







How the C++ Compiler Works
C++编译器的工作原理
介绍
C ++源编译器实际负责什么,我们把C ++代码写成文本,它只是一个文本文件,然后我们需要某种方式将该文本转换为我们的计算机可以运行的实际应用程序,从该文本形成一个实际的可执行二进制文件。我们基本上有两个主要操作需要发生,其中一个称为编译,一个称为链接。当前教程我们只是讨论编译,下个教程会介绍链接。C++编译器实际需要做的唯一事情就是获取我们的文本文件并将它们转换为称为目标文件的中间格式,然后可以将这些目标文件传递到链接器上,并且链接可以完成所有链接的事情,但无论如何,我们已经在这里谈论了编译,编译器在生成这些obj目标文件时实际上会做一些事情。
首先,它需要预处理我们的代码,这意味着任何预处理器语句都会被评估。基本上将我们C++ 语言变成编译器实际上可以理解和重新使用的格式,这基本上会导致创建称为抽象语法树的东西,它基本上是我们代码的表示,但作为一个绝对的语法树,编译器的工作归根结底是将所有代码转换为常量数据或指令。一旦编译器创建了这个抽象语法树,它就可以开始实际生成代码,现在这个代码将是我们的CPU将执行的实际机器代码,我们还最终会得到各种其他数据,例如存储所有常量变量的地方。这基本上就是所有编译器所做的。
接下来看看编译器得每个结算是如何工作得
文件
我们有一个简单的helloworld应用程序,我们看到这个Log函数,它实际上是在这个Log.cpp文件中定义的,它只是将我们的消息打印到屏幕上。
//main.cpp
#include <iostream>
void Log(const char* message);
int main()
{
Log("Hello World");
std::cin.get();
}
//Log.cpp
#include <iostream>
void Logr(const char* message)
{
std::cout << message << std::endl;
}
编译器所做的是为每个C++文件生成目标文件。我们的项目包含的每个CPP文件,我们实际上告诉编译器这个CPP文件,这些文件中的每一个都会产生一个目标文件。这些CPP文件本质上被称为翻译单元的东西。你必须意识到,你不用关心文件,文件不是C++中存在的东西。例如在Java中,你的类名必须绑定到你的文件名,你的文件夹层次结构必须绑定到你的包,这一切都在发生,因为Java期望某些文件存在。C++不是这样,就没有文件这样的东西,文件只是向编译器提供源代码的一种方式,你负责告诉编译器这是什么样的文件类型以及编译器现在应该如何处理它。
当然如果你创建一个文件,如果您创建一个扩展名为 .cpp 的文件,编译器会将其视为 C++ 文件。同样,如果我制作扩展名为.c或.h的文件,编译器会将.c文件视为C文件而不是C ++文件,并且它将.h文件视为头文件。这些基本上只是默认约定,你可以覆盖它们中的任何一个,这就是编译器将如何处理它,如果你不告诉它如何处理它。只要我告诉编译器这个文件是一个 C++ 文件,请像 C++ 文件一样编译它。
所以只要记住文件没有意义,记住这一点很重要,所以说我们输入编译器的每个C++文件,我们告诉它这是一个C++文件请编译它,它会编译为翻译单元,翻译单元将产生一个目标文件,实际上有时在其他 CPP 文件中,包含 CPP 文件并基本上创建一个大的 CPP 文件很多都在里面。
如果你喜欢这样的东西,然后你只编译一个CPP文件,你基本上会产生一个翻译单元,那就是一个对象文件。所以这就是为什么在翻译单元是什么和 cpp 文件实际是什么之间划分术语的原因,因为通常文件不一定等于翻译单元,但是如果您只是使用单独的 CPP 文件制作一个项目并且您永远不会将它们包含在彼此中。那么每个安全文件都将是一个翻译单元,每个 CPP 文件将生成一个对象文件。
我们看下生成得obj文件,因为包含iostream,其中有很多东西,所以这就是为什么它们如此之大,因此它们实际上非常复杂,所以在我们深入研究并查看文件中的实际内容之前,让我们创建一些更简单的东西。
添加一个名为Math.cpp得文件。我只是要写一个非常基本的乘法函数,它将两个数字相乘,我不会在这里包含任何文件或任何东西,我只是要写一个非常简单的函数,它将返回整数,它将被称为乘法,它将采用两个参数 int a 和 int b,然后它将创建一个结果变量,该变量存储 A 乘以 B 的结果,然后我们将返回该结果变量,很好很简单。
//Math.cpp
int Multiply(int a, int b)
{
int result = a * b;
return result;
}
Ctrl + F7 构建该文件,您可以在此处看到它已成功构建。我们回到输出文件我们可以看到Math.obj仅仅3KB
在我们看一下该目标文件中到底是什么之前,让我们先谈谈我前面提到的编译的第一阶段。预处理,在预处理阶段编译器基本上只是遍历我们所有的预处理语句并评估他们
我们常用的包括 define if 和 ifdef 他们都是预编译语句,它们准确地告诉编译器该做什么,我们看一下最常见的预处理器语句之一,#include它是如何工作的,所以#include实际上非常简单,你基本上指定要包含的文件,然后预处理器将打开它文件读取其所有内容并将其粘贴到您编写语句的文件中,仅此而已。
头文件
添加名为EndBrace.h的头文件,只输入一个右大括号
//EndBrace.h
}
我们回到Math.cpp文件把方法末尾的右大括号去掉,替换成#include 语句
int Multiply(int a, int b)
{
int result = a * b;
return result;
#include "EndBrace.h"
ctrl+f7 编译成功了,因为编译器所做的只是打开它并复制里面内容,然后将其粘贴到这里,仅此而已。
头文件已解决 您现在应该确切地知道它们是如何工作的以及如何使用它们,实际上有一种方法可以告诉编译器输出一个文件,其中包含所有这些已发生的预处理器评估的结果。
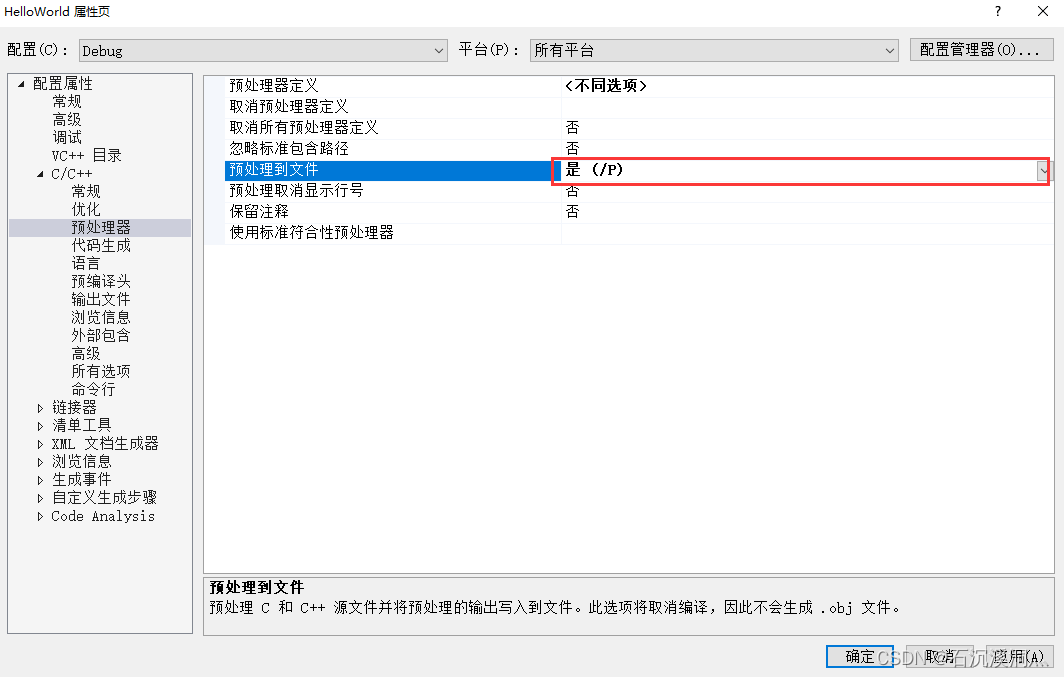
打开项目属性,把C/C++ 中的预处理器->预处理到文件选择是,然后重新编译Math.cpp
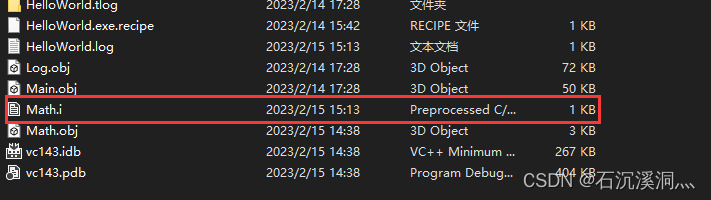
可以看到生成了预处理文件。打开这个预处理文件,可以看到预处理器实际生成了什么。预处理器把.h文件中的内容插入到了Math.cpp文件中
#line 1 "D:\\dev\\Cpp\\HelloWorld\\HelloWorld\\Math.cpp"
int Multiply(int a, int b)
{
int result = a * b;
return result;
#line 1 "D:\\dev\\Cpp\\HelloWorld\\HelloWorld\\EndBrace.h"
}
#line 6 "D:\\dev\\Cpp\\HelloWorld\\HelloWorld\\Math.cpp"
预处理器语句
我们在开头输入#define INTEGER int,这句话的意思将INTEGER 去替代文件中的任何位置的int
#define INTEGER int
INTEGER Multiply(int a, int b)
{
INTEGER result = a * b;
return result;
}
ctrl+f7 编译,我看可以查看预处理文件
#line 1 "D:\\dev\\Cpp\\HelloWorld\\HelloWorld\\Math.cpp"
int Multiply(int a, int b)
{
int result = a * b;
return result;
}
继续其他预处理语句
if 预处理器语句可以让我们根据给定条件包含或排除代码,所以在这里我只写 #if 1 这意味着 true,然后只写一个#endif
#if 1
int Multiply(int a, int b)
{
int result = a * b;
return result;
}
#endif
编译查看预处理文件
#line 1 "D:\\dev\\Cpp\\HelloWorld\\HelloWorld\\Math.cpp"
int Multiply(int a, int b)
{
int result = a * b;
return result;
}
#line 8 "D:\\dev\\Cpp\\HelloWorld\\HelloWorld\\Math.cpp"
如果把#if 1 改为 #if 0,Visual Studio将淡出我们的代码,以表明它已被禁用。查看预处理文件
#line 1 "D:\\dev\\Cpp\\HelloWorld\\HelloWorld\\Math.cpp"
#line 8 "D:\\dev\\Cpp\\HelloWorld\\HelloWorld\\Math.cpp"
这是预处理器语句理解的另一个很好的例子。我们重新把#include iostream 写到这个文件.编译之后查看预处理文件发现有几万行。当然,iostream还包括其他文件,所以这有点像从山上滚雪球。您看到为什么这些对象类如此之大,因为它们包含iostream,这是很多代码
禁用预处理器
如果你真的读过一个文件的预处理,你会发现它实际上不会产生一个 obj 文件,所以我们需要禁用它,以便我们可以实际构建我们的项目
所以让我们来看看我们的 obj 文件中实际是什么,如果我们使用文本编辑器打开这个文件,你会看到它是二进制的,并没有太大帮助,但这里实际里面的一部分是我们的 CPU 在我们调用这个Mutiply 函数时将运行的机器代码。所以因为这只是二进制的,完全不可读,让我们把它转换成一种实际上可能更易读的形式。
Visual studio
我们应该有几种方法可以做到这一点,要使用Visual Studio
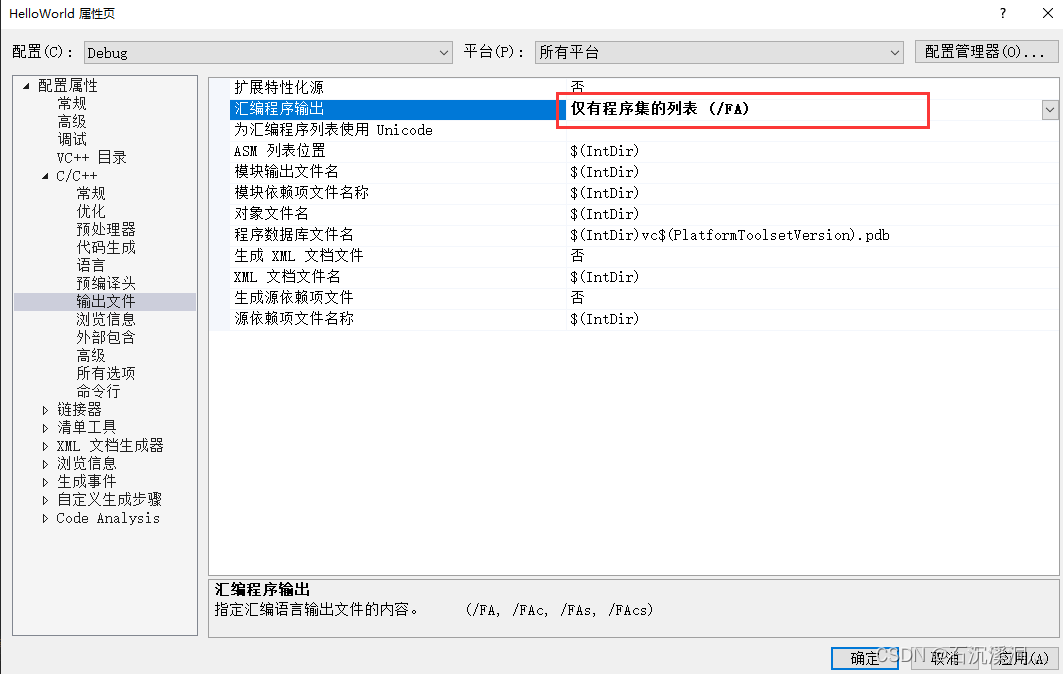
输出文件->汇编程序输出,选择 仅有程序集的列表(/FA),确定之后,重新编译我们的文件
 ··
··
...
//取一部分汇编代码
?Multiply@@YAHHH@Z PROC ; Multiply, COMDAT
; File D:\dev\Cpp\HelloWorld\HelloWorld\Math.cpp
; Line 2
$LN3:
mov DWORD PTR [rsp+16], edx
mov DWORD PTR [rsp+8], ecx
push rbp
push rdi
sub rsp, 264 ; 00000108H
lea rbp, QWORD PTR [rsp+32]
lea rcx, OFFSET FLAT:__C1830E75_Math@cpp
call __CheckForDebuggerJustMyCode
; Line 3
mov eax, DWORD PTR a$[rbp]
imul eax, DWORD PTR b$[rbp]
mov DWORD PTR result$[rbp], eax
; Line 4
mov eax, DWORD PTR result$[rbp]
; Line 5
lea rsp, QWORD PTR [rbp+232]
pop rdi
pop rbp
ret 0
?Multiply@@YAHHH@Z ENDP ; Multiply
...
在输出列表里面看到Math.asm的文件,这基本上是该对象文件实际包含的内容的可读结果,生成的汇编代码。
你会看到我们实际上有一个名为 Multiply 的函数,然后我们有一堆汇编指令,这些是我们的 CPU 在函数上时将执行的实际指令。
如果我们看一下Line 3的内容,你会看到我们的乘法运算实际上发生在这里,基本上我们将 a 变量加载到我们的 EAX 寄存器中,然后我们执行一个 imul 指令,这是对 b 变量的乘法指令,然后我们将一个变量的结果存储在一个名为 result 的变量中,并将其移回 EAX 以返回它。
发生这种双重移动的原因是因为我实际上创建了一个名为 result 的变量,然后返回它,而不仅仅是返回 a * b,这就是为什么我们将这个移动 EAX 移动到result 变量中,然后将result 移动到完全多余的 EAX 中。这是另一个很好的例子,为什么如果你将编译器设置为不优化,通过慢速的代码找到了答案。因为它无缘无故地做着这样额外的事情。如果我回到我的代码并且我实际上通过返回 a*b 而不重新命名result 变量,重新编译。
int Multiply(int a, int b)
{
return a * b;
}
...
; Line 3
mov eax, DWORD PTR a$[rbp]
imul eax, DWORD PTR b$[rbp]
; Line 4
...
你会看到程序集看起来略有不同,因为我们只是在做 a imul b 和 EXA,EXA 实际上将包含我们的返回值。
上述代码都是在Debug模式下编译,它不做任何优化,并做额外的事情来确保我们的代码尽可能多样化,尽可能易于调试
Debug
项目属性 C/C+±>优化->优化选择最大优化(优化速度)
注意:在配置为Debug下
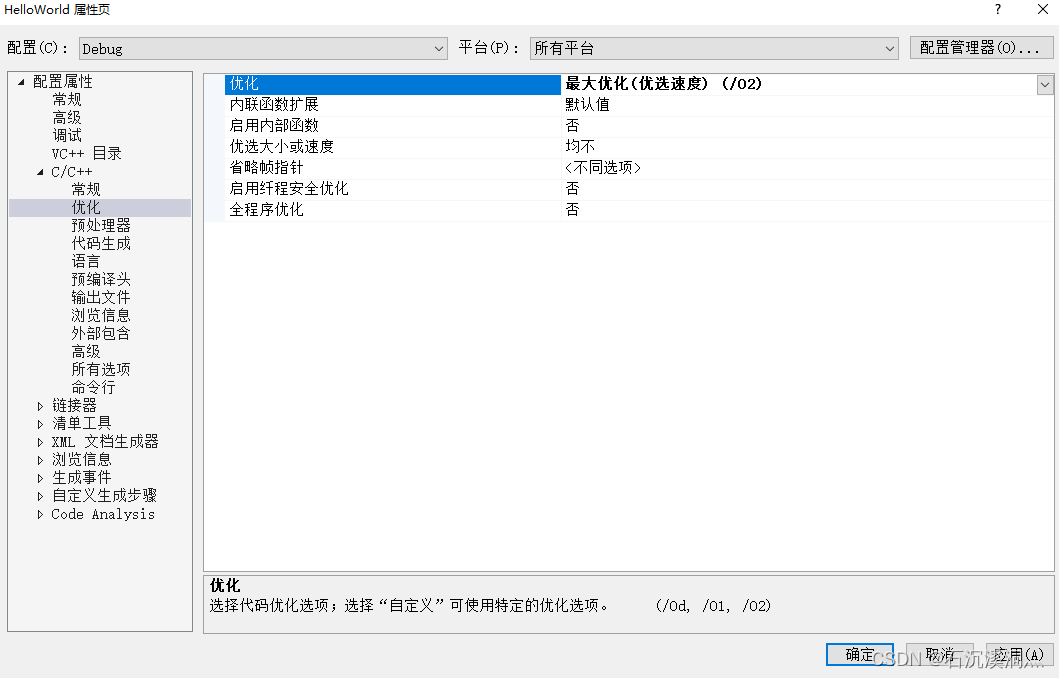
编译之后会发现,出现了不兼容的问题
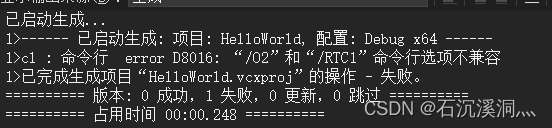
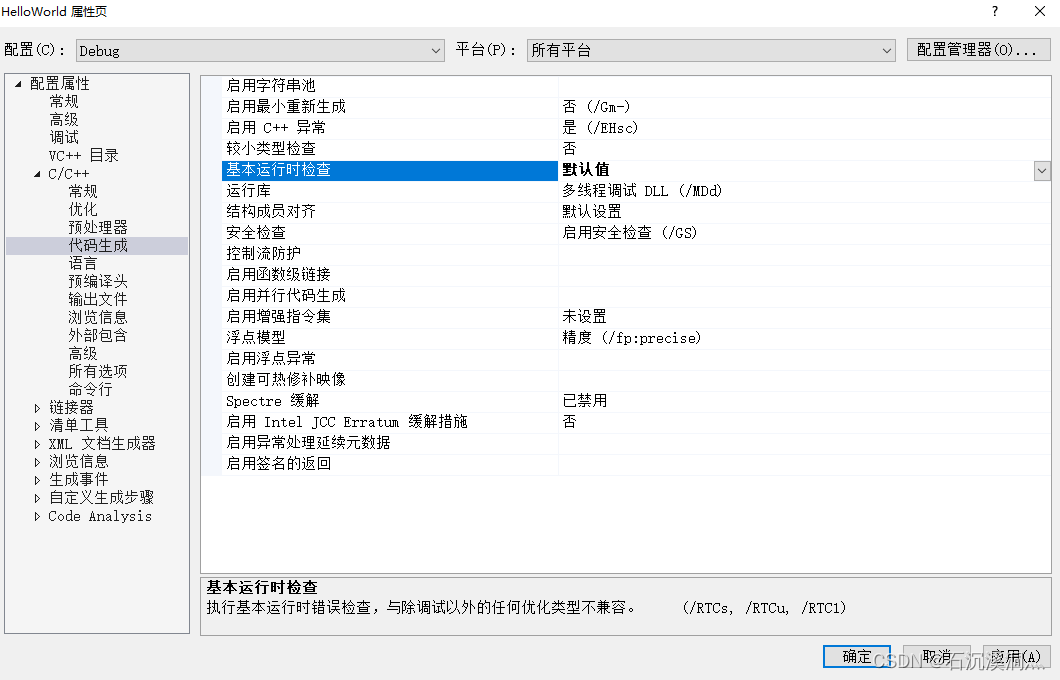
项目属性 C/C++ -> 代码生成-> 基本运行时检查修改为默认值。之前的配置只是编译器帮助我们调试代码。
编译生成,查看优化之后的编译代码对比之前的,少了很多。现在应该对编译器在你告诉它优化它时实际做了什么有一个基本的了解。
优化
int Multiply()
{
return 5 * 2;
}
; Line 2
$LN4:
sub rsp, 40 ; 00000028H
lea rcx, OFFSET FLAT:__C1830E75_Math@cpp
call __CheckForDebuggerJustMyCode
mov eax, 10
; Line 4
编译器会直接优化返回10,没有必要在运行时对两个常量值做 5*2 这样的事情.其中任何可以在编译时把常量都计算出来。
在文件中输入下面代码
//Math.cpp
const char* Log(const char* message)
{
return message;
}
int Multiply(int a, int b)
{
Log("Multiply");
return a * b;
}
编译查看Log汇编代码:
?Log@@YAPEBDPEBD@Z PROC ; Log, COMDAT
; File D:\dev\Cpp\HelloWorld\HelloWorld\Math.cpp
; Line 2
$LN3:
mov QWORD PTR [rsp+8], rcx
push rbp
push rdi
sub rsp, 232 ; 000000e8H
lea rbp, QWORD PTR [rsp+32]
lea rcx, OFFSET FLAT:__C1830E75_Math@cpp
call __CheckForDebuggerJustMyCode
; Line 3
mov rax, QWORD PTR message$[rbp]
; Line 4
lea rsp, QWORD PTR [rbp+200]
pop rdi
pop rbp
ret 0
?Log@@YAPEBDPEBD@Z ENDP ; Log
你可以看到它正在将我们的message指针移动到 EAX 中,这是我们建立的返回寄存器。再看下Mutilply函数的汇编代码
; Line 7
$LN4:
mov QWORD PTR [rsp+8], rbx
push rdi
sub rsp, 32 ; 00000020H
mov edi, ecx
mov ebx, edx
lea rcx, OFFSET FLAT:__C1830E75_Math@cpp
call __CheckForDebuggerJustMyCode
lea rcx, OFFSET FLAT:??_C@_08EOBDLMOI@Multiply@
call ?Log@@YAPEBDPEBD@Z ; Log
imul edi, ebx
mov rbx, QWORD PTR [rsp+48]
mov eax, edi
在相乘之前调用了Log函数。这就是编译器在调用函数时实际要做的事情,它将生成一个调用指令。
了解编译器如何工作的要点,它将采用我们的源文件并输出一个目标文件,其中包含机器代码和我们定义的任何其他常量数据,基本上是它以及我们如何获得这些目标文件,我们可以将它们链接到一个可执行文件中,其中包含我们实际需要运行的所有机器代码,这就是我们编程的方式















 2598
2598











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









