









 本文介绍了遥感影像分类后的精度评价方法,包括混淆矩阵、总体精度、Kappa系数、生产者精度和用户精度等关键指标。通过使用geemap库进行监督分类的精度验证,详细阐述了如何利用confusionMatrix()、accuracy()、kappa()等函数计算这些指标,以评估分类器的性能。
本文介绍了遥感影像分类后的精度评价方法,包括混淆矩阵、总体精度、Kappa系数、生产者精度和用户精度等关键指标。通过使用geemap库进行监督分类的精度验证,详细阐述了如何利用confusionMatrix()、accuracy()、kappa()等函数计算这些指标,以评估分类器的性能。
前言
要评估分类器的准确性,可以使用ConfusionMatrix。**sample()方法从输入数据生成两个随机样本:一个用于训练,另一个用于验证。训练样本用于训练分类器。从classifier.confusionMatrix()**中可以得到训练数据的替换精度。为了获得验证的准确性,需要对验证数据进行分类。这将向验证FeatureCollection添加一个分类属性。在分类的FeatureCollection上调用errorMatrix(),以获得表示验证(预期)准确性的混淆矩阵。
一、分类精度评价
遥感影像分类之后需要进行分类精度评价,精度评价方法中最常见的就是混淆矩阵和kappa系数。现把指标列举如下:
① 混淆矩阵(confusion matrix)
用于表示分为某一类别的像元个数与地面检验为该类别数的比较阵列。通常,阵列中的列代表参考数据,行代表由遥感数据分类得到的类别数据。有像元数和百分比表示两种。
② 总体分类精度(Overall Accuracy)
被正确分类的像元总和除以总像元数。被正确分类的像元数目沿着混淆矩阵的对角线分布,总像元数等于所有真实参考源的像元总数
③ Kappa系数(Kappa Coefficient)
通过把所有真实参考的像元总数(N)乘以混淆矩阵对角线(XKK)的和,再减去各类中真实参考像元数与该类中被分类像元总数之积之后,再除以像元总数的平方减去各类中真实参考像元总数与该类中被分类像元总数之积对所有类别求和的结果。
④ 错分误差(Commission Error)
被分为用户感兴趣的类,而实际上属于另一类的像元,错分误差显示在混淆矩阵的行里面。
⑤ 漏分误差(Omission Error)
本属于地表真实分类,但没有被分类器分到相应类别中的像元数。漏分误差显示在混淆矩阵的列里。
⑥ 制图精度(Producer’s Accuracy)
制图精度或生产者精度是指分类器将整个影像的像元正确分为A类的像元数(对角线值)与A类真实参考总数(混淆矩阵中A类列的总和)的比率。
⑦ 用户精度(User’s Accuracy)
正确分到A类的像元总数(对角线值)与分类器将整个影像的像元分为A类的像元总数(混淆矩阵中A类行的总和)比率。
二、监督分类结果的精度验证
监督分类的过程详见上一期内容:geemap学习笔记 07 geemap 监督分类案例,此处详细介绍分类结果的精度验证情况。
1. 混淆矩阵
训练数据集confusionMatrix()根据分类器的训练数据计算二维混淆矩阵。
train_accuracy = classifier.confusionMatrix()
# 混淆矩阵展示
train_accuracy.getInfo()

2. 总体精度
总体精度:在所有参考点中有多少比例是正确的。总体准确率通常用百分数表示,100%的准确率表示所有参考位点都正确分类的完美分类。
train_accuracy.accuracy().getInfo()
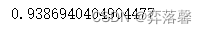
3. Kappa 系数
Kappa系数:是由统计测试产生的,用于评估分类的准确性。Kappa基本上是评估分类的表现与随机分配的值相比,也就是分类是否比随机更好。Kappa系数的范围从-1到0 1。值为0表示分类并不比随机分类好。负数表示该分类明显比随机分类差。接近1的值表示该分类明显优于随机分类。
train_accuracy.kappa().getInfo()

4. 生产者精度
生产者精度:地图制作精度是从地图制作者(地图制作者)的角度来看的地图精度。这是在分类地图上正确显示地面真实特征的频率,或地面上某一区域的某一土地覆盖被分类的概率。制作人的准确性是遗漏错误的补充,制作人的准确性= 100%-遗漏错误。
train_accuracy.producersAccuracy().getInfo()

5. 用户精度
用户精度:是从地图制作者(地图制作者)的角度来看的地图精度。这是在分类地图上正确显示地面真实特征的频率,或地面上某一区域的某一土地覆盖被分类的概率。制作人的准确性是遗漏错误的补充,用户精度= 100%-遗漏错误。
train_accuracy.producersAccuracy().getInfo()

总结
以上就是今天要讲的内容,这里仅是简单介绍了一下在geemap中监督分类的精度验证结果,后续会继续更新其他具体案例~



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









