






Sharding-JDBC 工作流程
一、概述
Sharding-JDBC 的原理总结起来很简单:
SQL 解析 => 执行器优化 => SQL 路由 => SQL 改写 => SQL 执行 => 结果归并。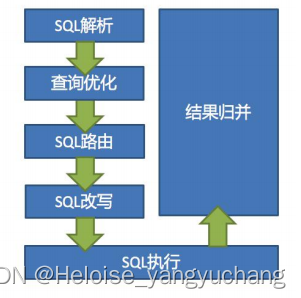
SQL 解析
SQL 解析主要是词法和语法的解析。Sharding-JDBC1.4.x 之前的版本使用 Druid 作为 SQL 解析器。从 1.5.x 版本开始,Sharding-JDBC 采用完全自研的 SQL 解析引擎。
SQL 路由
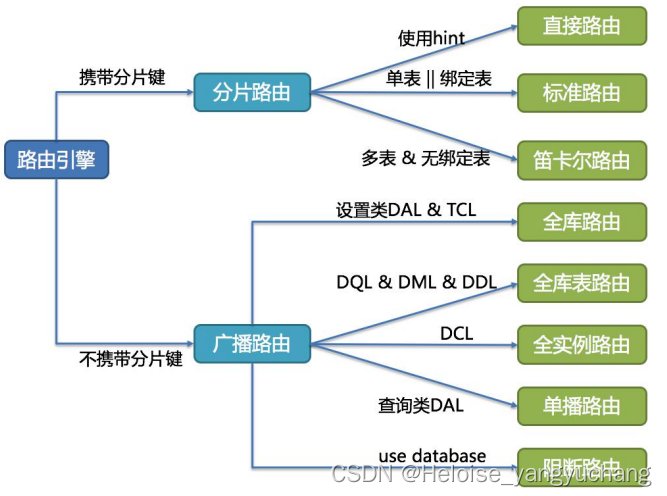
SQL 路由是根据分片规则配置以及解析上下文中的分片条件,将 SQL 定位至真正的数据源。它又分为直接路由(使用 Hint )、简单路由和笛卡尔积路由
SQL 改写
将逻辑表名称改成真实表名称,优化分页查询。
SQL 执行
因为可能链接到多个真实数据源, Sharding -JDBC 将采用多线程并发执行 SQL。
结果归并
数据的组装、分页、排序等等。
二、Sharding-JDBC 实现原理
ShardingJDBC 在执行过程中,主要是三个环节:
- 第一个是解析配置文件。
- 第二个是对 SQL 进行解析、路由和改写。
- 第三个把结果集汇总到一起返回给客户端。
之前讲过说 Sharding-JDBC 是一个增强版的 JDBC 驱动,JDBC 的四大核心对象:DataSource、Connection、Statement(PS)、ResulstSet。
Sharding-JDBC 实现了这四个核心接口,在类名前面加上了 Sharding。ShardingDataSource 、 ShardingConnection 、 ShardingStatement ( PS ) 、ShardingResulstSet。
如果要在 Java 代码操作数据库的过程里面,实现各种各样的逻辑,肯定是要从数据源就开始替换成自己的实现。当然,因为在配置文件里面配置了数据源,启动的时候就创建好了。下面用 核心就是ShardingDataSource 获 取 ShardingConnection 。
MyBatis 源码的查询方法最终会走到SimpleExecutor 的 doQuery()方法,doQuery() 方 法 里 面 调 用 了 prepareStatement() 创建连接 , 通 过ShardingDataSource 返回连接
private Statement prepareStatement(StatementHandler handler, Log statementLog) throws SQLException {
Statement stmt;
Connection connection = getConnection(statementLog);
stmt = handler.prepare(connection, transaction.getTimeout());
handler.parameterize(stmt);
return stmt;
}
它经过以下两个方法,返回了一个 ShardingConnection,
DataSourceUtil.fetchConnection()
Connection con = dataSource.getConnection();
基于这个 ShardingConnection,最终得到一个 ShardingPreparedStatement,
stmt = handler.prepare(connection, transaction.getTimeout());
然后就是SQL执行return handler.query(stmt, resultHandler);
public <E> List<E> query(Statement statement, ResultHandler resultHandler) throws SQLException {
PreparedStatement ps = (PreparedStatement) statement;
ps.execute();
return resultSetHandler.handleResultSets(ps);
}
最终调用的是 ShardingPreparedStatement 的 execute 方法。
public boolean execute() throws SQLException {
try {
clearPrevious();
prepare();
initPreparedStatementExecutor();
return preparedStatementExecutor.execute();
} finally {
refreshTableMetaData(connection.getShardingContext(), routeResult.getSqlStatement());
clearBatch();
}
}
prepare() 方法中,prepareEngine.prepare 调用
RouteContext routeContext = this.executeRoute(sql, clonedParameters);
执行路由
private RouteContext executeRoute(String sql, List<Object> clonedParameters) {
this.registerRouteDecorator();
return this.route(this.router, sql, clonedParameters);
}
最后到相应的路由执行引擎。














 324
324











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









