






并发编程之同步锁
一、概述
对之前写的Synchronized详解补充。
如果多个线程在做同一件事情的时候,会出现安全性问题:
- 原子性 Synchronized, AtomicXXX、Lock
- 可见性 Synchronized, volatile
- 有序性 Synchronized,volatile
原因:
- CPU 增加了缓存,以均衡与内存的速度差异;// 导致 可见性问题
- 操作系统增加了进程、线程,以分时复用 CPU(上下文切换)进而均衡 CPU 与 I/O 设备的速度差异;// 导致原子性问题
- 编译程序优化指令执行次序,使得缓存能够得到更加合理地利用。// 导致 有序性问题
线程安全的理解?
不应该是线程安全而应该是内存安全,堆内存是共享的,可以被所有线程访问,当多个线程访问同一个对象时,调用这个对象的行为都可以获得正确的结果(可以加额外的同步操作或者其他的协调操作,也可以不加),那么这个对象就是线程安全的。
二、原子性问题
问题:例如常见的,i++
原因:i++是属于Java高级语言中的编程指令,而这些指令最终可能会有多条CPU指令来组成,而i++最终会生成3条指令,如果要满足原子性,那么就需要保证某个线程在执行这个指令时,不允许其他线程干扰,然后实际上,分时复用 CPU(上下文切换)确实会存在这个问题。
也就是说只需要保证,i++这个指令在运行期间,在同一时刻只能由一个线程来访问,就可以解决问题。这就需要同步锁Synchronized
三、Synchronized 使用
synchronized有三种方式来加锁,不同的修饰类型,代表锁的控制粒度:
- 修饰实例方法,作用于当前实例加锁,进入同步代码前要获得当前实例的锁
- 静态方法,作用于当前类对象加锁,进入同步代码前要获得当前类对象的锁
- 修饰代码块,指定加锁对象,对给定对象加锁,进入同步代码库前要获得给定对象的锁。
直接修饰类粒度太大了,目前工作极少使用。
四、Synchronized 原理
Synchronized是如何实现锁的,以及锁的信息是存储在哪里? 线程A抢到锁了,线程B怎么知道当前锁被抢占了,这个地方一定会有一个标记来实现,而且这个标记一定是存储在某个地方。
1、Markword对象头
在Hotspot虚拟机中,对象在内存中的存储布局,可以分为三个区域:对象头(Header)、实例数据(Instance Data)、对齐填充(Padding)。
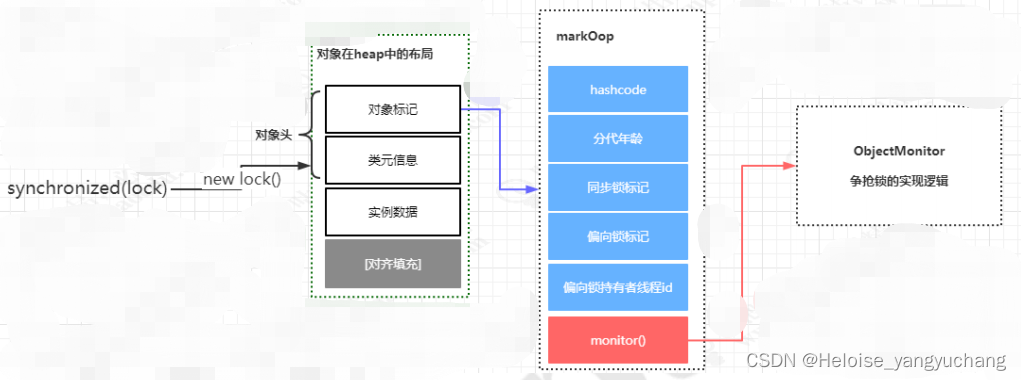
- mark-word:对象标记字段占4个字节,用于存储一些列的标记位,比如:哈希值、轻量级锁的标 记位,偏向锁标记位、分代年龄等
- Klass Pointer:Class对象的类型指针,Jdk1.8默认开启指针压缩后为4字节,关闭指针压缩( -XX:-UseCompressedOops )后,长度为8字节。其指向的位置是对象对应的Class对象(其对应的元数据对象)的内存地址。
- 对象实际数据:包括对象的所有成员变量,大小由各个成员变量决定,比如:byte占1个字节8比特位、int占4个字节32比特位。
- 对齐:最后这段空间补全并非必须,仅仅为了起到占位符的作用。由于HotSpot虚拟机的内存管理系统要求对象起始地址必须是8字节的整数倍,所以对象头正好是8字节的倍数。因此当对象实例数据部分没有对齐的话,就需要通过对齐填充来补全
2、监视器锁(Monitor)
每个对象都存在着一个 monitor 与之关联,对象与其 monitor 之间的关系有存在多种实现方式,如 monitor 可以与对象一起创建销毁或当线程试图获取对象锁时自动生成,但当一个 monitor 被某个线程持有后,它便处于锁定状态。
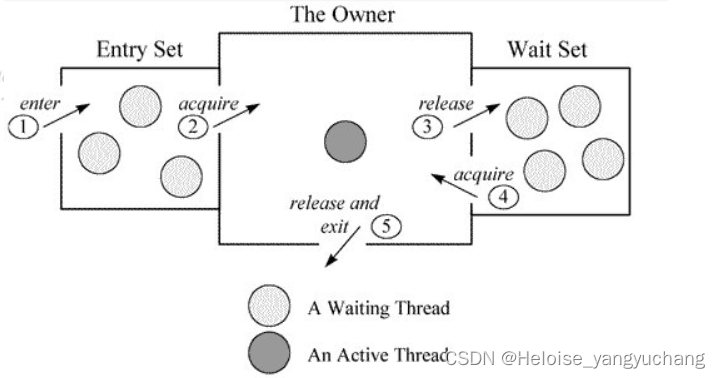
- _owner:指向持有 ObjectMonitor 对象的线程
- _WaitSet:存放处于 wait 状态的线程队列
- _EntryList:存放处于等待锁 block 状态的线程队列
- count:用来记录该线程获取锁的次数
五、Synchronized锁的升级
Jdk1.6对锁的实现引入了大量的优化,如自旋锁、适应性自旋锁、锁消除、锁粗化、偏向锁、轻量级锁等技术来减少锁操作的开销。
锁主要存在四中状态,依次是:无锁状态、偏向锁状态、轻量级锁状态、重量级锁状态,他们会随着竞争的激烈而逐渐升级。
这么设计的目的,其实是为了减少重量级锁带来的性能开销,尽可能的在无锁状态下解决线程并发问题,其中偏向锁和轻量级锁的底层实现是基于自旋锁,它相对于重量级锁来说,算是一种无锁的实现。
升级过程如下:
- 默认情况下是偏向锁是开启状态,偏向的线程ID是0,偏向一个偏向锁
- 如果有线程去抢占锁,那么这个时候线程会先去抢占偏向锁,也就是把markword的线程ID改为当前抢占锁的线程ID的过程
- 如果有线程竞争,这个时候会撤销偏向锁,升级到轻量级锁,线程在自己的线程栈帧中会创建一个LockRecord,用CAS操作把markword设置为指向自己这个线程的LR的指针,设置成功后表示抢占到锁。
- 如果竞争加剧,比如有线程超过10次自旋(-XX:PreBlockSpin参数配置),或者自旋线程数超过CPU核心数的一般,在1.6之后,加入了自适应自旋Adapative Self Spinning. JVM会根据上次竞争的情况来自动控制自旋的时间。
- 升级到重量级锁,向操作系统申请资源, Linux Mutex,然后线程被挂起进入到等待队列。














 414
414











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









