







目录
一、Impala 基本介绍
impala 是 cloudera 提供的一款高效率的 sql 查询工具,提供实时的查询 效果,官方测试性能比 hive 快 10 到 100 倍,其 sql 查询比 sparkSQL 还要更快速,号称是当前大数据领域最快的查询 sql 工具, impala 是基于 hive 并使用内存进行计算,兼顾数据仓库,具有实时,批 处理,多并发等优点。
二、Impala 与 Hive 关系
impala 是基于 hive 的大数据分析查询引擎,直接使用 hive 的元数据库 metadata,意味着 impala 元数据都存储在 hive 的 metastore 当中,并且 impala 兼 容 hive 的绝大多数 sql 语法。所以需要安装 impala 的话,必须先安装 hive,保证 hive 安装成功,并且还需要启动 hive 的 metastore 服务。
客户端连接 metastore 服务,metastore 再去连接 MySQL 数据库来存取元数 据。有了 metastore 服务,就可以有多个客户端同时连接,而且这些客户端不需 要知道 MySQL 数据库的用户名和密码,只需要连接 metastore 服务即可。
Hive 适合于长时间的批处理查询分析,而 Impala 适合于实时交互式 SQL 查 询。可以先使用 hive 进行数据转换处理,之后使用 Impala 在 Hive 处理后的结果 数据集上进行快速的数据分析。
三、Impala 与 Hive 异同
Impala 跟 Hive 最大的优化区别在于:没有使用 MapReduce 进行并行 计算,与MapReduce相比,Impala把整个查询分成一个执行计划树,而不是一连串的MapReduce 任务,在分发执行计划后, Impala 使用 拉取获取数据的方式获取数据, 把结果数据组成 按执行数流式传递汇集,减少了中间结果写入磁盘的步骤,再从磁盘读取数据的开销。
1、内存使用
Hive: 在执行过程中如果内存放不下所有数据,则会使用外存,以保证 Query 能顺序执行完。每一轮 MapReduce 结束,中间结果也会写入 HDFS 中,同样由于 MapReduce 执行架构的特性,shuffle 过程也会有写本地磁盘的操作。
Impala: 在遇到内存放不下数据时,版本 1.0.1 是直接返回错误,而不会利用 外存,以后版本应该会进行改进。这使用得 Impala 目前处理 Query 会受到一定 的限制,最好还是与 Hive 配合使用。
2、调度
Hive: 任务调度依赖于 Hadoop 的调度策略。
Impala: 调度由自己完成,目前只有一种调度器 simple-schedule,它会尽量 满足数据的局部性,扫描数据的进程尽量靠近数据本身所在的物理机器。
3、适用面
Hive: 复杂的批处理查询任务,数据转换任务。
Impala:实时数据分析,因为不支持 UDF,能处理的问题域有一定的限制, 与 Hive 配合使用,对 Hive 的结果数据集进行实时分析。
4、容错
Hive: 依赖于 Hadoop 的容错能力。
Impala: 在查询过程中,没有容错逻辑,如果在执行过程中发生故障,则直 接返回错误(这与 Impala 的设计有关,因为 Impala 定位于实时查询,一次查询 失败, 再查一次就好了,再查一次的成本很低)。
四、Impala 架构
Impala 主要由 Impalad、 State Store、Catalogd 和 CLI 组成。 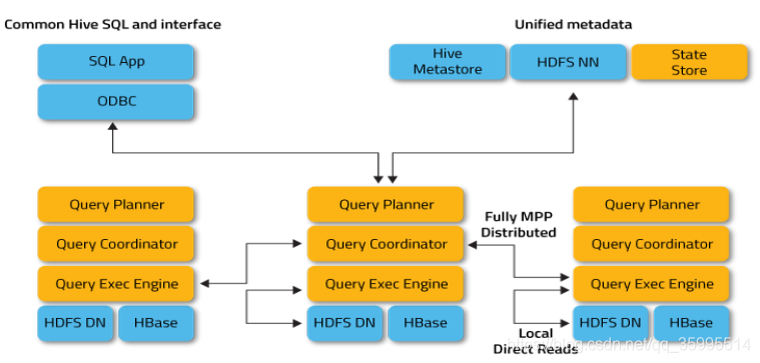
Impalad: 与DataNode 运行在同一个节点上,由Impalad进程表示, 它接收客户端请求,读写数据,并执行查询计划(
(接收查询请求的 Impalad 为 Coordinator,Coordinator 通过 JNI 调用 java 前端解释 SQL 查询语句,生成查询计划树,再通过调度器把执行计划分发给具有相应数据的 其它 Impalad 进行执行);
Impala State Store: 监视集群中 Impalad 的健康状况及位置信息,与各 Impalad 保持心跳连接;
Catalogd: 从 Hive Metastore 等外部 catalog 中获 取元数据信息,放到 impala 自己的 catalog 结构中;
CLI: 查询使用的命令行工具(Impala Shell 使用 python 实现),同 时 Impala 还提供了 Hue,JDBC, ODBC 使用接口。
五、Impala 查询处理过程
Impalad 分为 Java 前端与 C++处理后端,接受客户端连接的 Impalad 即作 为这次查询的 Coordinator,Coordinator 通过 JNI 调用 Java 前端对用户的查询 SQL 进行分析生成执行计划树。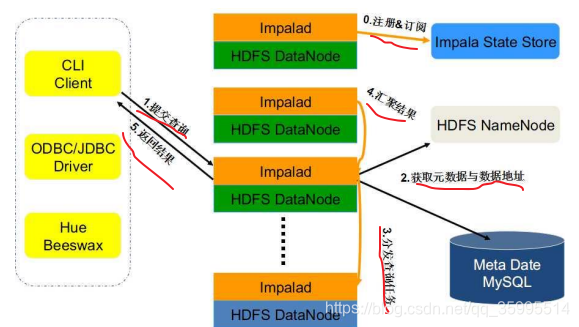
我的总结如下:

六、表数据的准备
这是要加载到数据中的文件,表的格式是正确的,以 .csv 结尾的文件
// student 文件
01 赵雷 1990-01-01 男
02 钱电 1990-12-21 男
03 孙风 1990-05-20 男
04 李云 1990-08-06 男
05 周梅 1991-12-01 女
06 吴兰 1992-03-01 女
07 郑竹 1989-07-01 女
08 王菊 1990-01-20 女
// teacher 文件
01 张三
02 李四
03 王五
// course 老师id
01 语文 02
02 数学 01
03 英语 03
// s_id , c_id, s_score
01 01 80
01 02 90
01 03 99
02 01 70
02 02 60
02 03 80
03 01 80
03 02 80
03 03 80
04 01 50
04 02 30
04 03 20
05 01 76
05 02 87
06 01 31
06 03 34
07 02 89
07 03 98创建学生表:
// 创建 教师表
create external table teacher (t_id string,t_name string) row format
delimited fields terminated by '\t';
// 创建 学生表
create external table student (s_id string,s_name string,s_birth string ,
s_sex string ) row format delimited fields terminated by '\t';
// 向 学生表中加载数据 impala 中 只能通过 HDFS 加载数据文件
load data inpath '/impala/student.csv' into table student;注意:这里 对 文件的操作的权限 要修改的 ,我直接 改为 777,可读可写可执行。
// 将 这个文件下的 以 .csv 结尾的都改了
hdfs dfs -chmod -R 777 /impala/*.csv
// 还要 该文件的 权限 ,不然 文件 加载不到数据中
hdfs dfs -chmod -R 777 /impala
说明一点:这里的HDFS 文件加载 跟 hive 中是一样的 ,加载文件就是文件的移动(换了地方),而数据 及数据库的表 以文件形式存在。
查看一下 表中是否有数据,再从 catalog默认的 端口中 查看表存在。
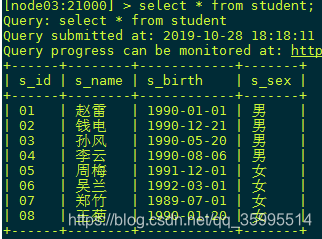
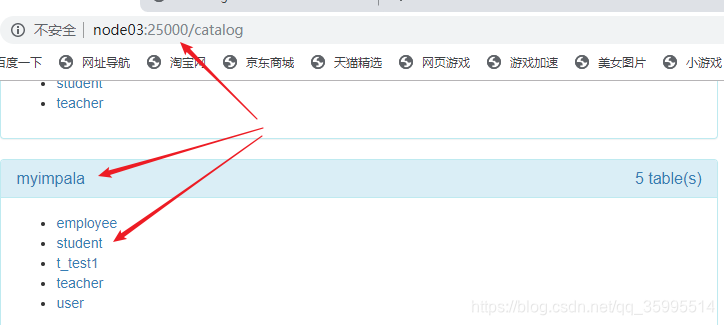
创建表 插入数据
create table employee (Id INT, name STRING, age INT,address STRING, salary
BIGINT);
insert into employee VALUES (1, 'Ramesh', 32, 'Ahmedabad', 20000 );
insert into employee values (2, 'Khilan', 25, 'Delhi', 15000 );
Insert into employee values (3, 'kaushik', 23, 'Kota', 30000 );
Insert into employee values (4, 'Chaitali', 25, 'Mumbai', 35000 );
Insert into employee values (5, 'Hardik', 27, 'Bhopal', 40000 );
Insert into employee values (6, 'Komal', 22, 'MP', 32000 );这里插入数据有个明显的感受就是 由于不进行MapReduce 了,插入数据速度很快。但是我根据 50070 查看 HDFS ,妈呀这么多小文件,感觉就不好了,这要是很多,NameNode肯定要保存 很多的元数据信息。

delete、truncate table
delete : 使用此命令时必须小心,因为删除表后,表中可用的所有信息也将永 远丢失。
truncate : Truncate Table 语句用于从现有表中删除所有记录。保留表结构。
七、view视图(这个hive也有)
视图仅仅是存储在数据库中具有关联名称的 Impala 查询语言的语句。 它是 以预定义的 SQL 查询形式的表的组合。 视图可以包含表的所有行或选定的行。
创建 员工表的视图 , 给公司小白 只能 允许操作 name,age, address 字段信息
create view employee_view as select name,age,address from employee;
剩下的order by, group by ,having ,limit ,distinct ,跟我们学习的 SQL 差不多,掌握好 hive , Impala 的学习很容易。
补充一下:我们的 Impala ------> hive 的数据可以自动 更新过去,但是 反过来不可以,我们 要手动 刷新数据库
refresh dbname.tablename :增量刷新,刷新某一张表的元数据,主要用 于刷新 hive 当中数据表里面的数据改变的情况。
invalidate metadata :全量刷新,性能消耗较大,主要用于 hive 当中新 建数据库或者数据库表的时候来进行刷新。


















 785
785

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











