







题意:给你行字符串,要你求出这个字符串在ascll编码下的编码长度和haffman编码下的编码长度,并求出两者的比值。
求解:ascll编码的长度就为字符串长乘以8。
至于haffman编码,介绍一下。在haffman编码中,我们统计每个字符出现的频率(次数),并将这个频率值作为这个字符的权重值,然后我们通过这些字符的权重值来建立一颗哈弗曼树以此来获取每个字符的haffman编码。首先,这是一颗二叉树,树种每个节点含有权重值(wei),关键字(key),左儿子(lc),右儿子(rc)这四个成员,只有叶子节点才有有效关键字(表示一个字符),也只有叶子节点才会有编码表示,且表示方法如下:从根节点开始使用递归来访问任意一个叶子节点,每次向左走(递归进入左儿子)时路径+“0”,每次向右走(递归进入右儿子)时路径+“1”(路径开始为空串)。当走到叶节点的路径便是这个叶节点的编码。如下图:
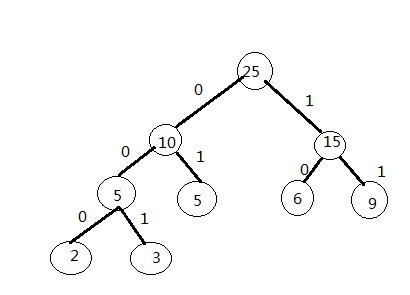
权重为2的叶子节点的编码就是:000,3的就是:001。
以上是haffman树的性质,当我们具体建树时,我们采用自底向上的方法。开始我们拥有全部叶子节点(关键字为字符,权重为字符出现频率),这些构成一个集合S。
1、每次我们从S中选取两个权值最小的节点,形成一个新的节点,新节点权重的左右儿子分别为这两个节点,并且其权重是两个儿子的权重的和,关键是不用设(因为形成的节点本来就不用编码,不代表任何字符)。
2、然后我们将选取的两个节点去除,将形成的节点加入S中,这样S中的节点数便减少1,如果S中的节点个数大于1个,则跳回步骤1,否则进入步骤3。
3、S中只有一个节点,这个就是我们的根节点,至此建树完毕。
然后通过dfs遍历haffman树我们可以轻松得到每个字符的编码及编码长度,也就能得出字符串的哈弗曼编码的长度。
代码如下:
#include<cstdio>
#include<cstring>
#include<iostream>
#include<algorithm>
#include<string>
#include<queue>
#define ll long long
using namespace std;
int ha[1010],hb[1010];
char str[1010];
int icount[300],num[300],l2;
struct Node{
int wei;
int key;
Node *lc,*rc;
};
Node *root;
struct cmp{
bool operator()(Node* node1, Node* node2){
return node1->wei > node2->wei;
}
};
priority_queue<Node*, vector<Node*>, cmp>pq;
void dfs(Node* r,string str){
if(r->lc==NULL) {
l2+=(str.length()*icount[num[r->key]]);
return;
}
dfs(r->lc,str+"0");
dfs(r->rc,str+"1");
}
void build_haffman_tree(){
Node* n1,*n2;
while(!pq.empty()){
n1=pq.top();
pq.pop();
if(pq.empty()){
root=n1;
break;
}
n2=pq.top();
pq.pop();
Node* temp=new Node;
temp->key=270,temp->wei=n1->wei+n2->wei;
temp->lc=n1,temp->rc=n2;
pq.push(temp);
}
dfs(root,"");
}
int main(){
while(scanf("%s",str)){
if(strcmp(str,"END")==0) break;
int len=strlen(str);
int l1=len*8,tt=0;
l2=0;
memset(icount,0,sizeof(icount));
for(int i=0;i<len;++i){
if(icount[str[i]]==0)
num[tt++]=str[i];
++icount[str[i]];
}
if(tt==1) l2=len;
else{
for(int i=0;i<tt;++i){
Node* node=new Node;
node->wei=icount[num[i]];
node->key=i;
pq.push(node);
}
build_haffman_tree();
}
printf("%d %d %.1f\n",l1,l2,l1*1.0/l2);
}
return 0;
}















 73
73











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









