2、条件
对每个模式你可以指定一个条件来决定一个进来的事件是否被接受进入这个模式,指定判断事件属性的条件可以通过
pattern.where()、pattern.or()或者pattern.until()方法。这些可以是IterativeCondition或者SimpleCondition。按不同的调用方式,可以分成以下几类:
- 简单条件:这种类型的条件扩展了前面提到的IterativeCondition类,它决定是否接受一个事件只取决于事件自身的属性。
start.where(event => event.getName.startsWith("foo"))
// 最后,你可以通过pattern.subtype(subClass)方法限制接受的事件类型是初始事件的子类型。
start.subtype(classOf[SubEvent]).where(subEvent => ... /* 一些判断条件 */)
- 组合条件:这适用于任何条件,你可以通过依次调用where()来组合条件。 最终的结果是每个单一条件的结果的逻辑AND。如果想使用OR来组合条件,你可以像下面这样使用or()方法。
pattern.where(event => ... /* 一些判断条件 */).or(event => ... /* 一些判断条件 */)
- 停止条件:如果使用循环模式(oneOrMore()和oneOrMore().optional()),建议使用.until()作为停止条件,以便清理状态。
pattern.oneOrMore().until(event => ... /* 替代条件 */)
- 迭代条件:这是最普遍的条件类型。使用它可以指定一个基于前面已经被接受的事件的属性或者它们的一个子集的统计数据来决定是否接受时间序列的条件。
// 下面是一个迭代条件的代码,它接受"middle"模式下一个事件的名称开头是"foo", 并且前面已经匹配到的事件加上这个事件的价格小于5.0。 迭代条件非常强大,尤其是跟循环模式结合使用时。
middle.oneOrMore()
.subtype(classOf[SubEvent])
.where(
(value, ctx) => {
lazy val sum = ctx.getEventsForPattern("middle").map(_.getPrice).sum
value.getName.startsWith("foo") && sum + value.getPrice < 5.0
}
)
更多模式操作请看官网文档
2)组合模式(Combining Patterns,也叫模式序列)
模式序列由一个初始模式作为开头,如下所示:
val start : Pattern[Event, _] = Pattern.begin("start")
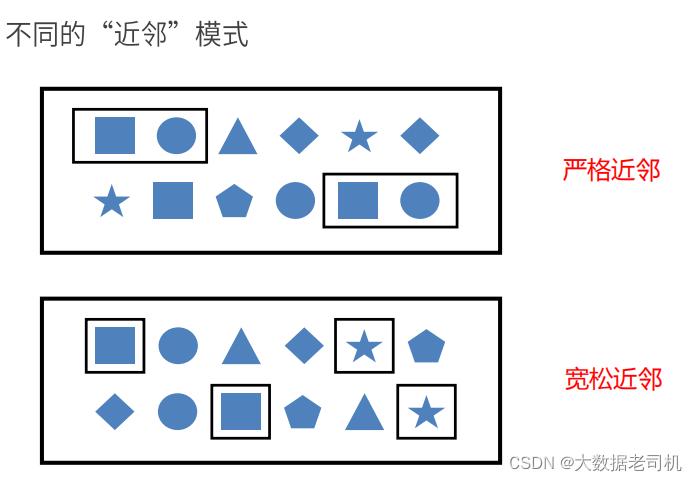
1、事件之间的连续策略
-
严格连续(严格近邻): 期望所有匹配的事件严格的一个接一个出现,中间没有任何不匹配的事件。
next() -
松散连续(宽松近邻): 忽略匹配的事件之间的不匹配的事件。
followedBy() -
不确定的松散连续(非确定性宽松近邻): 更进一步的松散连续,允许忽略掉一些匹配事件的附加匹配。
followedByAny()
除了以上模式序列外,还可以定义“不希望出现某种近邻关系”:
notNext():如果不想后面直接连着一个特定事件notFollowedBy():如果不想一个特定事件发生在两个事件之间的任何地方。
【温馨提示】①所有模式序列必须以.begin()开始;②模式序列不能以.notFollowedBy()结束;③“not”类型的模式不能被optional所修饰;④可以为模式指定时间约束,用来要求在多长时间内匹配有效。
// 严格连续
val strict: Pattern[Event, _] = start.next("middle").where(...)
// 松散连续
val relaxed: Pattern[Event, _] = start.followedBy("middle").where(...)
// 不确定的松散连续
val nonDetermin: Pattern[Event, _] = start.followedByAny("middle").where(...)
// 严格连续的NOT模式
val strictNot: Pattern[Event, _] = start.notNext("not").where(...)
// 松散连续的NOT模式
val relaxedNot: Pattern[Event, _] = start.notFollowedBy("not").where(...)
也可以为模式定义一个有效时间约束。 例如,你可以通过
pattern.within()方法指定一个模式应该在10秒内发生。 这种时间模式支持处理时间和事件时间。
【温馨提示】一个模式序列只能有一个时间限制。如果限制了多个时间在不同的单个模式上,会使用最小的那个时间限制。
next.within(Time.seconds(10))
2、循环模式中的连续性
对于循环模式(例如
oneOrMore()和times())),默认是松散连续。如果想使用严格连续,你需要使用consecutive()方法明确指定, 如果想使用不确定松散连续,你可以使用allowCombinations()方法。
-
严格连续:{a b3 c} – "b1"之后的"d1"导致"b1"被丢弃,同样"b2"因为"d2"被丢弃。
-
松散连续:{a b1 c},{a b1 b2 c},{a b1 b2 b3 c},{a b2 c},{a b2 b3 c},{a b3 c} - "d"都被忽略了。
-
不确定松散连续:{a b1 c},{a b1 b2 c},{a b1 b3 c},{a b1 b2 b3 c},{a b2 c},{a b2 b3 c},{a b3 c} - 注意{a b1 b3 c},这是因为"b"之间是不确定松散连续产生的。
3)模式组(Group of Pattern)
也可以定义一个模式序列作为begin,followedBy,followedByAny和next的条件。这个模式序列在逻辑上会被当作匹配的条件, 并且返回一个
GroupPattern,可以在GroupPattern上使用oneOrMore(),times(#ofTimes), times(#fromTimes, #toTimes),optional(),consecutive(),allowCombinations()。
val start: Pattern[Event, _] = Pattern.begin(
Pattern.begin[Event]("start").where(...).followedBy("start_middle").where(...)
)
// 严格连续
val strict: Pattern[Event, _] = start.next(
Pattern.begin[Event]("next_start").where(...).followedBy("next_middle").where(...)
).times(3)
// 松散连续
val relaxed: Pattern[Event, _] = start.followedBy(
Pattern.begin[Event]("followedby_start").where(...).followedBy("followedby_middle").where(...)
).oneOrMore()
// 不确定松散连续
val nonDetermin: Pattern[Event, _] = start.followedByAny(
Pattern.begin[Event]("followedbyany_start").where(...).followedBy("followedbyany_middle").where(...)
).optional()
更多模式操作,请看官方文档
匹配后跳过策略
对于一个给定的模式,同一个事件可能会分配到多个成功的匹配上。为了控制一个事件会分配到多少个匹配上,你需要指定跳过策略AfterMatchSkipStrategy。 有五种跳过策略,如下:
NO_SKIP: 每个成功的匹配都会被输出。SKIP_TO_NEXT: 丢弃以相同事件开始的所有部分匹配。SKIP_PAST_LAST_EVENT: 丢弃起始在这个匹配的开始和结束之间的所有部分匹配。SKIP_TO_FIRST: 丢弃起始在这个匹配的开始和第一个出现的名称为PatternName事件之间的所有部分匹配。SKIP_TO_LAST: 丢弃起始在这个匹配的开始和最后一个出现的名称为PatternName事件之间的所有部分匹配。
【温馨提示】当使用
SKIP_TO_FIRST和SKIP_TO_LAST策略时,需要指定一个合法的PatternName。
四、Pattern检测
在指定了要寻找的模式后,该把它们应用到输入流上来发现可能的匹配了。为了在事件流上运行你的模式,需要创建一个PatternStream。 给定一个输入流input,一个模式pattern和一个可选的用来对使用事件时间时有同样时间戳或者同时到达的事件进行排序的比较器comparator, 你可以通过调用如下方法来创建PatternStream:
val input : DataStream[Event] = ...
val pattern : Pattern[Event, _] = ...
var comparator : EventComparator[Event] = ... // 可选的
val patternStream: PatternStream[Event] = CEP.pattern(input, pattern, comparator)
五、Flink CEP应用场景
- 风险控制
对用户异常行为模式进行实时检测,当一个用户发生了不该发生的行为,判定这个用户是不是有违规操作的嫌疑。
- 策略营销
用预先定义好的规则对用户的行为轨迹进行实时跟踪,对行为轨迹匹配预定义规则的用户实时发送相应策略的推广。
- 运维监控
灵活配置多指标、多依赖来实现更复杂的监控模式。
六、安装Kafka(window)
1)下载kafka
下载地址:https://kafka.apache.org/downloads.html
2)配置环境变量

3)创建相关文件
%KAFKA_HOME%\logs
%KAFKA_HOME%\data\zookeeper
4)修改配置
%KAFKA_HOME%\config\zookeeper.properties
###%KAFKA_HOME%换成具体目录
dataDir=%KAFKA_HOME%\data\zookeeper
%KAFKA_HOME%\config\server.properties
###%KAFKA_HOME%换成具体目录
log.dirs=%KAFKA_HOME%\logs
5)启动zookeeper和kafka服务
$ d:
$ cd %KAFKA_HOME%
启动zookeeper服务(必须先起zookeeper服务再起kafka服务)
.\bin\windows\kafka-server-start.bat .\config\server.properties

【问题】The input line is too long. The syntax of the command is incorrect.
【原因与解决方案】是由于kafka安装目录太深,所以这里就直接把kafka放在D盘目录下,记得把上面的环境变量和配置也得改一下,重新启动服务
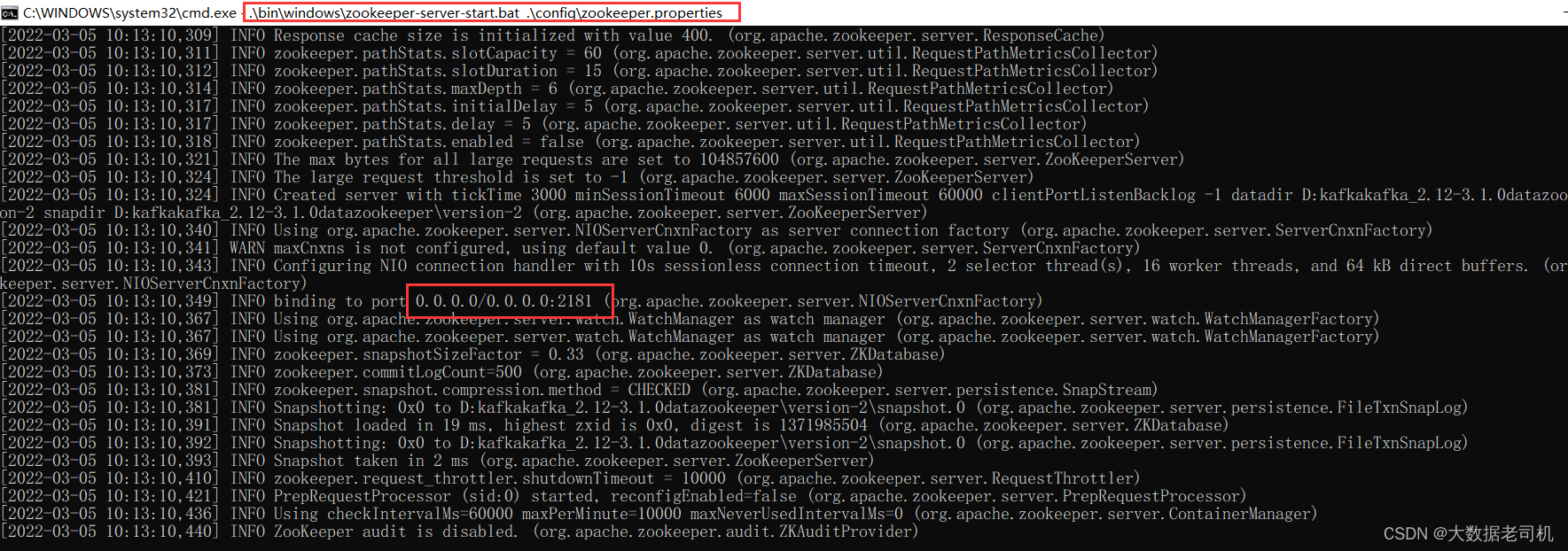
- 启动zookeeper服务
.\bin\windows\zookeeper-server-start.bat .\config\zookeeper.properties
###查看服务端口
netstat -ano|findstr 2181
### 参数详解
# -a 显示所有连接和侦听端口。
# -n 以数字形式显示地址和端口号。
# -o 显示拥有的与每个连接关联的进程 ID。

- 启动Kafka服务
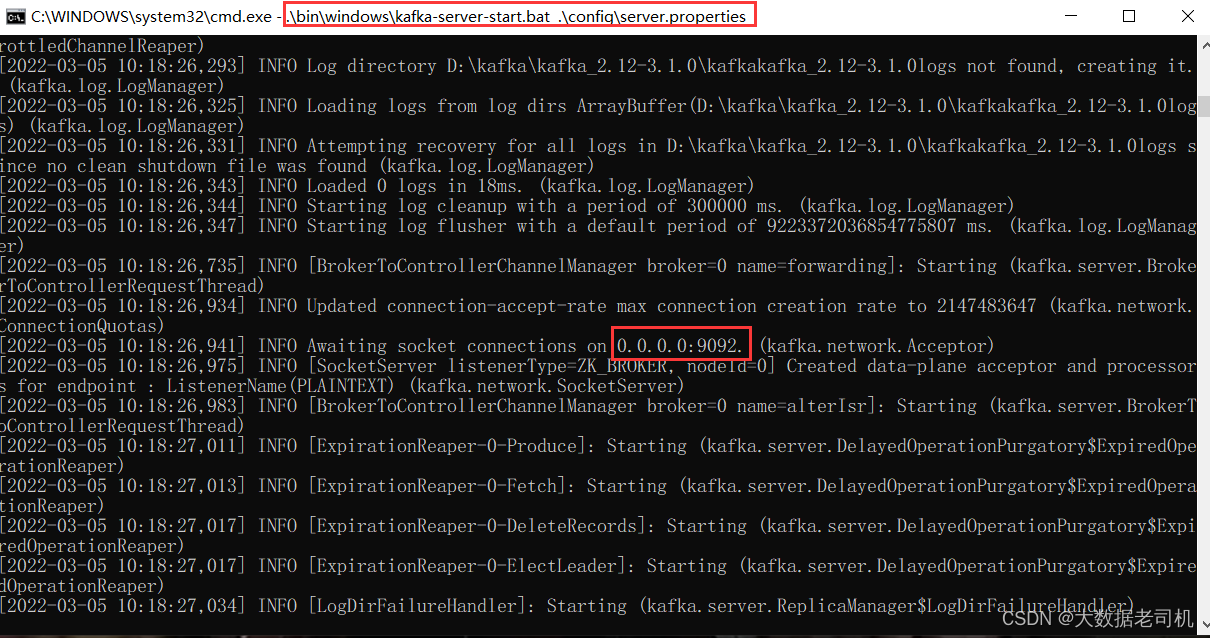
.\bin\windows\kafka-server-start.bat .\config\server.properties
###查看服务端口
netstat -ano|findstr 9092
### 参数详解
# -a 显示所有连接和侦听端口。
# -n 以数字形式显示地址和端口号。
# -o 显示拥有的与每个连接关联的进程 ID。

6)常用操作
- 创建Topic
kafka-topics.bat --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1 --topic cep
###查看topic
kafka-topics.bat --list --bootstrap-server localhost:9092

- 创建生产者
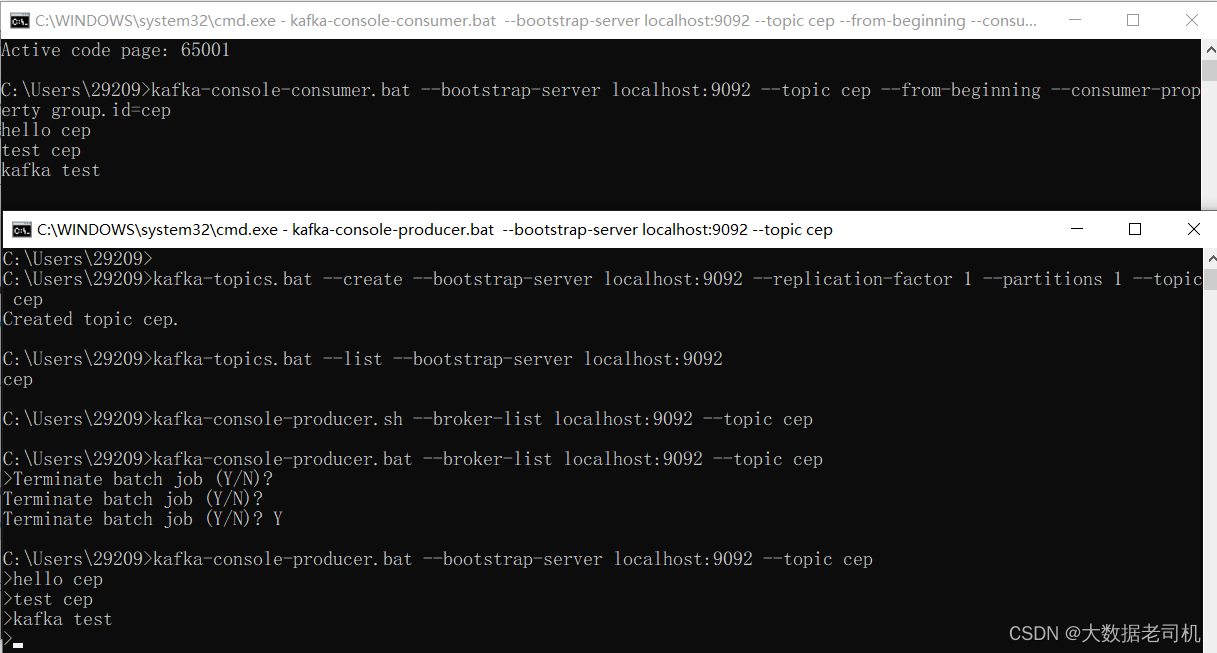
kafka-console-producer.bat --bootstrap-server localhost:9092 --topic cep
- 创建消费者
kafka-console-consumer.bat --bootstrap-server localhost:9092 --topic cep --from-beginning --consumer-property group.id=cep
- 查看数据挤压
kafka-consumer-groups.bat --bootstrap-server localhost:9092 --describe --group cep

LOG-END-OFFSET:下一条将要被加入到日志的消息的位移
CURRENT-OFFSET:当前消费的位移
LAG:消息堆积量:消息中间件服务端中所留存的消息与消费掉的消息之间的差值即为消息堆积量也称之为消费滞后量
七、Flink CEP实战(java版)
参考:https://github.com/wooplevip/flink-tutorials
1)开发流程
- 读取事件流并转换为DataStream
- 算子操作(可选)
- 必须指定水位线(watermark)
- 定义事件模式(event pattern)
- 在指定事件流上应用事件模式
- 匹配或选择符合条件的事件,并产生告警
【温馨提示】GitHub源码中没有指定水位线(watermark),无法触发事件
2)Flink CEP快速上手
1、配置Maven
为了使用Flink CEP,需要导入pom依赖。(pom.xml完整配置)
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<artifactId>bigdata-test2023</artifactId>
<groupId>com.bigdata.test2023</groupId>
<version>1.0-SNAPSHOT</version>
</parent>
<modelVersion>4.0.0</modelVersion>
<artifactId>flink-java</artifactId>
<!-- DataStream API maven settings begin -->
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>1.14.3</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.12</artifactId>
<version>1.14.3</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.12</artifactId>
<version>1.14.3</version>
</dependency>
<!-- DataStream API maven settings end -->
<!-- Table and SQL maven settings begin-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner_2.12</artifactId>
<version>1.14.3</version>
<scope>provided</scope>
</dependency>
<!-- 上面已经设置过了 -->
<!--<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.12</artifactId>
<version>1.14.3</version>
<scope>provided</scope>
</dependency>-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-common</artifactId>
<version>1.14.3</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-csv</artifactId>
<version>1.14.3</version>
</dependency>
<!-- Table and SQL maven settings end-->
<!-- Hive Catalog maven settings begin -->
<!-- Flink Dependency -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-hive_2.12</artifactId>
<version>1.14.3</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge_2.12</artifactId>
<version>1.14.3</version>
<scope>provided</scope>
</dependency>
<!-- Hive Dependency -->
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>3.1.2</version>
<scope>provided</scope>
</dependency>
<!-- Hive Catalog maven settings end -->
<!--hadoop start-->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>3.3.1</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.3.1</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-common</artifactId>
<version>3.3.1</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-jobclient</artifactId>
<version>3.3.1</version>
<scope>provided</scope>
</dependency>
<!--hadoop end-->
<!-- cep -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-cep_2.12</artifactId>
<version>1.14.3</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_2.12</artifactId>
<version>1.14.3</version>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-compress</artifactId>
<version>1.21</version>
</dependency>
</dependencies>
</project>
2、下载项目
【温馨提示】直接下载项目可能运行不了,需要稍微改一下
$ git clone https://github.com/wooplevip/flink-tutorials.git
3、执行解析
源数据
1,VALID,2
2,VALID,200
3,VALID,3
4,INVALID,1
5,VALID,1
6,VALID,300
7,VALID,600
- CEPExample.java
package com.woople.streaming.cep;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.cep.CEP;
import org.apache.flink.cep.PatternStream;
import org.apache.flink.cep.functions.PatternProcessFunction;
import org.apache.flink.cep.pattern.Pattern;
import org.apache.flink.cep.pattern.conditions.SimpleCondition;
import org.apache.flink.core.fs.FileSystem;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.util.Collector;
import java.time.Duration;
import java.time.LocalDateTime;
import java.time.ZoneOffset;
import java.util.List;
import java.util.Map;
import java.util.Properties;
public class CEPExample{
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
/***
* kafka
*
* Properties properties = new Properties();
* properties.setProperty("bootstrap.servers", "localhost:9092");
* properties.setProperty("group.id", "flinkCEP");
*
* DataStream<String> dataStream = env
* .addSource(new FlinkKafkaConsumer<>("cep", new SimpleStringSchema(), properties));
*
*/
/**
* socket
* DataStreamSource<String> dataStream = env.socketTextStream("localhost", 9999, "\n");
*/
// 1.读取事件流并转换为DataStream(上面也列举了socket和kafka,看自己需要怎么选择,因为我这里是测试,所以简单的用filesystem作为数据源)
DataStream<String> dataStream = env.readTextFile("flink-java/data/cep-data001.txt");
// 2.算子操作
DataStream<Event> input = dataStream.map((MapFunction<String, Event>) value -> {
String[] v = value.split(",");
return new Event(LocalDateTime.now(), v[0], EventType.valueOf(v[1]), Double.parseDouble(v[2]));
});
// 3. 指定水位线(watermark)
SingleOutputStreamOperator<Event> watermarks = input.assignTimestampsAndWatermarks(
// 最大乱序程度
WatermarkStrategy.<Event>forBoundedOutOfOrderness(Duration.ofSeconds(3))
.withTimestampAssigner(
/*(SerializableTimestampAssigner<Event>) (event, recordTimestamp) -> event.toEpochMilli(event.getEventTime())*/
new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event event, long recordTimestamp) {
return event.toEpochMilli(event.getEventTime());
}
}
)
);
// 4.定义事件模式(event pattern)
Pattern<Event, ?> pattern = Pattern.<Event>begin("start").where(
new SimpleCondition<Event>() {
@Override
public boolean filter(Event event) {
System.out.println(event + " from start");
return event.getType() == EventType.VALID && event.getVolume() < 10;
}
}
).next("end").where(
new SimpleCondition<Event>() {
@Override
public boolean filter(Event event) {
System.out.println(event + " from end");
return event.getType() == EventType.VALID && event.getVolume() > 100;
}
}
);
// 5.在指定事件流上应用事件模式
PatternStream<Event> patternStream = CEP.pattern(watermarks, pattern);
// 6.匹配或选择符合条件的事件,并产生告警
DataStream<Alert> result = patternStream.process(
new PatternProcessFunction<Event, Alert>() {
@Override
public void processMatch(
Map<String, List<Event>> pattern,
Context ctx,
Collector<Alert> out) {
System.out.println(pattern);
out.collect(new Alert("111", "CRITICAL"));
}
});
result.print();
// result.writeAsText("flink-java/data/sink003");
env.execute("Flink cep example");
}
}
- Event.java
package com.woople.streaming.cep;
import java.time.LocalDateTime;
import java.time.ZoneOffset;
import java.util.Objects;
public class Event {
private EventType type;
private double volume;
private String id;
private LocalDateTime eventTime;
public Event(LocalDateTime eventTime, String id, EventType type, double volume) {
this.id = id;
this.type = type;
this.volume = volume;
this.eventTime = eventTime;
}
public double getVolume() {
return volume;
}
public String getId() {
return id;
}
public EventType getType() {
return type;
}
public LocalDateTime getEventTime() {
return eventTime;
}
public void setEventTime(LocalDateTime eventTime) {
this.eventTime = eventTime;
}
@Override
public String toString() {
return "Event(" + id + ", " + type.name() + ", " + volume + ")";
}
@Override
public boolean equals(Object obj) {
if (obj instanceof Event) {
Event other = (Event) obj;
return type.name().equals(other.type.name()) && volume == other.volume && id.equals(other.id);
} else {
return false;
}
}
@Override
public int hashCode() {
return Objects.hash(type.name(), volume, id);
}
public long toEpochMilli(LocalDateTime dt) {
ZoneOffset zoneOffset8 = ZoneOffset.of("+8");
return dt.toInstant(zoneOffset8).toEpochMilli();
}
}
- Alert.java
package com.woople.streaming.cep;
import java.util.Objects;
public class Alert {
private String id;
private String level;
public Alert(String id, String level) {
this.id = id;
this.level = level;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Alert alert = (Alert) o;
return Objects.equals(id, alert.id) &&
Objects.equals(level, alert.level);
}
@Override
public int hashCode() {
return Objects.hash(id, level);
}
@Override
public String toString() {
return "Alert{" +
"id='" + id + '\'' +
", level='" + level + '\'' +
'}';
}
}
- EventType
package com.woople.streaming.cep;
public enum EventType {
INVALID, VALID;
}
结果分析
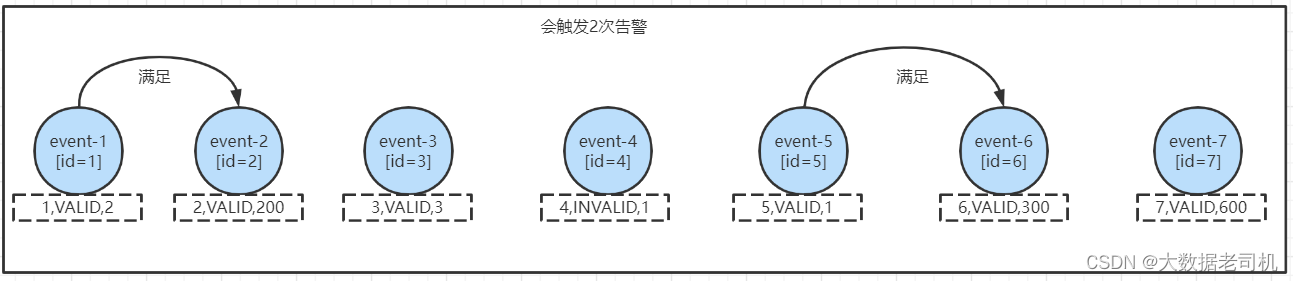
- 如果使用的是
next("end"),只会触发2次告警,分别为:
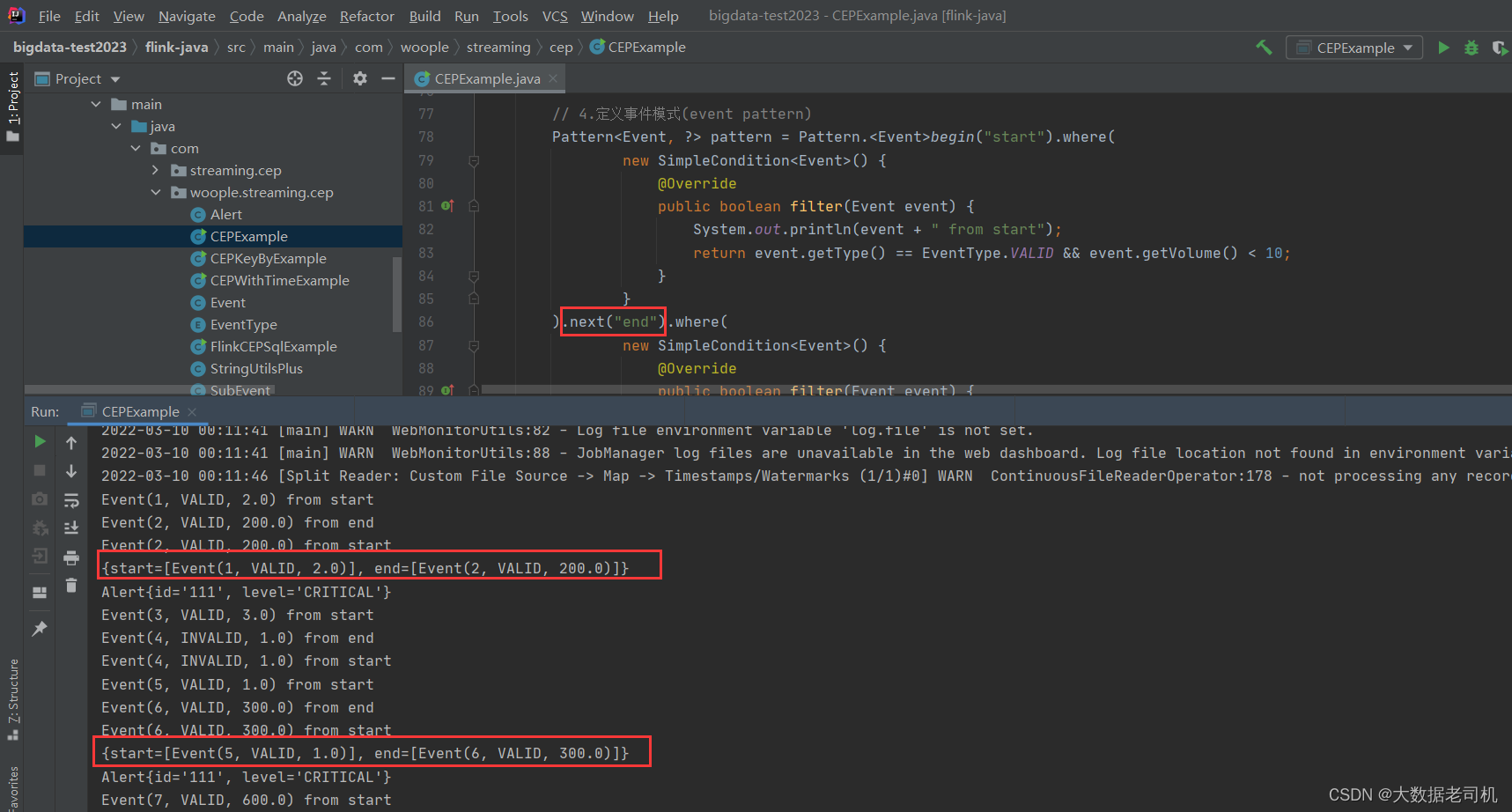
这就是因为next必须要满足两个连续的事件都符合条件。
- 如果使用的是
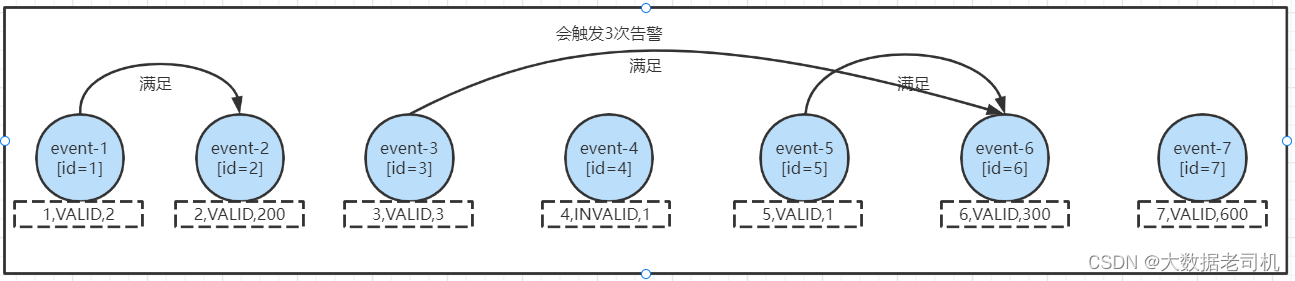
followedBy("end"),会触发3次告警,分别为:
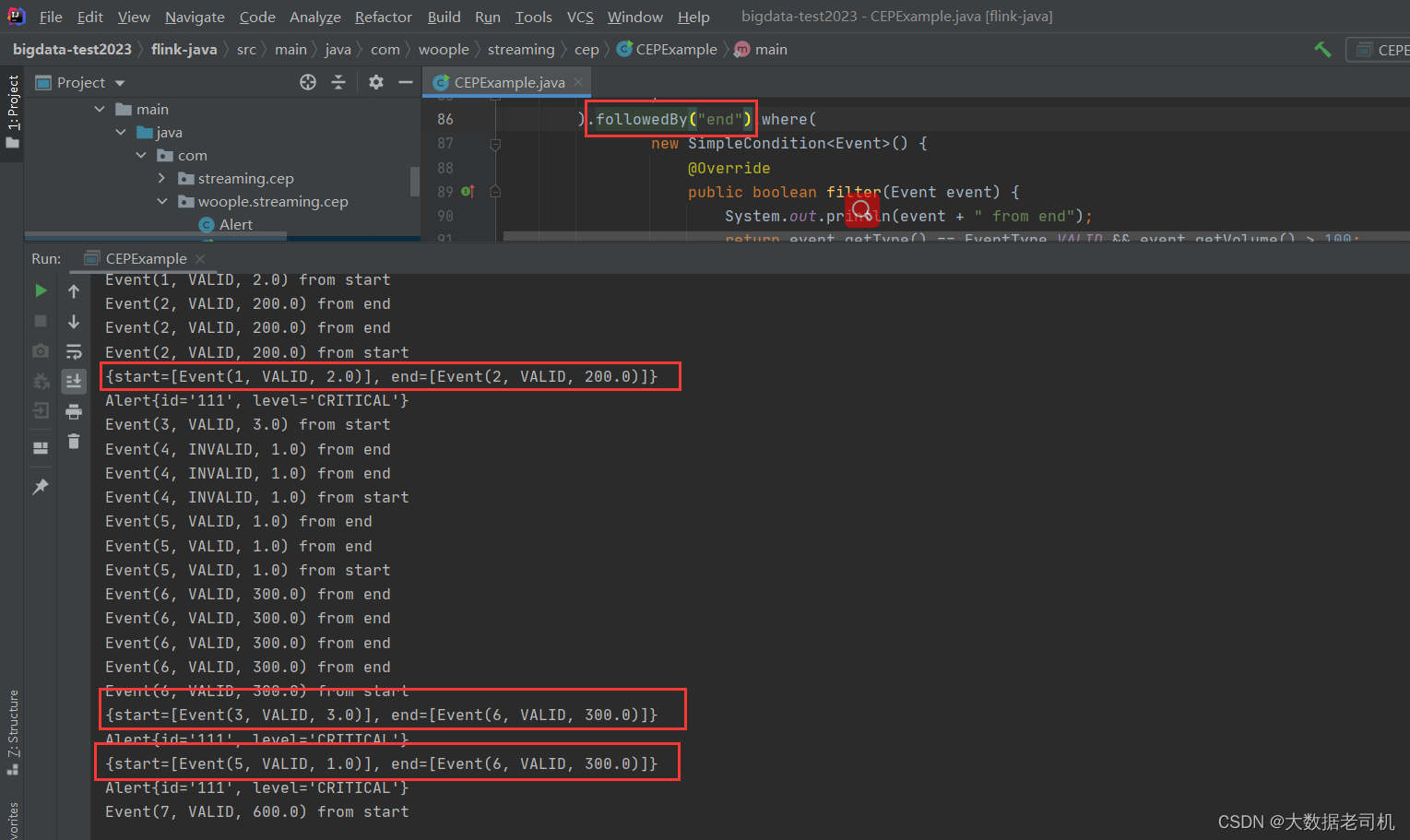
可以看到满足条件的event中间可以有不满足的事件产生,第一个条件不重复。
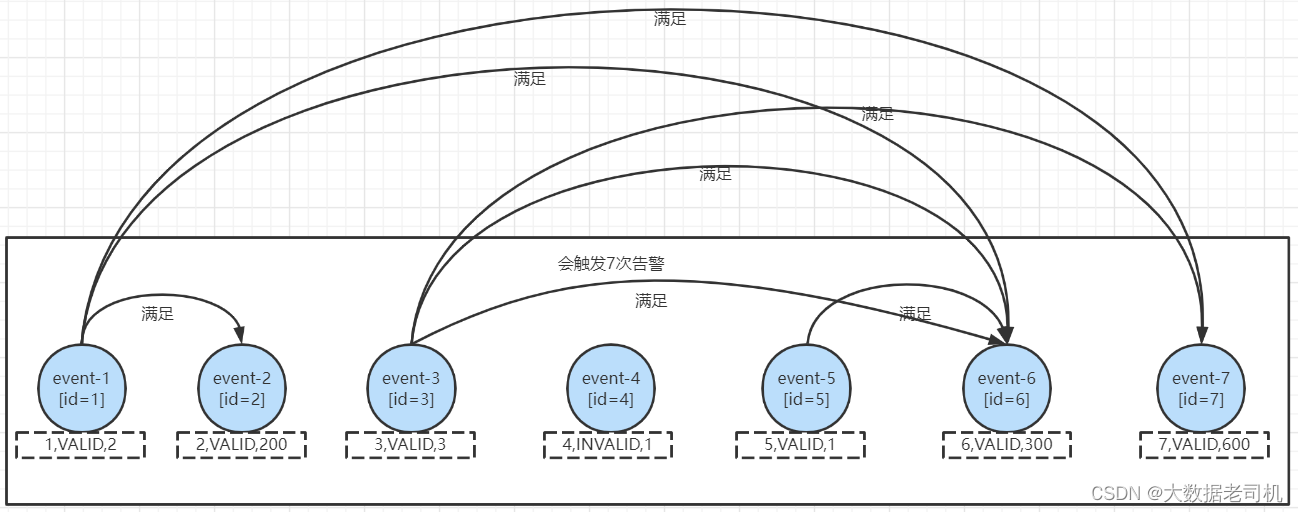
- 如果使用的是
followedByAny("end"),会触发7次告警,分别为

followedByAny("end")和followedBy("end")主要的区别就是所有满足条件的两个事件都会触发告警,即便前一个条件已经生效过,第一个条件可重复。
其它几个例子就演示了,都差不多,稍微改一下就ok了
3)Flink CEP进阶
- CEPKeyByExample.java
package com.woople.streaming.cep;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.cep.CEP;
import org.apache.flink.cep.PatternStream;
import org.apache.flink.cep.pattern.Pattern;
import org.apache.flink.cep.pattern.conditions.SimpleCondition;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import java.time.Duration;
import java.time.LocalDateTime;
import java.util.List;
import java.util.Map;
import java.util.Properties;
public class CEPKeyByExample {
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
/***
* kafka
*
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "localhost:9092");
properties.setProperty("group.id", "flinkCEP");
DataStream<String> dataStream = env
.addSource(new FlinkKafkaConsumer<>("cep", new SimpleStringSchema(), properties));*/
/**
* socket
*
* DataStreamSource<String> dataStream = env.socketTextStream("localhost", 9999, "\n");
*/
// Filesystem
DataStream<String> dataStream = env.readTextFile("flink-java/data/cep-data001.txt");
DataStream<Event> input = dataStream.map((MapFunction<String, Event>) value -> {
String[] v = value.split(",");
return new Event(LocalDateTime.now(), v[0], EventType.valueOf(v[1]), Double.parseDouble(v[2]));
});
SingleOutputStreamOperator<Event> watermarks = input.assignTimestampsAndWatermarks(
// 最大乱序程度
WatermarkStrategy.<Event>forBoundedOutOfOrderness(Duration.ofSeconds(3))
.withTimestampAssigner(
/*(SerializableTimestampAssigner<Event>) (event, recordTimestamp) -> event.toEpochMilli(event.getEventTime())*/
new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event event, long recordTimestamp) {
return event.toEpochMilli(event.getEventTime());
}
}
)
);
Pattern<Event, ?> pattern = Pattern.<Event>begin("start").where(
new SimpleCondition<Event>() {
@Override
public boolean filter(Event event) {
System.out.println(event + " from start");
return event.getType() == EventType.VALID && event.getVolume() < 10;
}
}
).followedBy("end").where(
new SimpleCondition<Event>() {
@Override
public boolean filter(Event event) {
System.out.println(event + " from end");
return event.getType() == EventType.VALID && event.getVolume() > 100;
}
}
);
PatternStream<Event> patternStream = CEP.pattern(watermarks.keyBy(Event::getId), pattern);
DataStream<Alert> result = patternStream.select((Map<String, List<Event>> p) -> {
List<Event> first = p.get("start");
List<Event> second = p.get("end");
return new Alert("111", "CRITICAL");
});
result.print();
env.execute("Flink cep example");
}
}
4)Flink CEP SQL用法
package com.woople.streaming.cep;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.formats.csv.CsvRowDeserializationSchema;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.AssignerWithPeriodicWatermarks;
import org.apache.flink.streaming.api.watermark.Watermark;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.TableSchema;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
import java.util.Properties;
public class FlinkCEPSqlExample {
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
env.setParallelism(1);
final StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
final TableSchema tableSchema = new TableSchema(new String[]{"symbol","tax","price", "rowtime"}, new TypeInformation[]{Types.STRING, Types.STRING, Types.LONG, Types.SQL_TIMESTAMP});
final TypeInformation<Row> typeInfo = tableSchema.toRowType();
final CsvRowDeserializationSchema.Builder deserSchemaBuilder = new CsvRowDeserializationSchema.Builder(typeInfo).setFieldDelimiter(',');
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "localhost:9092");
FlinkKafkaConsumer<Row> myConsumer = new FlinkKafkaConsumer<>(
"cep",
deserSchemaBuilder.build(),
properties);
myConsumer.setStartFromLatest();
DataStream<Row> stream = env.addSource(myConsumer).assignTimestampsAndWatermarks(new BoundedOutOfOrdernessGenerator());
tableEnv.registerDataStream("Ticker", stream, "symbol,tax,price,rowtime.rowtime");
Table result = tableEnv.sqlQuery("SELECT * " +
"FROM Ticker " +
" MATCH_RECOGNIZE( " +
" PARTITION BY symbol " +
" ORDER BY rowtime " +
" MEASURES " +
" A.price AS firstPrice, " +
" B.price AS lastPrice " +
" ONE ROW PER MATCH " +
" AFTER MATCH SKIP PAST LAST ROW " +
" PATTERN (A+ B) " +
" DEFINE " +
" A AS A.price < 10, " +
" B AS B.price > 100 " +
" )");
final TableSchema tableSchemaResult = new TableSchema(new String[]{"symbol","firstPrice","lastPrice"}, new TypeInformation[]{Types.STRING, Types.LONG, Types.LONG});
final TypeInformation<Row> typeInfoResult = tableSchemaResult.toRowType();
DataStream ds = tableEnv.toAppendStream(result, typeInfoResult);
ds.print();
env.execute("Flink CEP via SQL example");
}
private static class BoundedOutOfOrdernessGenerator implements AssignerWithPeriodicWatermarks<Row> {
private final long maxOutOfOrderness = 5000;
private long currentMaxTimestamp;
@Override
public long extractTimestamp(Row row, long previousElementTimestamp) {
System.out.println("Row is " + row);
long timestamp = StringUtilsPlus.dateToStamp(String.valueOf(row.getField(3)));
currentMaxTimestamp = Math.max(timestamp, currentMaxTimestamp);
System.out.println("watermark:" + StringUtilsPlus.stampToDate(String.valueOf(currentMaxTimestamp - maxOutOfOrderness)));
return timestamp;
}
@Override
public Watermark getCurrentWatermark() {
return new Watermark(currentMaxTimestamp - maxOutOfOrderness);
}
}
}
未完待续~
















 785
785











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









