







摘要
将通过一个电商业务场景下的真实需求,带领大家零基础入门影刀编码版,本系列将会分三步讲解,从接到需求到最后完成发版,整个过程中我们需要做些什么?带你们走一个完整开发流程。
本文主要讲解上文拆出的各个模块的实现,主要包含:
打开网页,登录淘宝- 抓取总页数,循环
- 抓取每一页信息
涉及内容主要包含:元素定位–>选中元素的属性–>与选中元素进行交互(点击,悬浮,填写等)
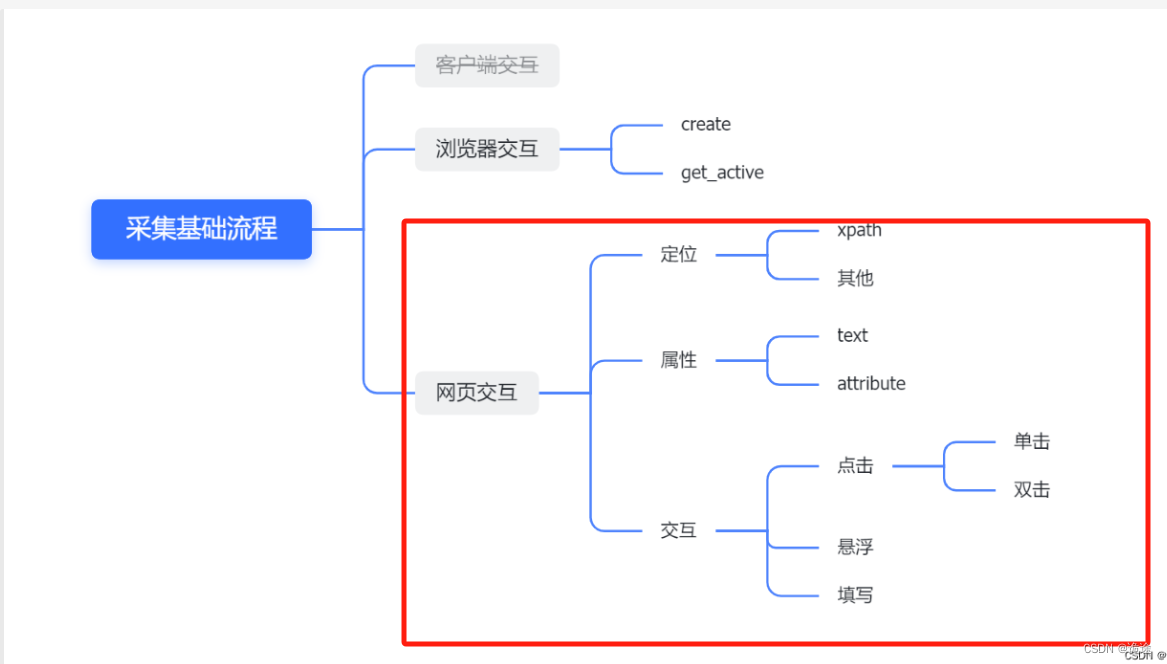
元素定位
浏览器 按F12 或选中一个页面元素鼠标右键检查
定位到元素后copy xpath,如果用其他方式可以选择对应路径,然后通过修改标签的属性去进行限制调整
更详细的知识请查阅前端资料了解下html的结构
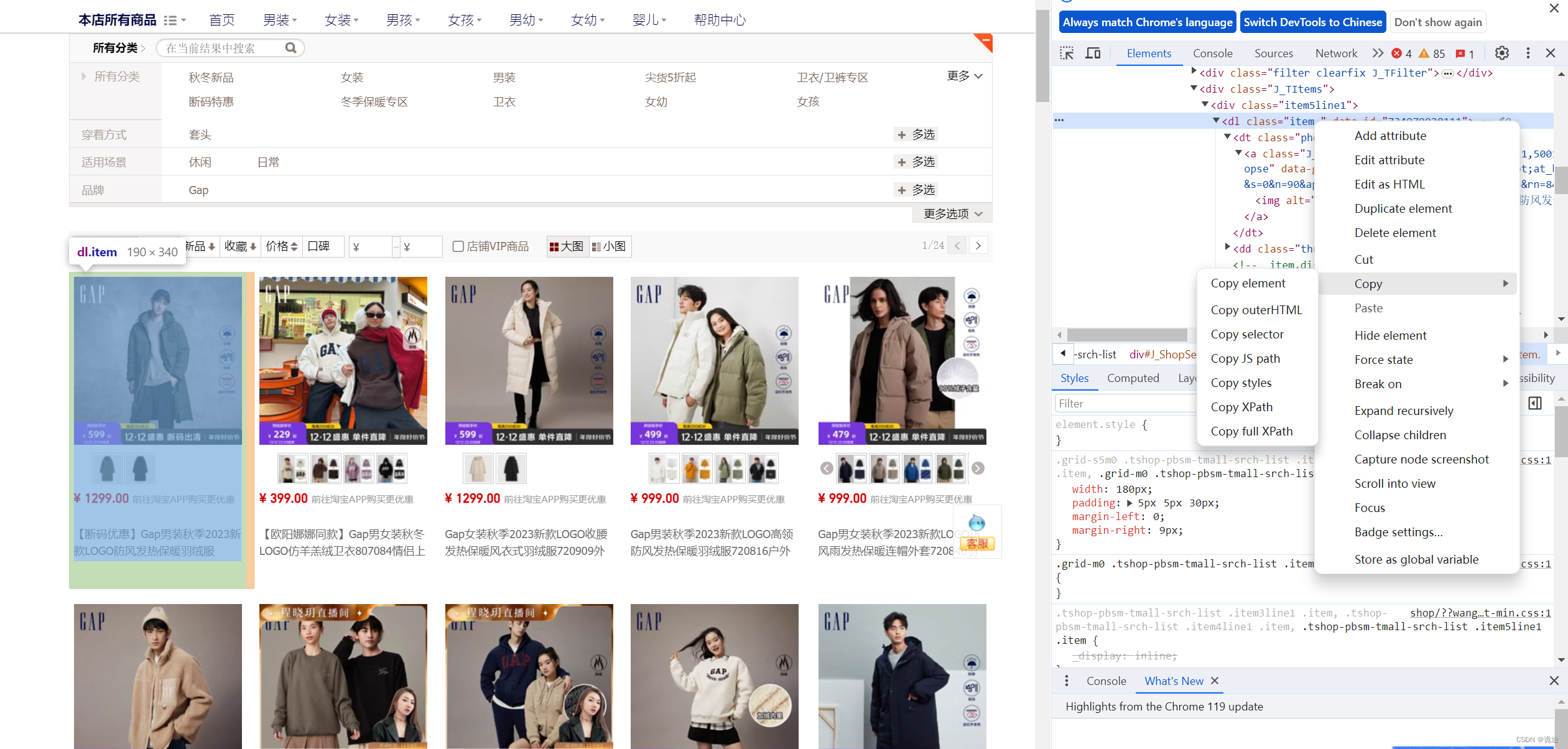
店铺所有宝贝
涉及知识点:
- 与网页建立交互
- xpath定位(所有)元素
- 元素点击
- 元素属性
- 循环判断
- 影刀数据表格处理

# webBrowser = login_info()
# url = "https://gap.tmall.com/search.htm"
# webBrowser.navigate(url)
# 随机休眠避免反扒
# sleep(random.uniform(2,3))
# 避免重复开网页以及网页跳转,测试时直接激活当前网页即可
webBrowser = xbot.web.get_active(mode="chrome")
page_count = 0
while True:
all_id_elements = webBrowser.find_all_by_xpath('//div[@class="J_TItems"]/div')
# print(len(all_id_elements))
result = []
for element in all_id_elements:
if element.get_attribute("class")=="pagination":
# print("到底了,点击下一页翻页")
# break
next_page_btn = element.find_by_xpath('//a[text()="下一页"]')
# 判断下一页是否可用,不可用则到末尾页了
next_page_btn_stau = next_page_btn.get_attribute("class")
if next_page_btn_stau !="disable":
next_page_btn.click()
break # 跳出当前循环
else:
# 获取每一组(一排5个)商品
dl_elements = element.find_all_by_xpath("dl")
for dl_element in dl_elements:
ID = dl_element.get_attribute("data-id")
ID_element = dl_element.find_by_xpath('dt/a/img')
ID_title = ID_element.get_attribute("alt")
ID_main_pic = ID_element.get_attribute("src")
print([ID,ID_title,ID_main_pic])
result.append([ID,ID_title,ID_main_pic])
page_count+=1
print(f"第{page_count}页抓取完成!")
if next_page_btn_stau =="disable":
break # 跳出所有循环
# 影刀的数据表格处理
# 对于apI路径:xbot->app->databook
# 写入前先清空
xbot.app.databook.clear()
# 数组插入数据表格
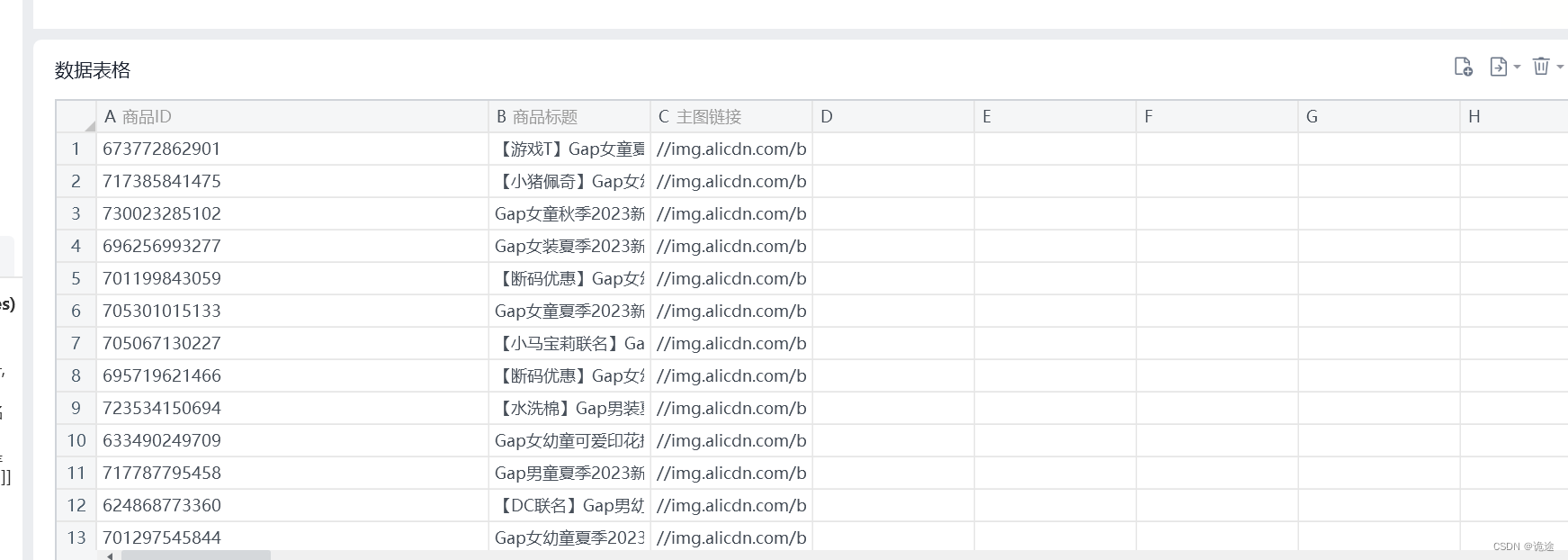
xbot.app.databook.set_range(1,1,result)
# 数据表格导出到对应文件路径
xbot.app.databook.export_data("GAP全店商品明细.xlsx")
单个宝贝详细信息
- 点击跳转,句柄切换
- 输入表单提交
- 网页元素处理
- xpath多种定位方法
# 输入表单提交
# 避免重复开网页以及网页跳转,测试时直接激活当前网页即可
webBrowser = xbot.web.get_active(mode="chrome")
# 第一次做这个案例时用的python 当时taobao还可以搜ID
# 现在搜不了,这里还是提一下输入表单提交吧,就用第一个的关键词欧阳娜娜同款搜吧
# 其实和其他处理一样,python会复杂一些,影刀里面就简单很多
# 定位到要输入框
input_element = webBrowser.find_by_xpath('//*[@id="mq"]')
# 输入内容
input_element.input("欧阳娜娜同款")
# 提交搜索
submit_btn = webBrowser.find_by_xpath('//*[@id="J_CurrShopBtn"]')
submit_btn.click()
# 避免重复开网页以及网页跳转,测试时直接激活当前网页即可
# webBrowser = xbot.web.get_active(mode="chrome")
# main_title = webBrowser.get_title()
# # # 用第一个商品测试
# ID_element = webBrowser.find_by_xpath('//dl[@data-id="734979928111"]')
# ID_element.click()
# 这里跳转后Python需要获取句柄进行切换
# 影刀可以直接用get_active进行切换,或者get_title也行,因为不知道每一页商品的title,所以用get_active最好
# 其实这个title就是商品的title
# 但是要切换回来应该用get_title,因为你的主网页的title是固定的
webBrowser= xbot.web.get_active(mode="chrome")
# print(webBrowser.get_url())# 验证下是否切进来
# 获取商品标题
TITLE = webBrowser.find_by_xpath('//h1[contains(@class,mainTitle)]').get_text()
active_price = webBrowser.find_all_by_xpath('//span[contains(@class,"Price--priceText")]')[0].get_text()
discounts = webBrowser.find_by_xpath('//span[text()="优惠:"]/../span[contains(@class,"caption")]').get_attribute("title")
active = webBrowser.find_by_xpath('//span[text()="活动:"]/../span[contains(@class,"caption")]').get_attribute("title")
item_infos = webBrowser.find_by_xpath('//span[text()="宝贝参数:"]/..').get_text()
print(TITLE,active_price,discounts,active,item_infos)
# 关闭当前页
# webBrowser.close()
# 切回搜索页
# webBrowser = xbot.web.get(main_title,mode="chrome")
pass


















 9460
9460

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











