






文章目录
Kubernetes 调度器的调度流程和算法
Kubernetes 调度器(kube-scheduler)是负责将新创建的 Pod 分配到集群中适当节点上的核心组件。它通过一系列规则和算法,确保 Pod 能在合适的资源环境中高效运行。
调度器的调度流程
kube-scheduler 的主要几大组件:
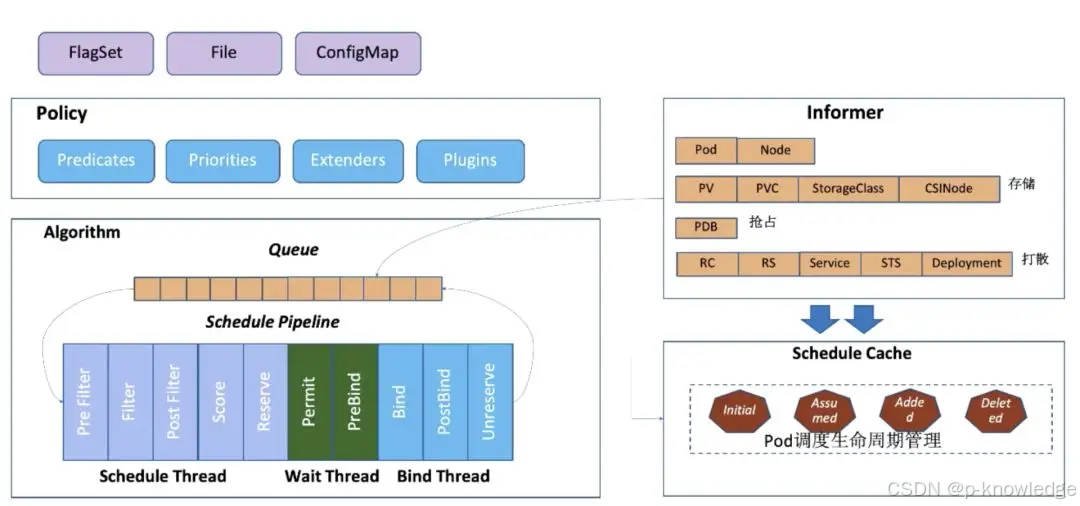
Policy
Scheduler 的调度策略启动配置目前支持三种方式,配置文件 / 命令行参数 / ConfigMap。调度策略可以配置指定调度主流程中要用哪些过滤器 (Predicates)、打分器 (Priorities) 、外部扩展的调度器 (Extenders),以及最新支持的 SchedulerFramwork 的自定义扩展点 (Plugins)。
Informer
Scheduler 在启动的时候通过 K8s 的 informer 机制以 List+Watch 从 kube-apiserver 获取调度需要的数据例如:Pods、Nodes、Persistant Volume(PV), Persistant Volume Specification(PVC) 等等,并将这些数据做一定的预处理作为调度器的的 Cache。
调度流水线
通过 Informer 将需要调度的 Pod 插入 Queue 中,Pipeline 会循环从 Queue Pop 等待调度的 Pod 放入 Pipeline 执行。
调度流水线 (Schedule Pipeline) 主要有三个阶段:Scheduler Thread,Wait Thread,Bind Thread。
- Scheduler Thread 阶段: 从如上的架构图可以看到 Schduler Thread 会经历 Pre Filter ->
Filter -> Post Filter-> Score -> Reserve,可以简单理解为 Filter -> Score ->
Reserve;
Filter 阶段用于选择符合 Pod Spec 描述的 Nodes;Score 阶段用于从 Filter 过后的 Nodes 进行打分和排序;Reserve 阶段将 Pod 跟排序后的最优 Node 的 NodeCache 中,表示这个 Pod 已经分配到这个 Node 上, 让下一个等待调度的 Pod 对这个 Node 进行 Filter 和 Score 的时候能看到刚才分配的 Pod。
- Wait Thread 阶段: 这个阶段可以用来等待 Pod 关联的资源的 Ready 等待,例如等待 PVC 的 PV 创建成功,或者
Gang 调度中等待关联的 Pod 调度成功等等; - Bind Thread 阶段: 用于将 Pod 和 Node 的关联持久化 Kube APIServer。
整个调度流水线只有在 Scheduler Thread 阶段是串行的一个 Pod 一个 Pod 的进行调度,在 Wait 和 Bind 阶段 Pod 都是异步并行执行。
-
调度请求:
- 当用户提交 Pod 定义(如 Deployment 或 Job),API Server 会将 Pod 的调度请求存储到
etcd中。 - 未被绑定到任何节点的 Pod 会进入调度队列,等待调度器处理。
- 当用户提交 Pod 定义(如 Deployment 或 Job),API Server 会将 Pod 的调度请求存储到
-
节点筛选(Filtering):
- 调度器根据 Pod 的要求(如资源需求、节点亲和性等)过滤出满足条件的候选节点。
- 节点预选阶段主要用来排除不符合要求的节点。
-
节点打分(Scoring):
- 对候选节点进行评分,分数越高,表示节点越适合运行该 Pod。
- 评分依据包括资源利用率、拓扑结构、数据本地性等因素。
-
绑定 Pod:
- 调度器选择分数最高的节点,并通过 API Server 将 Pod 与节点绑定。
kubelet在目标节点上接管 Pod 的创建和运行。
调度算法
1. 节点筛选算法(预选阶段)
用于过滤掉不符合要求的节点。常见的预选规则包括:
- 资源需求(Resource Fit):
- 确保节点有足够的 CPU、内存等资源满足 Pod 的
requests。
- 确保节点有足够的 CPU、内存等资源满足 Pod 的
- 污点和容忍(Taints and Tolerations):
- 排除与 Pod 不兼容的节点。
- 节点可用性:
- 节点必须处于 Ready 状态。
- 节点亲和性(Node Affinity):
- 确保 Pod 只调度到符合节点标签的节点。
- Pod 亲和性和反亲和性(Pod Affinity/Anti-affinity):
- 控制 Pod 与其他 Pod 的位置关系。
- 拓扑域分布(Topology Spread Constraints):
- 保证 Pod 分布在多个可用区域(如不同机架)。
2. 节点打分算法(优选阶段)
对候选节点进行评分,并选择分数最高的节点。常见的打分规则包括:
- Least Requested Priority:
- 优先选择资源利用率较低的节点。
- Balanced Resource Usage Priority:
- 优先选择资源利用率平衡的节点。
- Node Prefer Avoid Pods Priority:
- 避免选择用户标记为“优先不调度”的节点。
- Image Locality Priority:
- 优先选择已缓存 Pod 所需容器镜像的节点。
- Inter-Pod Affinity Priority:
- 优先选择与指定 Pod 更靠近的节点。
3. 绑定算法
最终,将 Pod 与打分最高的节点绑定。绑定操作通过 API Server 完成,确保分配结果存储到 etcd。
调度器的插件化架构
从 Kubernetes 1.19 开始,调度器采用了插件化框架(Scheduling Framework),用户可以自定义调度流程:
- 调度框架扩展点:
- 预选(Filter)
- 优选(Score)
- 预绑定(PreBind)
- 绑定(Bind)
- 后绑定(PostBind)
- 自定义插件:
- 用户可以编写插件以添加自定义调度逻辑。
调度器的调度策略
-
默认调度策略:
- 调度器内置一组预定义的规则,可满足大多数场景。
- 规则包含资源利用率优先、数据本地性、节点均衡等。
-
静态调度(Static Scheduling):
- 用户直接指定 Pod 运行的节点(
nodeName字段)。
- 用户直接指定 Pod 运行的节点(
-
自定义调度器:
- 用户可以开发自定义调度器,通过配置 Pod 的
schedulerName使用自定义逻辑。
- 用户可以开发自定义调度器,通过配置 Pod 的
调度器的性能优化
-
并行调度:
- 调度器支持多线程调度,提升处理高负载场景的能力。
-
优先级调度:
- 高优先级 Pod 可以抢占低优先级 Pod 的资源。
-
资源分区:
- 使用污点和容忍度将集群划分为不同的资源池,提高调度效率。
-
缓存优化:
- 调度器维护节点的实时状态缓存,减少频繁访问 API Server 的开销。
示例:调度器的核心配置
以下是一个自定义调度配置的示例:
apiVersion: kubescheduler.config.k8s.io/v1
kind: KubeSchedulerConfiguration
profiles:
- schedulerName: my-custom-scheduler
plugins:
queueSort:
enabled:
- name: PrioritySort
preFilter:
enabled:
- name: PodTopologySpread
filter:
enabled:
- name: NodeResourcesFit
- name: NodeAffinity
score:
enabled:
- name: NodeResourcesLeastAllocated
weight: 1
- name: ImageLocality
weight: 1
总结
Kubernetes 调度器通过高效的调度流程和灵活的调度算法,确保集群中工作负载的最佳分布。调度器的插件化架构和可扩展性使得它可以满足多样化的业务需求,成为 Kubernetes 集群资源管理的核心组件。

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









