









歌声和语音声带振动周期的快速可靠F0估计方法
原文题目:
Fast and reliable F0 estimation method based on the period extraction of vocal fold vibration of singing voice and speech
发表在:
AES 35TH INTERNATIONAL CONFERENCE, London, UK, 2009 February 11–13
本文提出了一种快速可靠的歌声实时交互应用的基频提取方法。它是基于声带振动的周期检测,所以它不需要昂贵的计算成本,如STFT或自相关。并行处理架构和一个新的成本函数使这个简单的想法与最先进的F0估计方法效果相当。一系列测试表明,所提出的方法在速度和准确性方面优于传统方法。最后,采用快速和深度振动的人工测试信号进行对比测试,验证了该方法在歌唱声音交互实时应用中的有效性。
引言
基频(F0)是歌唱合成软件中最重要的参数。例如,Melodyne1或AutoTune2用于固定F0轨迹。使用这些软件,使从平庸的歌声中创造自然而有吸引力的歌声成为可能。最近,一种基于声码器的高质量歌唱系统[1]被用来改变基于F0轨迹的歌唱风格。该系统STRAIGHT[2]为基础,可以将初学者的唱腔变成专业人士的唱腔。F0提取方法对于实现这种交互式和实时应用程序是必不可少的。
传统的F0提取方法通常基于自相关、倒谱[3]、瞬时频率[4]及其组合。为了提高估计的准确性,已经提出了许多用于各种目的的修改。例如,后处理可以减少F0估计误差[5]。对于在噪声环境下录制的语音,也提出了一种抗噪声鲁棒方法[6]。然而,游戏和多媒体内容的录音材料通常包含少量噪声。因此,一种快速可靠的基频提取方法对于这些应用至关重要。
假设输入信号中噪声很小,则最简单的基频提取方法就是直接测量周期信号基频分量的周期。Yegnanarayana提出了一种基于事件的F0提取方法,使用零频率滤波来表示印度顿音[7]。该F0估计方法是基于对滤波提取的基分量的区间测量。然而,设计基波分量提取滤波器需要对基波频率有较好的了解。
我们通过引入一个新的基本成分提取准则扩展了该F0提取方法。主要思想是使用多个F0检测器而不是一个专门的检测器。并行处理架构使用了许多候选滤波器和一个新的基本准则,使这个简单的想法与最先进的F0估计方法相媲美。本文讨论了基频分量提取器的设计、基频的定义以及所提方法的有效性。
方法
本节介绍检测声带振动间隔的步骤。区间检测方法包括三个步骤。图1显示了所提方法的整体和三个步骤。
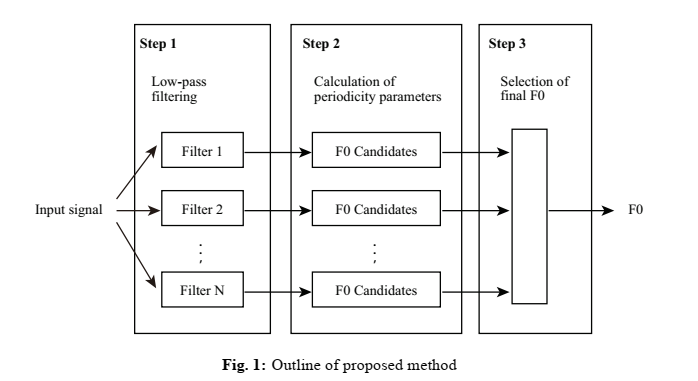
第一步是用低通滤波提取基本分量。使用几个候选过滤器来提取唯一的基本成分。
第二步是计算所有滤波信号的四个过零间隔。从这四个区间计算出一个新的基度判据。这些参数的定义和细节将在第后面解释。
最后一步是从计算的基度中选择最佳F0。利用该基度对所有滤波后的信号进行评估,并在最后一步选择最可靠的F0。
STEP1:使用几个具有不同截止频率的低通滤波器进行滤波
该方法需要一个副瓣很低的低通滤波器来提取唯一的基本分量。在本文中,使用纳托尔窗口[8]作为低通滤波器,其旁瓣约为-90 dB。Nuttall窗口定义为:
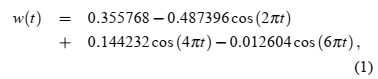
t的范围:0 ≤ t ≤1
图2显示了纳托尔窗口的功率谱,其长度决定了截止频率。
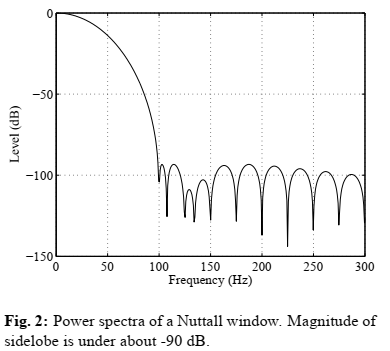
该方法使用了几个不同长度(截止频率)的候选窗口。通过步骤2中解释的基度,从这些滤波信号中计算出F0候选信号。滤波器的数量是该方法所使用的设计参数之一。为了实现所提出的方法,通过定义F0范围的下限和上限来确定滤波器的数量。在本文中,使用了40 Hz的下限和800 Hz的上限。测试了两种滤波器在一个八度内的排列方式。一个是一个八度有4个通道,另一个是一个八度有24个通道。
STEP2:计算基度fundamentalness和候选F0候选值
从图3所示的四个过零区间计算出一个新的标准,即基度。基度定义为负、正过零区间的方差和连续的峰与低谷之间的间隔。这种差异对于识别基本成分是非常有用的。如果滤波后的信号只包含基波分量,则四个区间的方差为零。从截止频率到滤波器输出的瞬时频率的映射的不动点中选择F0个候选点。
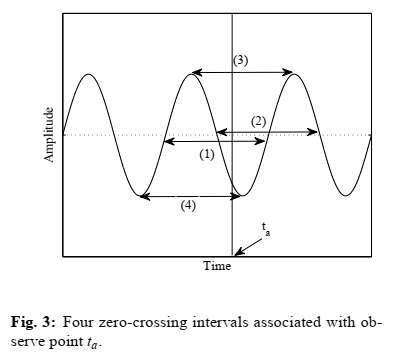
STEP3:基于基度选出最终F0
从所有滤波信号的基度计算中选出最佳候选信号。这一步选取每个观测点的最低基度。如果允许在F0提取后进行修改,我们可以保留多个候选项以降低错误率。
该方法有几个重要的参数,以保证准确提取F0。低通滤波器的类型和候选滤波器的数量主要关系到所提出方法的准确性。在本文中,我们关注的是滤波器的数量,因为纳托尔窗口已经接近该方法的最佳窗口。
评估
利用语音数据库和具有快速和深度振动的人工测试信号进行了两次评估,以证明所提出方法的有效性。并对该方法的处理速度进行了评价,讨论了该方法在歌唱声音的交互式实时应用中的适用性。
利用语音数据评估:
使用语音信号数据库对所提出的方法与以前的方法进行了比较。这个数据库包括一名男性和一名女性说话者,他们每人说50个英语句子,总共0.12小时的讲话;可以从以下网址下载:(http://www.cstr.ed.ac.uk/research/projects/fda/)。这个数据库是用喉镜的信号记录的。基于喉镜的参考F0包括在这个数据库中。
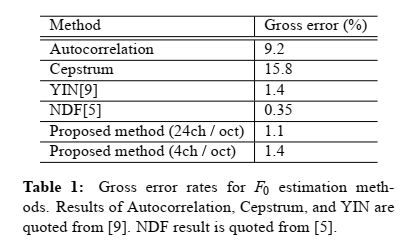
与喉镜估计值相差超过20%的值属于严重误差[9]。本文方法与Praat系统的Boersma自相关方法、倒谱法和未经后处理的YIN[9]进行了比较。后处理也采用NDF[5]。该方法的候选滤波器个数分别为4个和24个。
表1显示了每种方法的总误差。自相关法、倒谱法和YIN的结果引自[9],NDF结果引自[5]。NDF是所有方法中最好的,但其处理时间比我们提出的方法要长得多,比没有后处理的传统方法性能更好。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









