







概念
Strategy模式也叫策略模式是行为模式之一, 他对一系列算法加以封装, 为所有的算法定义一个抽象的算法接口, 并通过继承该抽象算法接口对所有的算法加以封装和实现,具体的算法选择交由客户端决定(策略). Strategy模式主要用来平滑的处理算法的切换
结构
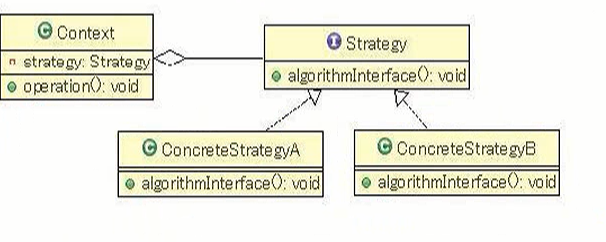
Strategy: 策略(算法)的抽象
ConcreteStrategy: 各种策略(算法)的实现
Context: 策略的外部封装类, 或者说策略的容器类. 根据不同的策略执行不同的行为. 策略由外部环境决定
这种设计客户只需要关心Context即可, 可以把Context 看成一个简单的工厂, 持有一个抽象算法的引用, 算法的实现可以有无限多个
代码
商家打折促销策略
//商家促销策略
public interface Strategy {
public double cost(double money);
}public class StrategyA implements Strategy {
// 策略A: 八折
@Override
public double cost(double money) {
return money * 0.8;
}
}public class StrategyB implements Strategy {
// 策略B: 满200返50
@Override
public double cost(double money) {
if (money >= 200) {
return money - 50;
}
return money;
}
}public class MainClass {
public static void main(String[] args) {
Context context = new Context(new StrategyA());
// Context context = new Context(new StrategyB());
System.out.println(context.cost(200));
}
}优点
1. 策略模式提供了管理相关算法族的办法. 策略类的等级结构定义了一个算法或行为族. 恰当的使用继承可以把公共的代码移到父类里面, 从而避免重复的代码
2. 策略模式提供了可以替换继承关系的办法. 继承可以处理多种算法或行为. 如果不是用策略模式, 那么使用算法或行为的环境类就可能会有一些子类, 每一个子类提供一个不同的算法或行为. 但是, 这样一来算法或行为的使用者就和算法或行为本身混在一起. 决定使用哪一种算法或采用哪一种行为的逻辑和算法或行为的逻辑混合在一起, 从而不可能再独立演化. 继承使得动态改变算法或行为变得不可能
3. 使用策略模式可以避免使用多重条件转移语句(if). 多重转移语句不易维护, 他把采取哪一种算法或行为的逻辑与算法或行为的逻辑混在一起,统统列在一个多重转移语句里面, 比使用继承的办法还要原始和落后
缺点
1. 客户端必须知道所有的策略类, 并自行决定使用哪一个策略类. 这就意味着客户端必须理解这些算法的区别, 以便适时选择恰当的算法类. 换言之,策略模式只适用于客户端知道所有的算法或行为的情况
2. 策略模式造成很多的策略类. 有时候可以通过把依赖于环境的状态保存到客户端里面, 而将策略类设计成可共享的, 这样策略类实例可以被不同的客户端使用. 换言之, 可以使用享元模式来减少对象的数量















 1670
1670

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









