









一、背景
测试需求->流式计算->json嵌套类型数据,流式计算的流程是基于,将配置的任务,转化为flink sql,然后提交到集群上,执行计算任务的过程,所以,除基本功能测试以外,需要考虑,我们提交的json嵌套类型数据,解析后,解析成什么类型才符合flink sql的语法,才可以正常执行,所以简单进行调研总结下flink sql 解析json嵌套数据。
二、思考过程
1、流式计算的业务处理过程:将kafka输入源的数据,存储为flink虚拟表a的数据,将a的数据全部select出,insert到kafka输出源(将kafka topic 抽象成 flink table),所以基于「测试」的角度需要了解flink sql,对于不同数据类型,如:array、row等数据格式,在建表DDL中应该如何定义?SQL如何解析?不同json嵌套类型的数据经过流式计算平台json解析后的结果应该是如何的?
三、调研结果
json嵌套的样例数据
{
"funcName":"test",
"data":{
"snapshots":[
{
"content_type":"application/x-gzip-compressed-jpeg",
"url":"https://blog.csdn.net/"
}
],
"audio":[
{
"content_type":"audio/wav",
"url":"https://blog.csdn.net/"
}
]
},
"type":2,
"timestamp":1610549997263,
"arr":[
{
"address":"北京市海淀区",
"city":"beijing"
},
{
"address":"北京市海淀区",
"city":"beijing"
},
{
"address":"北京市海淀区",
"city":"beijing"
}
]
}
解析后的数据类型
funcName: STRING
data: ROW<snapshots ARRAY<ROW<content_type STRING,url STRING>>,audio ARRAY<ROW<content_type STRING,url STRING>>>
type:INT
timestamp:BIGIN
arr: ARRAY<ROW<address STRING,city STRING>
目前基于流式计算java开发,对json嵌套数据进行解析后的结果:
"data":{
"data.XX.XX":{
"parent": "data",
"name": "data.XX.XX",
"type": "STRING"
}
}
定义DDL建表语句语法举例:
CREATE TABLE kafka_source (
funcName STRING,
data ROW<snapshots ARRAY<ROW<content_type STRING,url STRING>>,audio ARRAY<ROW<content_type STRING,url STRING>>>,
`type` INT,
`timestamp` BIGINT,
arr ARRAY<ROW<address STRING,city STRING>>,
proctime as PROCTIME()
) WITH (
'connector' = 'kafka', -- 使用 kafka connector
'topic' = 'test', -- kafka topic
'properties.bootstrap.servers' = 'master:9092,storm1:9092,storm2:9092', -- broker连接信息
'properties.group.id' = 'jason_flink_test', -- 消费kafka的group_id
'scan.startup.mode' = 'latest-offset', -- 读取数据的位置
'format' = 'json', -- 数据源格式为 json
'json.fail-on-missing-field' = 'true', -- 字段丢失任务不失败
'json.ignore-parse-errors' = 'false' -- 解析失败跳过
)
解析SQL语句相关举例:
select kafka_source.'funcName' as 'funcName', count(kafka_source.'data.snapshots[1].url') as 'data.snapshots[1].url_count'
from kafka_source
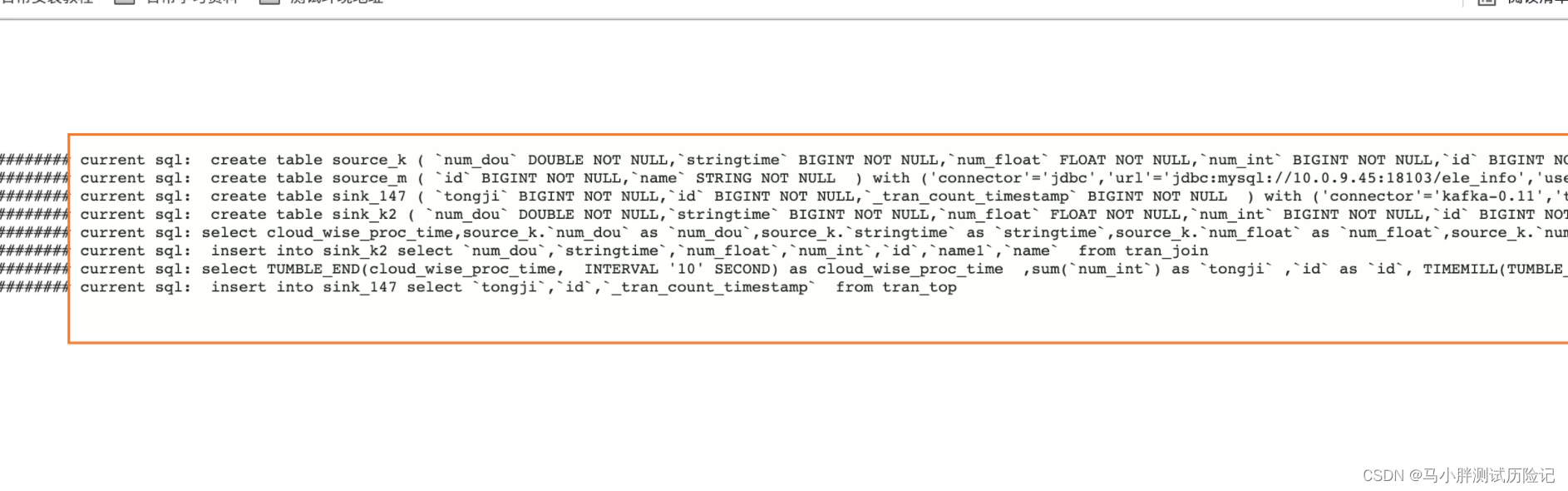
四、实际应用于-流式计算测试过程
1、在流式计算,页面新建 json嵌套类型数据的计算任务,并正确启动
2、进入 hadoop on yarn 环境查看 该任务运行日志

点击查看详情,并点击Logs


最终可查看,将kafka topic 抽象成 flink table的sql的建表语句,以及最终提交的flink sql ->计算任务,可按照相关的语法,对执行的sql进行一个测试检查。















 6718
6718











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









