






Write Ahead Log策略(事务数据库系统):当事务条件时,先写重做日志,再修改页,(用日志恢复数据)
Checkpoint(检查点)技术(将脏页刷回磁盘)解决的问题:
缩短数据库恢复时间:数据库宕机时,不需要重做所有的日志,因为checkpoint之前的页已经刷到磁盘了
缓冲池不够用时,将脏页刷新到磁盘(给缓冲池腾空间):此时根据LRU算法会溢出最近最少使用的页(脏页),此时需强制执行Checkpoint,将脏页刷回磁盘
重做日志不可用时,刷新脏页(重做日志不可用,即不能保证数据的恢复了,就相当于每次操作都更新磁盘,保证数据准确性):事务数据库对重做日志的设计都是循环使用的(A,B,C三个日志组,当A用完了后,会发生日志切换,开启B(此为循环使用),并将A的数据拷贝到归档日志中(此为归档模式),若不是归档模式,则直接切换到B时,A的数据会丢弃)。
InnoDB通过LSN(Log Sequence Number)(8字节的数字)来标记版本,每个数据页,重做日志中,Checkpoint都有LSN,
通过show engine innodb status;查看
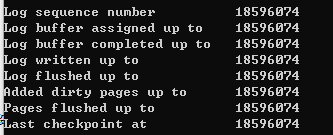
Sharp Checkpoint : 数据库关闭时,将所有脏页刷新回磁盘
Fuzzy Checkpoint : 刷新一部分脏页回磁盘(复杂在于刷哪一部分,什么时候刷)
Master Thread Checkpoint:异步的每秒或每十秒在Master Thread中发生,将缓冲池中的脏页列表按照一定比例刷
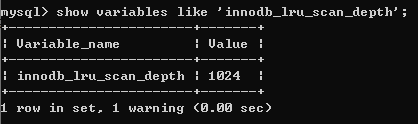
FLUSH_LRU_LIST_Checkpoint:Innodb需要保证LRU_List里面必须有1024个空闲页可用,现此检查放在单独的Page Cleaner线程中进行 ,show variables like 'innodb_lru_scan_depth';查看多少空闲页
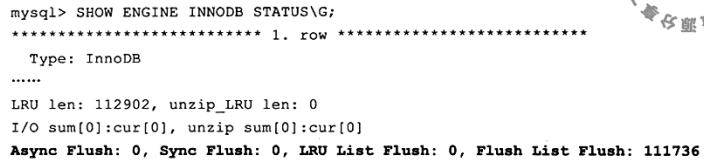
Async/Sync Flush Checkpoint:日志文件不可用时,强制将页刷新回磁盘,此时脏页是从脏页列表中选取的,此操作也在Page Cleaner Thread 中,show engine innodb status查看Checkpoint次数(没找到--尴尬)
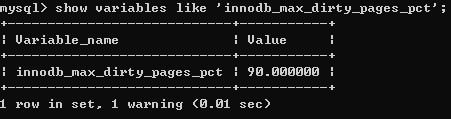
Dirty Page too much Checkpoint:脏页数量太多,Innodb强制进行Checkpoint操作,可用命令查看多少比例的时候进行此操作:show variables like 'innodb_max_dirty_pages_pct';(下图表示当脏页数量占据90%时,强制进行Checkpoint)
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









