










一、概述
HBase 是一个面向列式存储的分布式数据库,其设计思想来源于 Google 的 BigTable 论文。HBase 底层存储基于 HDFS 实现,集群的管理基于 ZooKeeper 实现。HBase 良好的分布式架构设计为海量数据的快速存储、随机访问提供了可能,基于数据副本机制和分区机制可以轻松实现在线扩容、缩容和数据容灾,是大数据领域中 Key-Value 数据结构存储最常用的数据库方案。
官方文档:https://hbase.apache.org/book.html
GitHub地址:https://github.com/apache/hbase
HBase特点:
- 易扩展:Hbase 的扩展性主要体现在两个方面,一个是基于运算能力(RegionServer) 的扩展,通过增加 RegionSever 节点的数量,提升 Hbase 上层的处理能力;另一个是基于存储能力的扩展(HDFS),通过增加 DataNode 节点数量对存储层的进行扩容,提升 HBase 的数据存储能力。
- 海量存储:HBase 作为一个开源的分布式 Key-Value 数据库,其主要作用是面向 PB 级别数据的实时入库和快速随机访问。这主要源于上述易扩展的特点,使得 HBase 通过扩展来存储海量的数据。
- 列式存储:Hbase 是根据列族来存储数据的。列族下面可以有非常多的列。列式存储的最大好处就是,其数据在表中是按照某列存储的,这样在查询只需要少数几个字段时,能大大减少读取的数据量。
- 高可靠性:WAL 机制保证了数据写入时不会因集群异常而导致写入数据丢失,Replication 机制保证了在集群出现严重的问题时,数据不会发生丢失或损坏。而且 Hbase 底层使用 HDFS,HDFS 本身也有备份。
- 稀疏性:在 HBase 的列族中,可以指定任意多的列,为空的列不占用存储空间,表可以设计得非常稀疏。
二、Hbase的优缺点
1)Hbase优点
- 列的可以动态增加,并且列为空就不存储数据,节省存储空间.
- Hbase自动切分数据,使得数据存储自动具有水平scalability.
- Hbase可以提供高并发读写操作的支持
2)Hbase缺点
- 不能支持条件查询,只支持按照Row key来查询.
- 暂时不能支持Master server的故障切换,当Master宕机后,整个存储系统就会挂掉.
三、HBase数据模型
HBase是运行在Hadoop集群上的一个数据库,与传统的数据库有严格的ACID(原子性、一致性、隔离性、持久性)要求不一样,HBase降低了这些要求从而获得更好的扩展性,它更适合存储一些非结构化和半结构化的数据。
1)逻辑模型
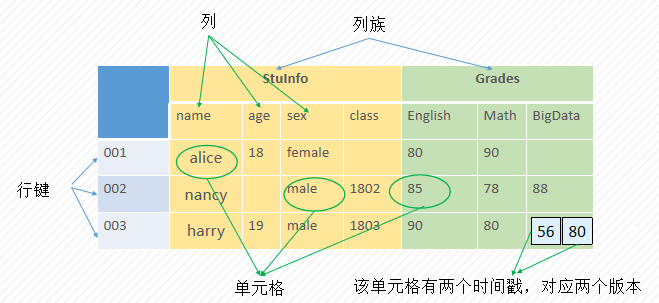
- 表命名空间(Namespace):表命名空间不是强制的,当想把多个表分到一个组去统一管理的时候才会用到表命名空间;
- 表(Table):Hbase采用表来组织数据;一个表由一个或多个列族组成。数据属性,比如超时时间(TTL)、压缩算法(COMPRESSION)等,都在列族的定义中定义。
- 行(Row):一个行包含多个列,这些列通过列族来分类。行中数据所属列族只能只能从该表所定义的列族选择,否则会得到一个NoSuchColumnFamilyException。由于HBase是一个列式数据库,所以一个行中的数据可以分布在不同的RegionServer上。
- 列标识(Column Qualifier):多个列组成一个行。列族和列经常用Column
- 列族(Column Family):一个table有许多个列族,列族是列的集合,属于表结构,也是表的基本访问控制单元。
- Column Family:Column Qualifier形式标识;
- 时间戳(Timestamp):用来区分数据的不同版本;
- 单元格(Cell):通过行、列族、列、时间戳可以确定一个单元格,存储的数据没有数据类型,是字节数组byte[]。
以上几个概念以及它们之间的关系可以用下图表示:
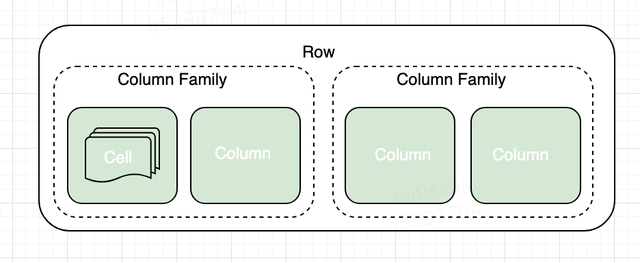
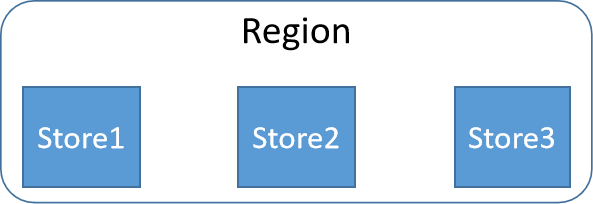
2)物理模型
实际存储方式:每个Region由多个Store构成,每个Store保存一个column family。
-
逻辑数据模型中空白cell在物理上是不存储的,因此若一个请求为要获取t8时间的contents:html,他的结果就是空。相似的,若请求为获取t9时间的anchor:my.look.ca,结果也是空。但是,如果不指明时间,将会返回最新时间的行,每个最新的都会返回。
-
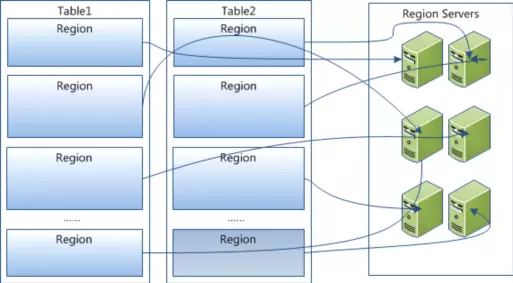
在一个HBase中,存储了很多HBase表,当表中包含的行数量非常庞大,无法在一台机器上存储时,需要分布存储到多台机器上,需要根据行键的值对表中进行分区,每个行分区被称为“Region”。
-
Master主服务器把不同的Region分配到不同的Region服务器上,同一个Region不会拆分到多个Region服务器上,每个Region服务器负责管理一个Region集合,通常每个Region服务器上会放置10~1000个Region。
四、HBase 架构与原理
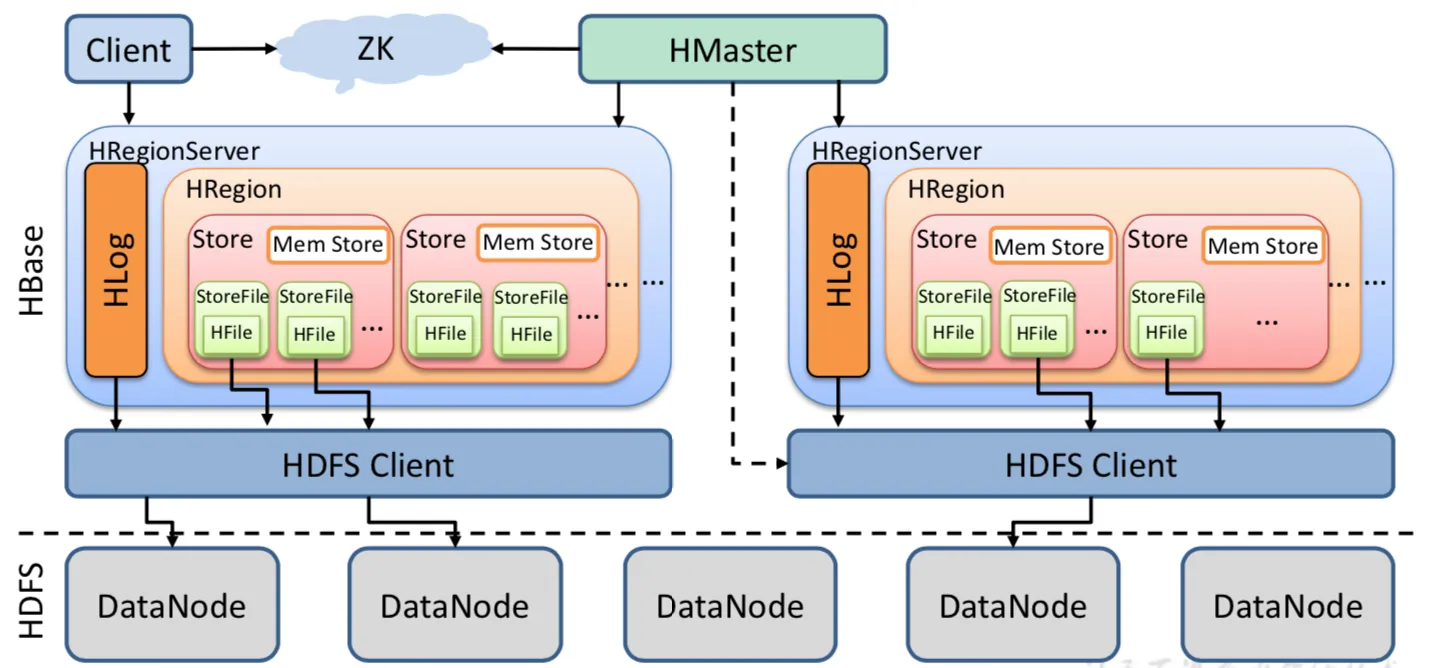
1)HBase读流程
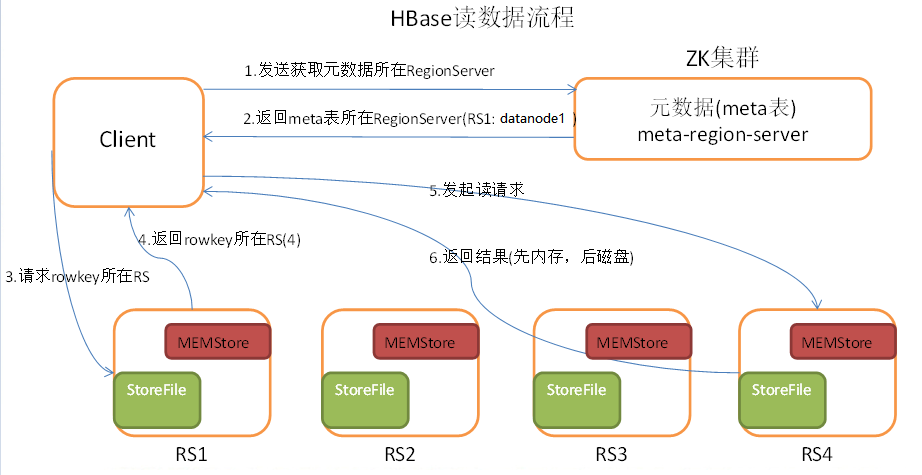
2)HBase写流程
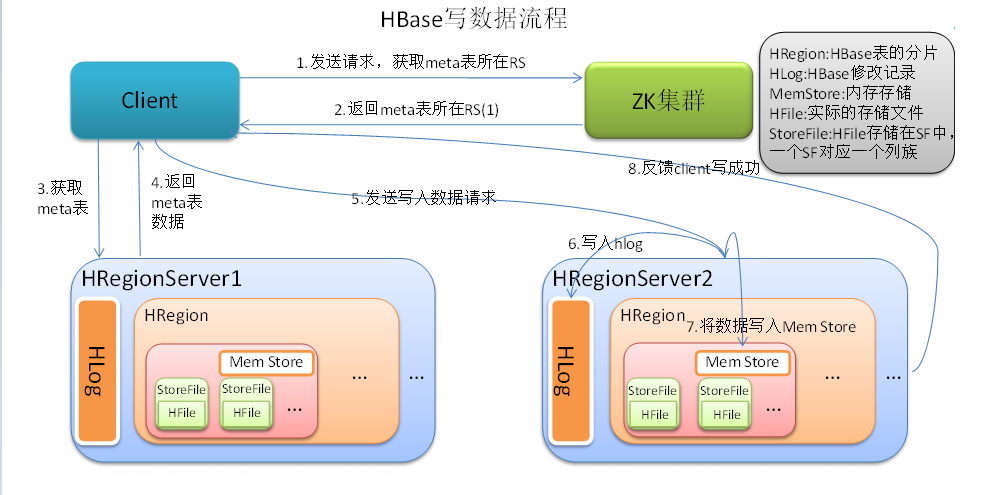
数据flush过程
- 当MemStore数据达到阈值(默认是128M,老版本是64M),将数据刷到硬盘,将内存中的数据删除,同时删除HLog中的历史数据;
- 并将数据存储到HDFS中;
数据合并过程
- 当数据块达到4块,Hmaster将数据块加载到本地,进行合并;
- 当合并的数据超过256M,进行拆分,将拆分后的Region分配给不同的HregionServer管理;
- 当HregionServer宕机后,将HregionServer上的hlog拆分,然后分配给不同的HregionServer加载,修改.META.;
【温馨提示】HLog会同步到HDFS。
五、环境部署(全分布模式)
HBase有三种运行模式:
- 单机模式:只在一台计算机运行,这种模式下,HBase所有进程包括Maste、HRegionServer、和Zookeeper都在同一个JVM中运行,存储机制采用本地文件系统,没有采用分布式文件系统HDFS。
- 伪分布模式:只在一台计算机运行,这种模式下,HBase所有进程都运行在不同一个节点,在一个节点上模拟了一个具有HBase完整功能的微型集群,存储机制采用分布式文件系统HDFS,但是HDFS的NameNode和DataNode都位于同一台计算机上。
- 全分布模式:在多台计算机上运行,这种模式下,HBase的守护进程运行在多个节点上,形成一个真正意义上的集群,存储机制采用分布式文件系统HDFS,且HDFS的NameNode和DataNode位于不同计算机上。
1)环境准备
| 主机名 | IP | 角色 |
|---|---|---|
| local-168-182-110 | 192.168.182.110 | NodeManager、QuorumPeerMain、HMaster、DataNode、HRegionServer |
| local-168-182-111 | 192.168.182.111 | DataNode、HRegionServer、SecondaryNameNode、NodeManager、QuorumPeerMain |
| local-168-182-112 | 192.168.182.112 | NodeManager、HRegionServer、DataNode、QuorumPeerMain |
2)安装JDK
官网下载:https://www.oracle.com/java/technologies/downloads/
百度云下载
链接:https://pan.baidu.com/s/1-rgW-Z-syv24vU15bmMg1w
提取码:8888
cd /opt/
tar -xf jdk-8u212-linux-x64.tar.gz
# 在文件加入环境变量/etc/profile
export JAVA_HOME=/opt/jdk1.8.0_212
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
# source加载
source /etc/profile
# 查看jdk版本
java -version
3)安装ZooKeeper
也可以参考我之前的文章:分布式开源协调服务——Zookeeper
1、下载解压
下载地址:https://zookeeper.apache.org/releases.html
cd /opt/bigdata/
wget https://dlcdn.apache.org/zookeeper/zookeeper-3.8.0/apache-zookeeper-3.8.0-bin.tar.gz --no-check-certificate
tar -xf apache-zookeeper-3.8.0-bin.tar.gz
2、配置环境变量
vi /etc/profile
export ZOOKEEPER_HOME=/opt/bigdata/apache-zookeeper-3.8.0-bin/
export PATH=$ZOOKEEPER_HOME/bin:$PATH
# 加载生效
source /etc/profile
3、配置
cd $ZOOKEEPER_HOME
cp conf/zoo_sample.cfg conf/zoo.cfg
mkdir $ZOOKEEPER_HOME/data
cat >conf/zoo.cfg<<EOF
# tickTime:Zookeeper 服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是每个 tickTime 时间就会发送一个心跳。tickTime以毫秒为单位。session最小有效时间为tickTime*2
tickTime=2000
# Zookeeper保存数据的目录,默认情况下,Zookeeper将写数据的日志文件也保存在这个目录里。不要使用/tmp目录
dataDir=/opt/bigdata/apache-zookeeper-3.8.0-bin/data
# 端口,默认就是2181
clientPort=2181
# 集群中的follower服务器(F)与leader服务器(L)之间初始连接时能容忍的最多心跳数(tickTime的数量),超过此数量没有回复会断开链接
initLimit=10
# 集群中的follower服务器与leader服务器之间请求和应答之间能容忍的最多心跳数(tickTime的数量)
syncLimit=5
# 最大客户端链接数量,0不限制,默认是0
maxClientCnxns=60
# zookeeper集群配置项,server.1,server.2,server.3是zk集群节点;hadoop-node1,hadoop-node2,hadoop-node3是主机名称;2888是主从通信端口;3888用来选举leader
server.1=local-168-182-110:2888:3888
server.2=local-168-182-111:2888:3888
server.3=local-168-182-112:2888:3888
EOF
4、配置myid
echo 1 > $ZOOKEEPER_HOME/data/myid
5、将配置推送到其它节点
scp -r $ZOOKEEPER_HOME local-168-182-111:/opt/bigdata/
scp -r $ZOOKEEPER_HOME local-168-182-112:/opt/bigdata/
# 也需要添加环境变量和修改myid,local-168-182-111的myid设置2,local-168-182-112的myid设置3
6、启动服务
cd $ZOOKEEPER_HOME
# 启动
./bin/zkServer.sh start
# 查看状态
./bin/zkServer.sh status
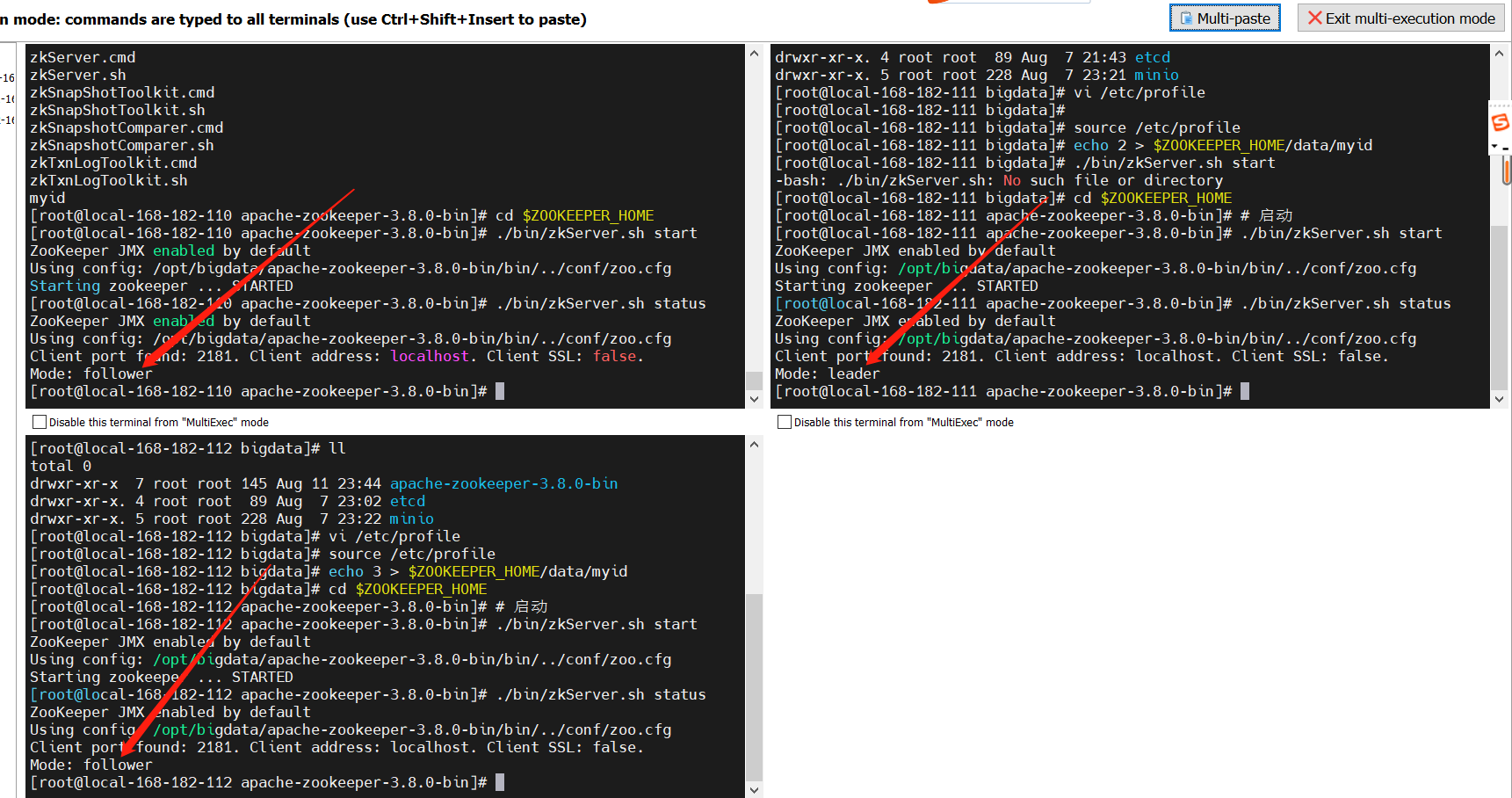
4)安装Hadoop
也可以参考我之前的文章:大数据Hadoop原理介绍+安装+实战操作(HDFS+YARN+MapReduce)
1、下载解压
下载地址:https://dlcdn.apache.org/hadoop/common/
mkdir -p /opt/bigdata/hadoop && cd /opt/bigdata/hadoop
wget https://dlcdn.apache.org/hadoop/common/hadoop-3.3.4/hadoop-3.3.4.tar.gz --no-check-certificate
# 解压
tar -zvxf hadoop-3.3.4.tar.gz
2、修改配置文件
配置环境变量
vi /etc/profile
export HADOOP_HOME=/opt/bigdata/hadoop/hadoop-3.3.4
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
# 加载生效
source /etc/profile
- 修改
$HADOOP_HOME/etc/hadoop/hadoop-env.sh
# 在hadoop-env.sh文件末尾追加
export JAVA_HOME=/opt/jdk1.8.0_212
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
- 修改
$HADOOP_HOME/etc/hadoop/core-site.xml#核心模块配置
# 创建存储目录
mkdir -p /opt/bigdata/hadoop/data/hadoop-3.3.4
<!-- 在<configuration></configuration>中间添加如下内容 -->
<!-- 设置默认使用的文件系统 Hadoop支持file、HDFS、GFS、ali|Amazon云等文件系统 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://local-168-182-110:8082</value>
</property>
<!-- 设置Hadoop本地保存数据路径 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/bigdata/hadoop/data/hadoop-3.3.4</value>
</property>
<!-- 设置HDFS web UI用户身份 -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
<!-- 聚合hive 用户代理设置 -->
<property>
<name>hadoop.proxyuser.hosts</name>
<value>*</value>
</property>
<!-- 用户代理设置 -->
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
<!-- 文件系统垃圾桶保存时间 -->
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
- 修改
$HADOOP_HOME/etc/hadoop/hdfs-site.xml#hdfs文件系统模块配置
<!-- 在<configuration></configuration>中间添加如下内容 -->
<!-- 设置SNN进程运行机器位置信息 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>local-168-182-111:9868</value>
</property>
<!-- 必须将dfs.webhdfs.enabled属性设置为true,否则就不能使用webhdfs的LISTSTATUS、LISTFILESTATUS等需要列出文件、文件夹状态的命令,因为这些信息都是由namenode来保存的。 -->
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<!-- nameservice的逻辑名称。可以为任意可读字符串;如果在Federation中使用,那么还应该包含其他的nameservices,以","分割。 -->
<property>
<name>dfs.nameservices</name>
<value>ns1</value>
</property>
- 修改
$HADOOP_HOME/etc/hadoop/mapred.xml#MapReduce模块配置
<!-- 设置MR程序默认运行模式,yarn集群模式,local本地模式 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- MR程序历史服务地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>local-168-182-110:10020</value>
</property>
<!-- MR程序历史服务web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>local-168-182-110:19888</value>
</property>
<!-- yarn环境变量 -->
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<!-- map环境变量 -->
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<!-- reduce环境变量 -->
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
- 修改
$HADOOP_HOME/etc/hadoop/yarn-site.xml#yarn模块配置
<!-- 在<configuration></configuration>中间添加如下内容 -->
<!-- 设置YARN集群主角色运行集群位置 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>local-168-182-110</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 是否将对容器实施物理内存限制 -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!-- 是否将对容器实施虚拟内存限制 -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<!-- 开启日志聚集 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置yarn历史服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://local-168-182-110:19888/jobhistory/logs</value>
</property>
<!-- 设置yarn历史日志保存时间 7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604880</value>
</property>
修改$HADOOP_HOME/etc/hadoop/workers
将下面内容覆盖文件,默认只有localhost
local-168-182-110
local-168-182-111
local-168-182-112
3、分发同步hadoop安装包到另外几台机器
scp -r $HADOOP_HOME local-168-182-111:/opt/bigdata/hadoop/
scp -r $HADOOP_HOME local-168-182-112:/opt/bigdata/hadoop/
# 注意也需要设置环境变量
vi /etc/profile
export HADOOP_HOME=/opt/bigdata/hadoop/hadoop-3.3.4
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
# 加载
source /etc/profile
4、Hadoop集群启停(local-168-182-110上执行)
1)(首次启动)格式化namenode(只能执行一次)
- 首次启动HDFS时,必须对其进行格式化操作
- format本质上初始化工作,进行HDFS清理和准备工作
hdfs namenode -format
2)手动逐个进程启停
# HDFS集群启动
hdfs --daemon [start|stop] [namenode|datanode|secondarynamenode]
# YARN集群启动
yarn --daemon [start|stop] [resourcemanager|nodemanager]
3)通过shell脚本一键启停(推荐)
在local-168-182-110上,使用软件自带的shell脚本一键启动。前提:配置好机器之间的SSH免密登录和works文件
start-dfs.sh
stop-dfs.sh #这里不执行
# YARN集群启停
start-yarn.sh
stop-yarn.sh # 这里不执行
# Hadoop集群启停(HDFS+YARN)
start-all.sh
stop-all.sh # 这里不执行
# 查看
jps
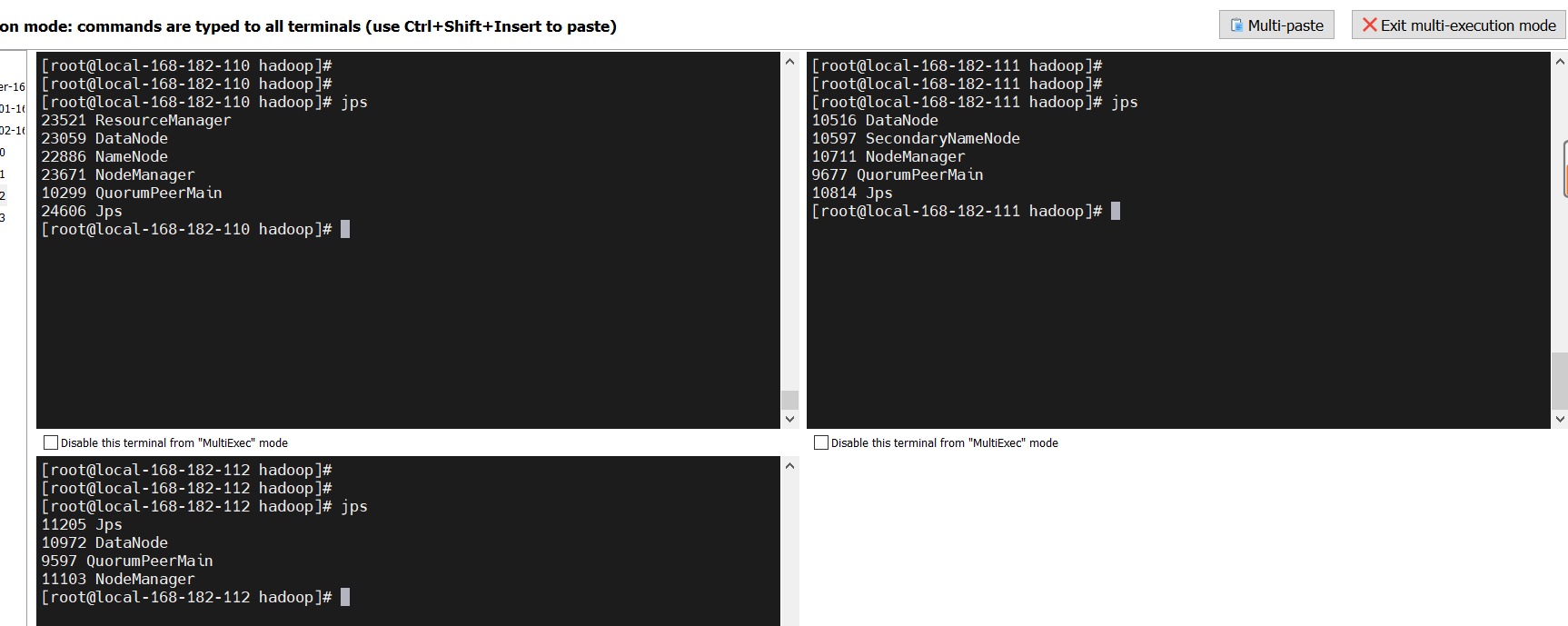
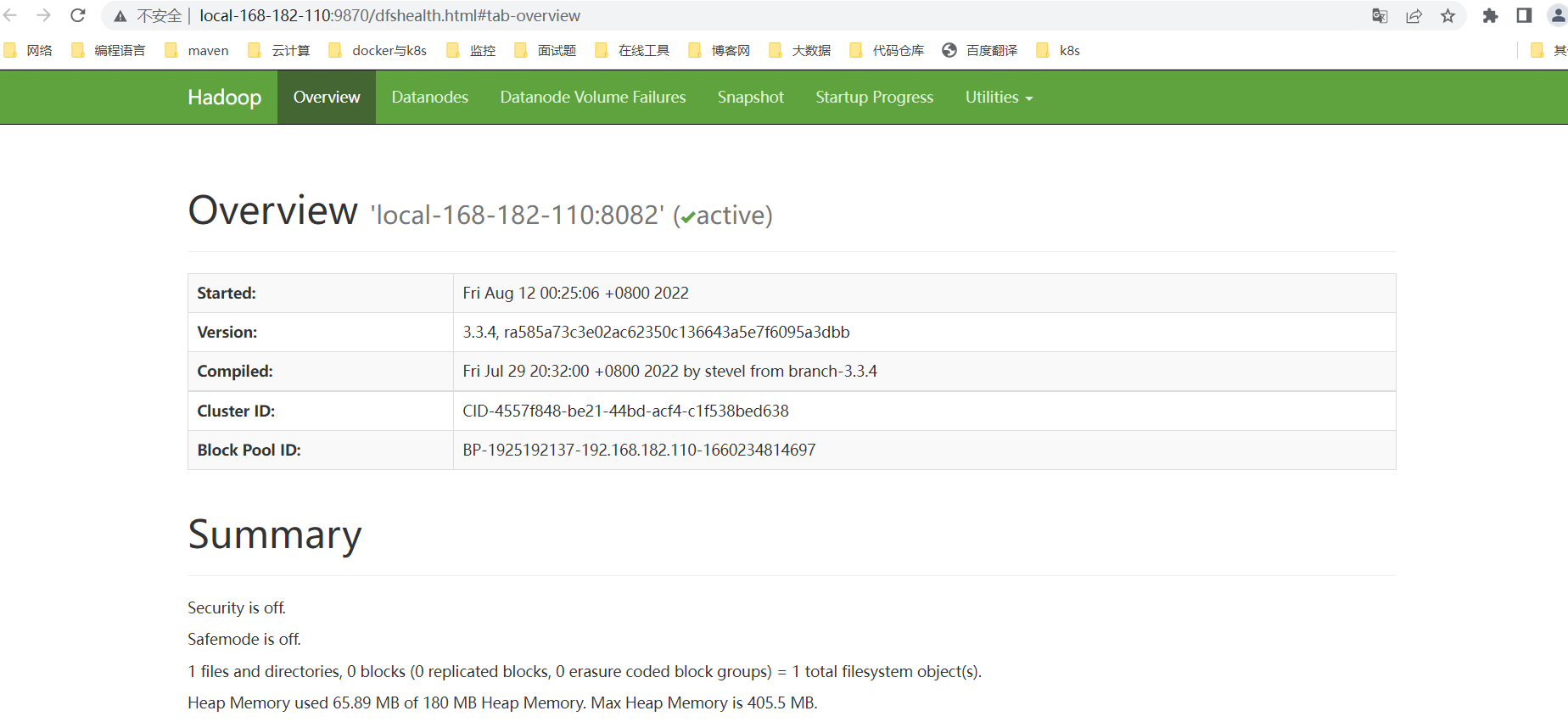
HDFS集群访问:http://local-168-182-110:9870
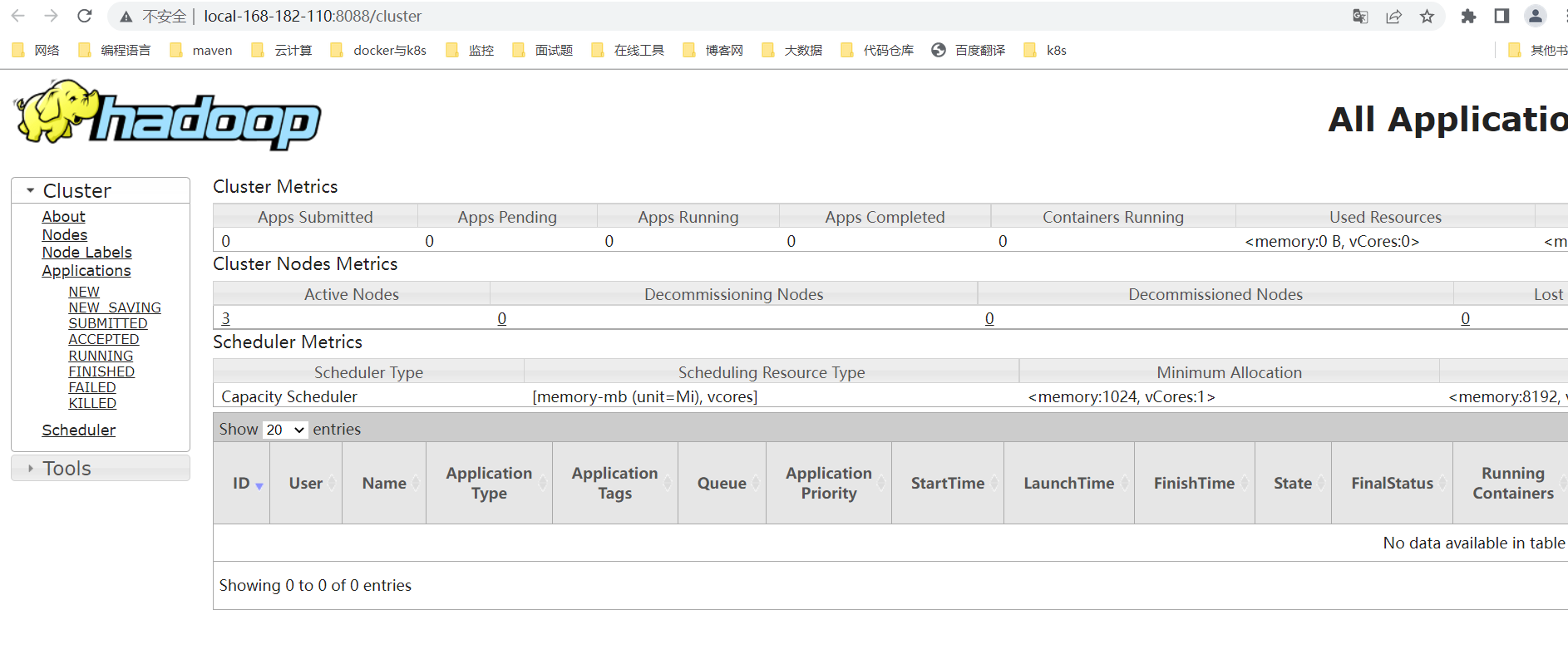
YARN集群访问:http://local-168-182-110:8088
5)部署HBase
1、下载解压
下载地址:http://hbase.apache.org/downloads.html
cd /opt/bigdata
wget https://dlcdn.apache.org/hbase/2.4.13/hbase-2.4.13-bin.tar.gz --no-check-certificate
# 解压
tar -xf hbase-2.4.13-bin.tar.gz
# 配置环境变量
vi /etc/profile
export HBASE_HOME=/opt/bigdata/hbase-2.4.13
export PATH=$HBASE_HOME/bin:$PATH
source /etc/profile
2、配置HBase
- 配置
$HBASE_HOME/conf/hbase-env.sh,添加或修改以下内容:
export JAVA_HOME=/opt/jdk1.8.0_212
export HBASE_CLASSPATH=/opt/bigdata/hbase-2.4.13/conf
export HBASE_MANAGES_ZK=false
- 配置
$HBASE_HOME/conf/hbase-site.xml
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://local-168-182-110:8082/hbase</value>
<!-- hdfs://ns1/hbase 对应hdfs-site.xml的dfs.nameservices属性值 -->
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>local-168-182-110,local-168-182-111,local-168-182-112</value>
</property>
<property>
<name>hbase.zookeeper.property.clientPort</name>
<value>2181</value>
</property>
<property>
<name>hbase.master</name>
<value>60000</value>
<description>单机版需要配主机名/IP和端口,HA方式只需要配端口</description>
</property>
<property>
<name>hbase.master.info.bindAddress</name>
<value>0.0.0.0</value>
</property>
<property>
<name>hbase.master.port</name>
<value>16000</value>
</property>
<property>
<name>hbase.master.info.port</name>
<value>16010</value>
</property>
<property>
<name>hbase.regionserver.port</name>
<value>16020</value>
</property>
<property>
<name>hbase.regionserver.info.port</name>
<value>16030</value>
</property>
<property>
<name>hbase.wal.provider</name>
<value>filesystem</value> <!--也可以用multiwal-->
</property>
</configuration>
hbase-site.xml参数说明:
1. hbase.rootdir:这个目录是 RegionServer 的共享目录,用来持久化 HBase。特别注意的是 hbase.rootdir 里面的 HDFS 地址是要跟 Hadoop 的 core-site.xml 里面的 fs.defaultFS 的 HDFS 的 IP 地址或者域名、端口必须一致。(HA环境下,dfs.nameservices 是由zookeeper来决定的)。
2. hbase.cluster.distributed:HBase 的运行模式。为 false 表示单机模式,为 true 表示分布式模式。若为 false,HBase 和 ZooKeeper 会运行在同一个 JVM 中。
3. hbase.master:如果只设置单个 Hmaster,那么 hbase.master 属性参数需要设置为 master:60000 (主机名:60000);如果要设置多个 Hmaster,那么我们只需要提供端口 60000,因为选择真正的 master 的事情会有 zookeeper 去处理。
4. hbase.tmp.dir:本地文件系统的临时文件夹。可以修改到一个更为持久的目录上(/tmp会在重启时清除)。
5. hbase.zookeeper.quorum:对于 ZooKeeper 的配置。至少要在 hbase.zookeeper.quorum 参数中列出全部的 ZooKeeper 的主机,用逗号隔开。该属性值的默认值为 localhost,这个值显然不能用于分布式应用中。
6. hbase.zookeeper.property.dataDir:这个参数用户设置 ZooKeeper 快照的存储位置,默认值为 /tmp,显然在重启的时候会清空。因为笔者的 ZooKeeper 是独立安装的,所以这里路径是指向了$ZOOKEEPER_HOME/conf/zoo.cfg 中 dataDir 所设定的位置。
7. hbase.zookeeper.property.clientPort:客户端连接 ZooKeeper 的端口。默认是2181。
8. zookeeper.session.timeout:ZooKeeper 会话超时。Hbase 把这个值传递改 zk 集群,向它推荐一个会话的最大超时时间。
9. hbase.regionserver.restart.on.zk.expire:当 regionserver 遇到 ZooKeeper session expired, regionserver 将选择 restart 而不是 abort。
- 配置
$HBASE_HOME/conf/regionservers
local-168-182-110
local-168-182-111
local-168-182-112
- 复制Hadoop的关键配置文件到conf目录
cp $HADOOP_HOME/etc/hadoop/core-site.xml $HADOOP_HOME/etc/hadoop/hdfs-site.xml $HBASE_HOME/conf/
3、复制配置好的包到其它节点
scp -r $HBASE_HOME local-168-182-111:/opt/bigdata/
scp -r $HBASE_HOME local-168-182-112:/opt/bigdata/
# 注意在其它节点也配置环境变量
# 配置环境变量
vi /etc/profile
export HBASE_HOME=/opt/bigdata/hbase-2.4.13
export PATH=$HBASE_HOME/bin:$PATH
source /etc/profile
4、启动和停止HBase
【温馨提示】在其中一台启动即可,启动其它节点得hbase服务,跟hadoop启动类似
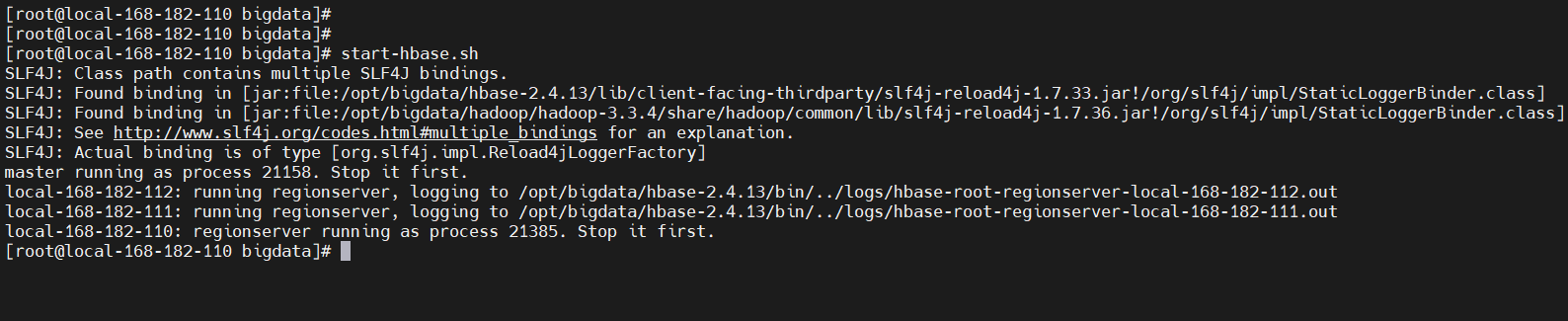
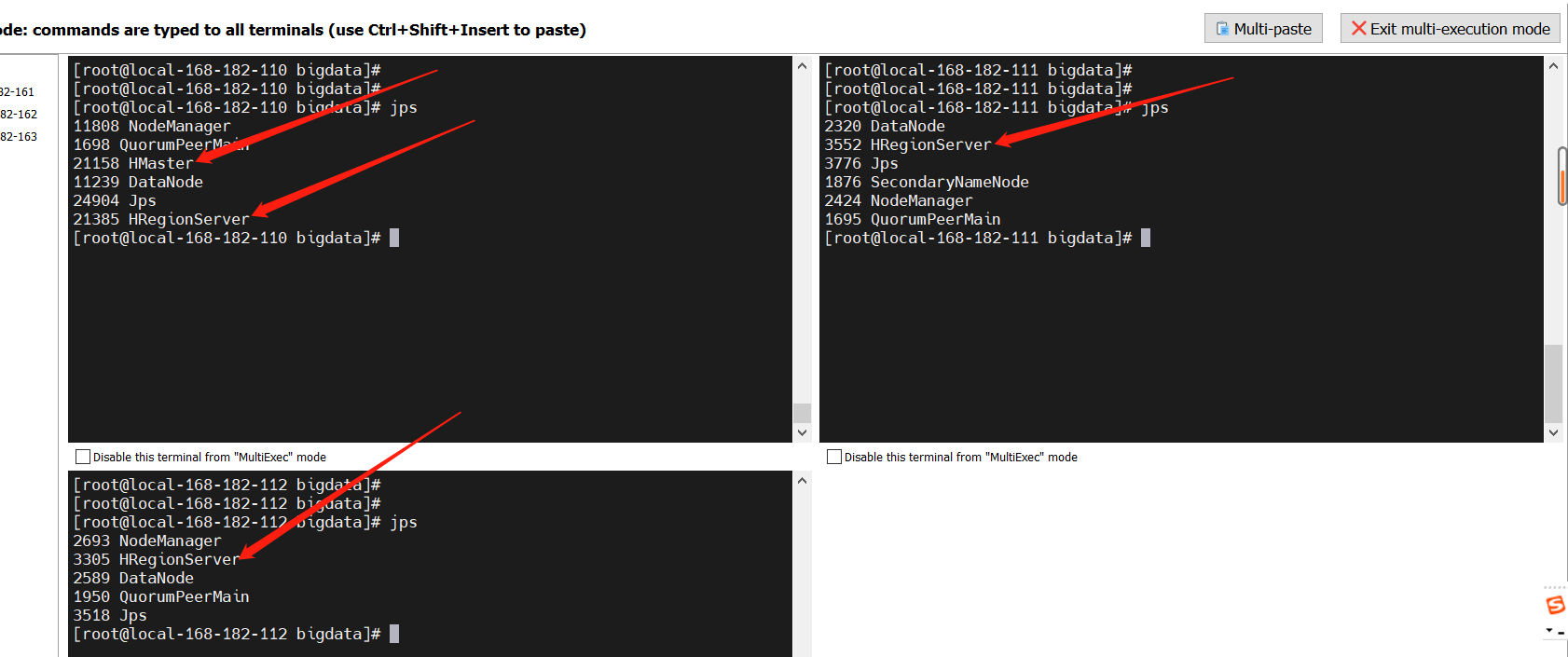
start-hbase.sh
stop-hbase.sh
5、测试
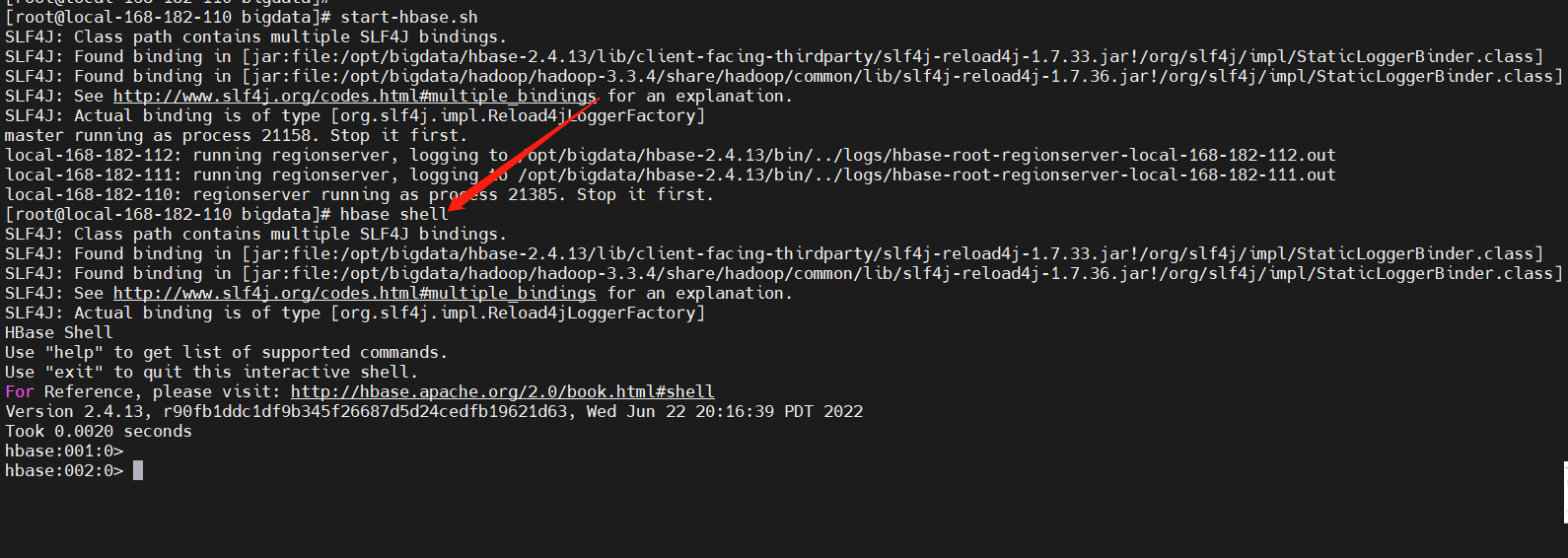
命令测试
#登入HBase(跟MySQL类似)
hbase shell
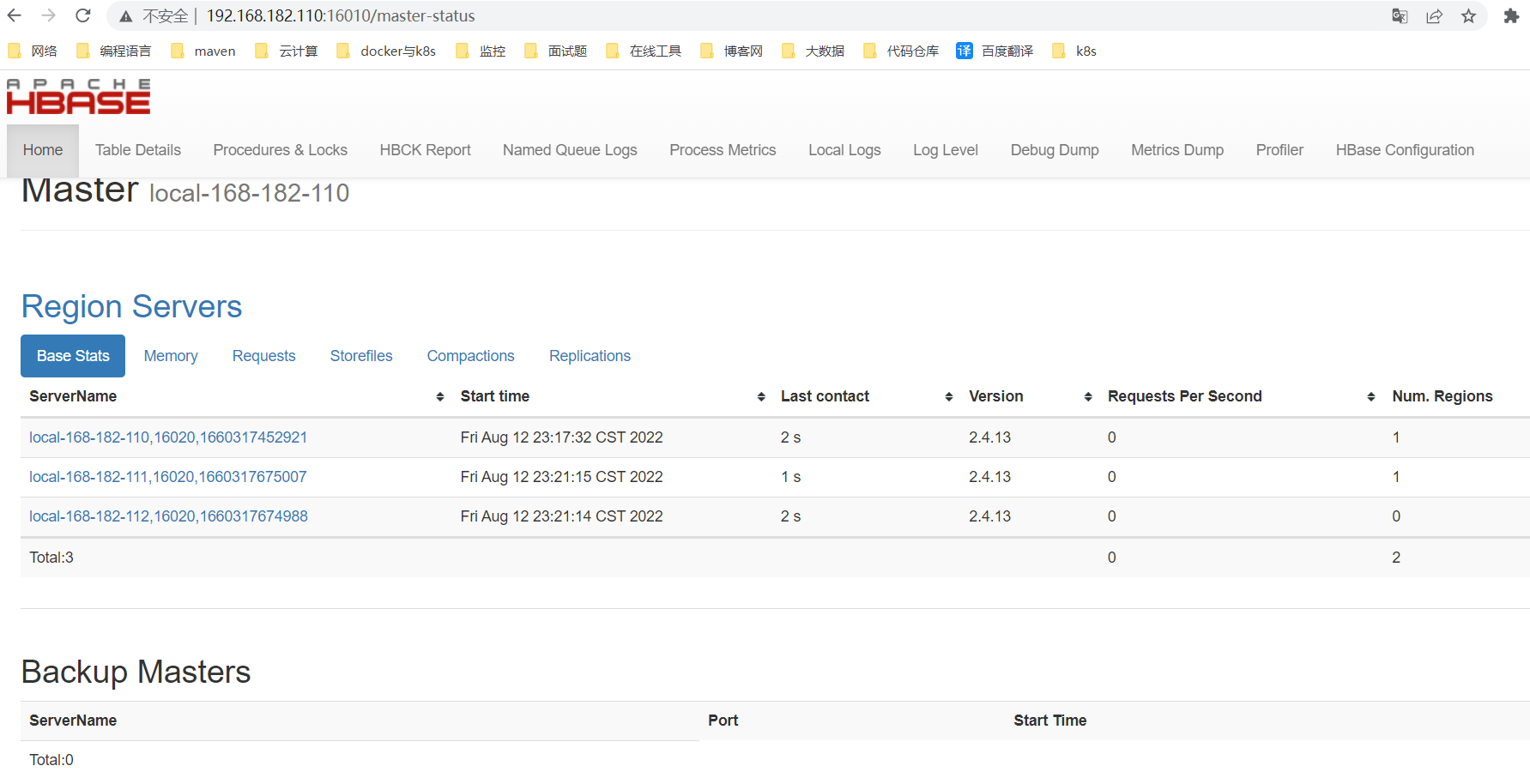
web访问:http://local-168-182-110:16010/
环境部署就到这里了,有任何疑问欢迎给我留言哦~
六、HBase与其它数据库对比
1)HBase与传统数据库对比
| 对比项 | Hbase | 传统数据库 |
|---|---|---|
| 数据类型 | Hbase只有简单的数据类型,只保留字符串 | 传统数据库有丰富的数据类型 |
| 数据操作 | Hbase只有简单的插入、查询、删除、清空等操作,表和表之间是分离的,没有复杂的表和表之间的关系 | 传统数据库通常有各式各样的函数和连接操作 |
| 存储模式 | Hbase是基于列存储的,每个列族都由几个文件保存,不同列族的文件是分离的,这样的好处是数据即是索引,访问查询涉及的列大量降低系统的I/O,并且每一列由一个线索来处理,可以实现查询的并发处理 | 传统数据库是基于表格结构和行存储,其没有建立索引将耗费大量的I/O并且建立索引和物化试图需要耗费大量的时间和资源 |
| 数据维护 | Hbase的更新实际上是插入了新的数据 | 传统数据库只是替换和修改 |
| 可伸缩性 | Hbase可以轻松的增加或减少硬件的数目,并且对错误的兼容性比较高 | 传统数据库需要增加中间层才能实现这样的功能 |
| 事务 | Hbase只可以实现单行的事务性,意味着行与行之间、表与表之前不必满足事务性 | 传统数据库是可以实现跨行的事务性 |
2)HBase与ClickHouse对比
| 对比项 | Hbase | Clickhouse |
|---|---|---|
| 数据存储 | Zookeeper保存元数据,数据写入HDFS(非结构化数据) | Zookeeper保存元数据,数据存储在本地,且会压缩 |
| 查询 | 不支持标准sql,需要集成Phoenix插件。Hbase自身有Scan操作,但是不建议执行,一般会全量扫描导致集群崩溃 | 支持sql,拥有高效的查询能力 |
| 数据读写 | 支持随机读写,删除。更新操作是插入一条新timestamp的数据 | 支持读写,但不能删除和更新 |
| 维护 | 需要同时维护HDFS、Zookeeper和Hbase(甚至于Phoenix) | 额外维护Zookeeper |
Hbase更适合非结构化的数据存储,ClickHouse拥有高效的查询能力。
关于HBase的介绍和环境部署就先到这里了,后面会分享HBase的实战操作,请小伙伴耐心等待,有疑问的小伙伴欢迎给我留言哦~
















 752
752











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









