










跟部署有关的几个名词先介绍一下:
| node | 节点是一个es实例,一台机器可以运行多个实例,但是同一台机器上的实例在配置文件中要确保http和tcp端口不同;一般一个机器只部署一个 |
| cluster | 代表一个集群,集群中有多个节点,其中有一个会被选为主节点,这个主节点是可以通过选举产生的,主从节点是对于集群内部来说的。一般较大的集群中,一个节点不同时作为主节点和数据节点 |
| shards | 因为ES是个分布式的搜索引擎, 所以索引通常都会分解成不同部分, 而这些分布在不同节点的数据就是分片. ES自动管理和组织分片, 并在必要的时候对分片数据进行再平衡分配, 所以用户基本上不用担心分片的处理细节.分片会造成冗余,但是提高了可用性 |
| replicas | ES默认为一个索引创建5个主分片, 并分别为其创建一个副本分片. 也就是说每个索引都由5个主分片成本, 而每个主分片都相应的有一个copy. |
我们来看一个es集群的部署结构:
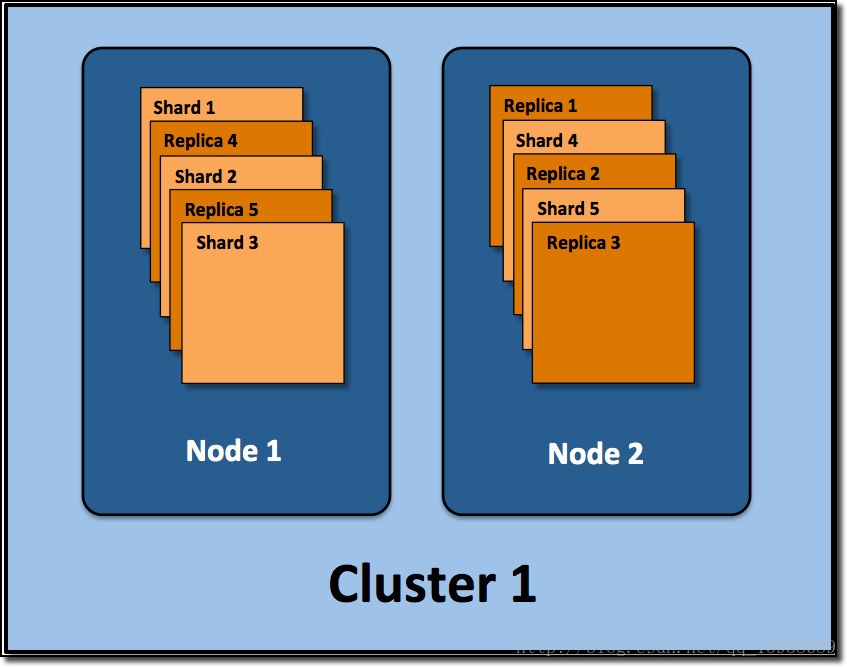
es-head插件查看es系统概览_u013761206的专栏-CSDN博客
根数据更像个的,有几个名词,有参照比较好理解,选择mysql的结构来进行对比:
| Elasticsearch | MySQL | ||
|---|---|---|---|
| 索引库(indices) | Database 数据库 |
| |
| 类型(type) | Table 数据表 |
| |
| 文档(Document) | Row 行 |
| |
| 域字段(Field) | Columns 列 |
| |
| 映射配置(mappings) | 每个列的约束(类型、长度) | 字段的数据类型、属性、是否索引、是否存储等特性 |
一:下载安装es
参考:elasticsearch 6.8安装 - 柴米油盐酱醋 - 博客园
值得注意的是mater和node的比例是比较重要的:
- ES集群节点可以划分为三种:主节点、数据节点和客户端节点。
在生产环境下,如果不修改elasticsearch节点的角色信息,在高数据量,高并发的场景下集群容易出现脑裂等问题。默认情况下,elasticsearch 集群中每个节点都有成为主节点的资格,也都存储数据,还可以提供查询服务。这些功能是由两个属性控制的。
elasticsearch.yml:master - 主节点: node.master: true node.data: false 主要功能:维护元数据,管理集群节点状态;不负责数据写入和查询。 配置要点:内存可以相对小一些,但是机器一定要稳定,最好是独占的机器。 ------------------------------- data - 数据节点: node.master: false node.data: true 主要功能:负责数据的写入与查询,压力大。 配置要点:大内存,最好是独占的机器。 -------------------------------------------- client - 客户端节点: elasticsearch.yml : node.master: false node.data: false 主要功能:负责任务分发和结果汇聚,分担数据节点压力。 配置要点:大内存,最好是独占的机器 -------------------------------------------- mixed- 混合节点(不建议): node.master: true node.data: true 主要功能:综合上述三个节点的功能。 配置要点:大内存,最好是独占的机器。 特别说明:不建议这种配置,节点容易挂掉。
其他说明
- 虽然上面章节中,未对单个服务器的磁盘大小进行要求,但是整体ES集群的总磁盘大小要保证足够。
简单举例
假定共计20台机器,则可以按照如下配置:
| 节点类型 | 机器数量 | 内存大小 | 其他 |
|---|---|---|---|
| master | 3 | 16GB | 机器必须稳定 |
| data | 12 | 31GB | 无 |
| client | 5 | 31GB | 无 |
二、运行 & 关闭 elasticsearch
1.运行elasticsearch :
编辑 /elasticsearch-1.7.3/bin/elasticsearch.in.sh, 设置 ES_MIN_MEM和ES_MAX_MEM,确保二者数值一致,或者可以在启动es时指定
bin/elasticsearch
若想让es后台运行,则
bin/elasticsearch -d -Xms512m -Xmx512m
关闭elasticsearch:
前台运行:可以通过”CTRL+C”组合键来停止运行
后台运行,可以通过”kill -9 进程号”停止.使用jps查看进程号
四、es调优
1、es禁用swap
禁止 swap,一旦允许内存与磁盘的交换,会引起致命的性能问题。可以通过在 elasticsearch.yml 中 bootstrap.memory_lock: true,以保持 JVM 锁定内存,保证 ES 的性能。
2、修改对当个进程占用内存的限制
修改/etc/security/limits.conf, 在limits.conf中添加如下内容
* soft memlock unlimited
* hard memlock unlimited3、对应增加虚拟内存
修改elasticsearch下config目录下的jvm.options参考:
-Xms4g //默认是1g
-Xmx4g //默认是1g













 2448
2448











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









