







用通俗语言说自己的理解
先引入一些概念,最后会说事务隔离是如何实现的
一:事务隔离级别
假设有两个事务,A和B,A事务是读数据,B事务的增删改数据。
- 读未提交。 B事务想增、删、改一条数据,且执行完了sql语句,但是还没有提交事务,这时事务A进来了,读到了上述新增、修改的数据或读不到被B删除的数据。
- 读已提交 。与上述相反,B事务没有提交的话,A事务无法读到B增、改后的数据,且即便事务删除了数据,此时A事务也可以读取到。
- 可重复读。先说说什么是不可重复读(即读已提交):开启事务A,并读取数据,比如读取用户id=10的名称,此时读到name=张三,这时,事务B开启了,将张三改为李四,然后提交B事务,鉴于上一条读已提交,这时事务A再去读取数据时,事务B已经提交了,那么读到的name值就变成了李四。因为 事务A从开启后一直没有关闭,且过程中 读取了两次数据时,分别读取到了不同的结果。同一事务中多次读取数据时,数据不一样,就是 不可重复读。与之对应的 可重复读就是:同一事务中多次读取事务,数据每次都是一样的,哪怕事务B在两次读取之间将这个数据删除掉了,我们第二次读取时依然可以读取到。
- 序列化,可以理解成read和write操作都是加锁的。不存在两个事务同时访问|修改同一份数据。
二、一条记录的结构
其实一条数据上有很多个隐藏字段,这里只说几个和本文有关的。
- roll_pointer 指向该数据的上一个版本
- delete_mask 标记数据是否被删除。所以我们删除数据实际上并没有从磁盘上删除掉
- trx_id 生成这条数据的 事务id
三.MVCC-版本链
一条数据从第一次被插入到数据库中后,每一次修改都不会从磁盘上删除,而且写入了undo日志中,
这些 不同版本的数据通过roll_pointer这个指针 形成了一个链表。每条数据中都记录了 是哪个事务
创造了自己。
四、MVCC-readView
查询开启时都会在内存中生成一个对象,这个对象就是个快照,记录了一些信息去保证在后续判断中使得我们隔离级别生效
如果开启了事务,分配的事务id是递增的
只有在对表中的记录做改动时(执行INSERT、DELETE、UPDATE这些语句时)才会为事务分配事务id,否则在一个只读事务中的事务id值都默认为0。
快照中记录了哪些信息?
- trx_ids 快照创建时系统中活动的事务id集合
- min_trx_id 快照创建时系统中活动的事务中 id最小的事务
- max_trx_id 快照创建时 系统应该给下一个开启的事务 分配的id ,并不是活动最大id的事务
- create_trx_id 当前事务id,即创建该快照的事务id
以上把所有概念都说了一遍,接下来说如果实现隔离级别
隔离级别是如何实现
首先 把快照中的这些数据 画成一条线,下方有对图的解释
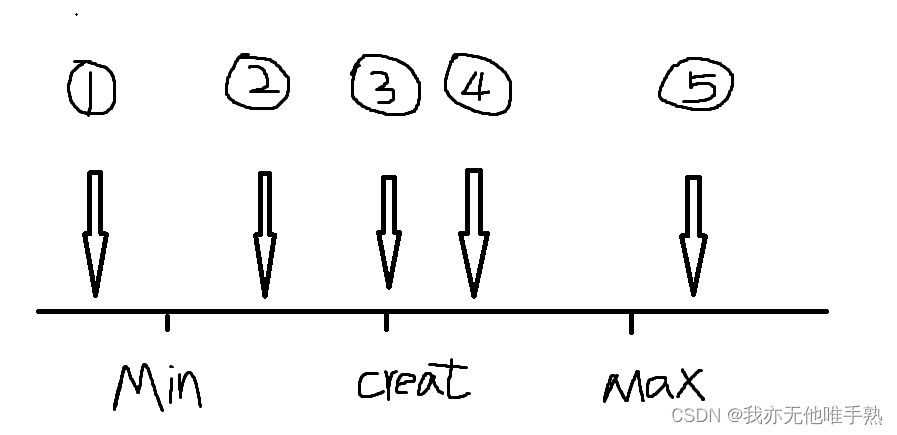
- x轴代表了快照中 活动的事务id排序,包括了最小id事务(min),系统应该分配给下一个开启的事务的id(max),也包括了创建该快照的事务(create)
- 这时候我们的查询语句查到了一条数据,这条数据上 有个隐藏字段 trx_id(记录了生成该记录的事务id),拿这个事务id 和上述X轴的事务进行大小比较,可能出现的位置为上述图中的 五种情况。现在分别说不同位置时解决了哪些问题。
情况一:
生成该记录的事务id小于最小事务id,说明我们本次查询时,这条数据已经生成了,并且事务已经提交。
进一步解释一下:
1.上文中提到过,开启事务时,系统分配了这个事务一个id(只读事务id为0)加入我们创建readView时,
得到的值分别是:
min_trx_id=100
max_trx_id=200
ids=[100,150,179]
create_trx_id=179
2.找到了一个数据,数据的最新版本上的trx_id=50,说明这个数据是由 id=50的事务创建的。
3.我们快照中最小id=100,说明快照创建时 这个id=50的事务已经提交了。那这条数据可以读出来。
如果还是不懂的话,可以这样理解,回顾一下事务隔离级别的第一个 【读未提交】,可以读到
未提交事务的数据。如果我们的隔离级别是【读未提交】,那么就没有必要创建一个快照,进行
数据对比了。我们的目的就是 先达到【读已提交】这个隔离级别。不可以读到那些没有提交的事务
所创建的记录。
4.补充一点第3点,万一人家事务没有提交,你就把数据给读出来了,那万一人家回滚了呢,所以
没有提交的事务,是不能读的。
情况五
没错,先说情况五,即 创建数据的事务id是大于max的。所以该记录不可用。
进一步解释:
1.假如当前找到的数据 是事务 300创建的。
2.创建快照时,我们本身事务id=179,那么系统应该分配的下一个具有增删改功能的事务id
应该是180才对(即max_trx_id)。
3.这个数据是由id=300的事务创建的,说明在我们本次事务过程中,又有很多的事务被开启了,
而这条数据就是后续开启的事务创建的
4.那这个id=300的事务 是否提交了呢。有未提交和已提交两种情况。虽然我们快照中记录了系统中
活跃的事务ids,但是记录的都是 生成快照那一时刻的事务,之后开启的事务 不会记录到快照中的。
所以我们没有办法判断300的事务是否已经提交,不过没有关系,因为无论是否提交,这条数据
我们都不用。因为这样就解决了 不可重复读的问题。下边解释
假设 有事务A和事务B。
1.事务A先开启,此时事务B没有开启。
2.事务A分配的事务id=179,并进行查询。查询id=10的用户名称,并查到了用户是张三
3.此时事务B开启了,并分配了事务id=300,他将用户名称改成了李四,并可能提交了事务。
4.事务A再去查id=10的事务,发现最新的数据上记录的事务id=300。如果我们不考虑情况五的判断
那么这次查询就会返回 name=李四。有没有发现,事务A两次查询后 名称不一样了,这不就是
不可重复读了么。所以避免不可重复读。我们根本不考虑 你事务B有没有提交,这条记录就是不符合
我们的需要
情况二
数据本身记录的事务id 在min和max之间。
说明了啥,说明 我们创建快照时,这条数据可能正在生成。这时候 trx_ids 就发挥作用了。
- 如果这条数据的事务id=166。我们发现ids[100,150,179]中 活跃的事务里没有这个166的事务,说明创建快照时,这个166的事务已经提交了。ok,这条数据可以。
- 如果这条数据的事务id=150,我们发现ids[100,150,179]中 活跃的事务里 发现了 这个150的事务,说明创建快照时,那时那刻,这个150的事务还没有提交,no!no!no!这条记录不能要。
情况四
其实和情况二是一样的。
情况三
创建快照的事务id和这条数据的事务id是一样的。这咋回事,说明遇到亲人了,这个数据就是我创建出来的,哪怕我没有提交,我也可以用这个数据。就比如我们在一个事务中插入了一条 名称叫 王霸的用户数据,insert之后,我们再select查询,是可以查到的。就是因为王霸身上的事务id 在select 查询时生成的快照中记录的事务id是一样的。但是此时此刻,其他事务是读不到的。
还记得上方说的每个数据身上都有个指针指向下一个版本么(roll_pointer),如果上述五种情况(实际是4种)中任一个情况 没有通过的话,就去找这个数据的上一个版本,然后递归判断。
幻读
最后才提到这个,本质上和不可重复读是一样的道理。都是在同一个事务中多次查询,却得到了不同的结果。概念上幻读是第二次读取时 多了一些数据。
`从上方MVCC可以看出,其实【可重复读】这个隔离级别已经解决了脏读、不可重复读的情况。
为什么说MVCC不能解决幻读问题
哪些情况是可能发生幻读的呢
- 无论是读还是写都开启了事务,无论你是在navicat上写了begin,还是在spring项目里使用@Transaction注解,如果你的读事务没有开启事务的话,会发生幻读的,但不会发生脏读
- 如果开启了事务,第一次读取数据是:
selelct * from table
而第二次使用了当前读 就是:
select * from table for update
这种的,如果另外一个事务在两条语句之间插入了一条数据,并且提交了事务,那么第二条语句也会发生幻读。这时其实第二条语句就没有采用mvcc的机制去读取数据了。 - 这种情况等同与第二种情况,就是
| 序号 | 事务一 | 事务二 |
|---|---|---|
| 1 | BEGIN | |
| 2 | BEGIN | |
| 3 | select * from user | |
| 4 | insert user value(7,“张三”,18) | |
| 5 | COMMIT | |
| 6 | UPDATE user set age=100 where id=7 | |
| 7 | select * from user |
在第6步时,使用update去更新,这时 读到id=7的数据,这个数据是事务二创建的,然后在这条记录的基础上生成了一个 trx_id=事务一的新纪录(即:age=100)
所以在第7步时 就读到了之前 所没有的 id=7的记录,这就发生了幻读。
结束语
无















 1118
1118











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









