









1.首先将数据库写入配置文件
# .bashrc
source /usr/local/greenplum-db/greenplum_path.sh
export MASTER_DATA_DIRECTORY=/data/master/gpseg-1
export PGDATABASE=xx //写入数据库如 export PGDATABASE=xx,数据库的名字一定是小写
// \l 为查看数据库个数
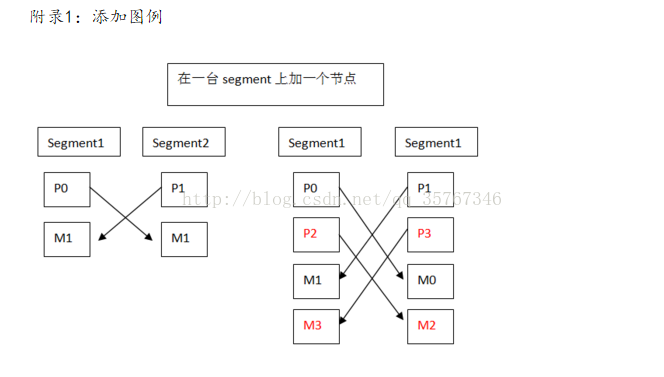
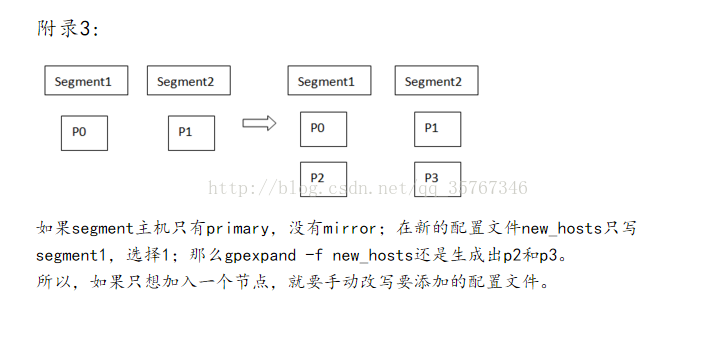
2.新建一个文件写入要添加节点的主机信息
segment1
segment2
3.执行扩容命令gpexpand -f /gp/new_hosts
(如果没有指定数据库到配置文件
gpexpand -f /gp/new_hosts -D xx如此使用-D加入数据库
)
Would you like to initiate a new System Expansion Yy|Nn (default=N):
你想开始一个新的系统扩展?
>
y
What type of mirroring strategy would you like?
你使用什么类型的镜像策略?
spread|grouped (default=grouped):
散布
|
分组
>
spread
How many new primary segments per host do you want to add? (default=0):
你想添加多少新的节点每台?
>
1
Enter new primary data directory 1:
新加primary节点的地址路径
>
/data/primary
Enter new mirror data directory 1:
新加mirror节点
的地址路
径
>
/data/mirror
Input configuration files were written to '
gpexpand_inputfile_20160727_105950' and 'None'.
4.查看新加节点的分布信息
[
gpadmin@master ~]$
cat gpexpand_inputfile_20160727_105950
segment1:segment1:40001:/data/primary/gpseg2:7:2:p:41001
segment2:segment2:50001:/data/mirror/gpseg2:10:2:m:51001
segment2:segment2:40001:/data/primary/gpseg3:8:3:p:41001
segment1:segment1:50001:/data/mirror/gpseg3:9:3:m:51001
5.执行 gpexpand -i gpexpand_inputfile_20160727_105950
(如果没有指定数据库到配置文件
gpexpand -i gpexpand_inputfile_20160727_105950 -D xx如此使用-D加入数据库
)
[
gpadmin@master ~]$
gpexpand -i gpexpand_inputfile_20160727_105950
20160727:11:05:23:003960 gpexpand:master:gpadmin-[INFO]:-rerun gpexpand
20160727:11:05:23:003960 gpexpand:master:gpadmin-[INFO]:-*************
20160727:11:05:23:003960 gpexpand:master:gpadmin-[INFO]:-Exiting...
6.开始进行表重分布(60h是执行周期)
7.查看当前节点配置信息再按相关信息缩写(进入以下查看,确保全部up)
xx=# SELECT * from gp_segment_configuration ;
dbid | content | role | preferred_role | mode | status | port | hostname | address | replication_port | san_mounts
------+---------+------+----------------+------+--------+-------+----------+----------+------------------+------------
1 | -1 | p | p | s | u | 5432 | master | master | |
2 | 0 | p | p | s | u | 40000 | segment1 | segment1 | 41000 |
3 | 1 | p | p | s | u | 40000 | segment2 | segment2 | 41000 |
4 | 0 | m | m | s | u | 50000 | segment2 | segment2 | 51000 |
5 | 1 | m | m | s | u | 50000 | segment1 | segment1 | 51000 |
6 | -1 | m | m | s | u | 5432 | standby | standby | |
7 | 2 | p | p | s | u | 40001 | segment1 | segment1 | 41001 |
10 | 2 | m | m | s | u | 50001 | segment2 | segment2 | 51001 |
8 | 3 | p | p | s | u | 40001 | segment2 | segment2 | 41001 |
9 | 3 | m | m | s | u | 50001 | segment1 | segment1 | 51001 |
8.随机查看一个表的分布情况
xx=#
select gp_segment_id,count(*) from 表名 group by 1;
9.在gpexpand -i 的时候,多了个gpexpand的schema
[gpadmin@master ~]$ gpexpand -c --移除gpexpand schema
Do you want to dump thegpexpand.status_detail table to file? Yy|Nn (default=Y):
> y 你想把gpexpand.status_detail表文件卸下?
10.有可能在gpstop的时候有下面错误:
Unable to clean shared memory (can't start new thread)//
无法清理共享内存(无法启动新线程)
重启master和所有segment即可。















 247
247

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









