







 本文深入解析深度学习中Linear层的数学表达式,通过详细解释单个样本的前向传播过程,阐述PyTorch中nn.Linear函数的工作原理。文章对比了矩阵表达与逐元素表达的区别,强调了batch训练中权重矩阵转置的重要性。
本文深入解析深度学习中Linear层的数学表达式,通过详细解释单个样本的前向传播过程,阐述PyTorch中nn.Linear函数的工作原理。文章对比了矩阵表达与逐元素表达的区别,强调了batch训练中权重矩阵转置的重要性。
Linear层的理解
单个sample的Linear数学表达式
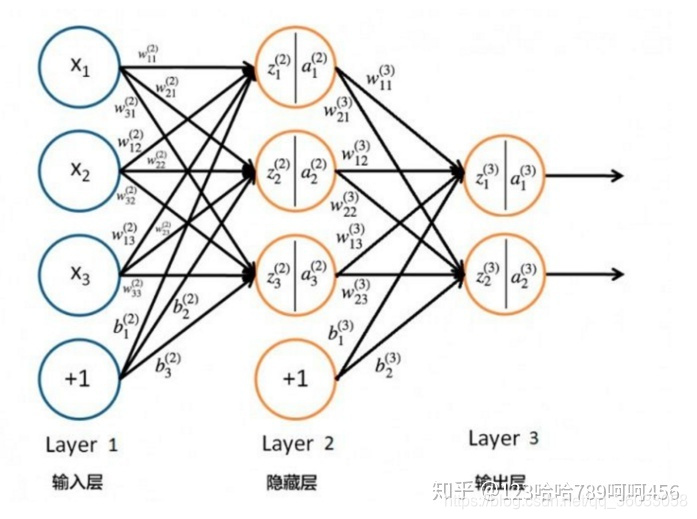
上图是前向传播的一个简单示例图。首先说明下该图中各个数学符号的含义:
X
X
X:单个sample的向量表达;
x
i
x_i
xi:输入sample向量的第
i
i
i维;
W
(
l
)
W^{(l)}
W(l):
L
a
y
e
r
l
−
1
Layer_{l-1}
Layerl−1到
L
a
y
e
r
l
Layer_{l}
Layerl的前向传播权重矩阵;
w
i
j
(
l
)
w_{ij}^{(l)}
wij(l):权重矩阵
W
(
l
)
W^{(l)}
W(l)的元素,
j
{j}
j表示
L
a
y
e
r
l
−
1
Layer_{l-1}
Layerl−1中第
j
j
j个元素,
i
i
i表示
L
a
y
e
r
l
Layer_{l}
Layerl中第
i
i
i个元素,
w
i
j
w_{ij}
wij表示
j
j
j到
i
i
i的连接权重;
Z
(
l
)
Z^{(l)}
Z(l):
L
a
y
e
r
l
Layer_l
Layerl接受到的刺激信号向量;
z
i
(
l
)
z_i^{(l)}
zi(l):
L
a
y
e
r
l
Layer_l
Layerl接受到的刺激信号向量中的第
i
i
i个值;
A
(
l
)
A^{(l)}
A(l):
L
a
y
e
r
l
Layer_l
Layerl的激活值向量;
a
i
(
l
)
a_i^{(l)}
ai(l):
L
a
y
e
r
l
Layer_l
Layerl对应
z
i
(
l
)
z_i^{(l)}
zi(l)的激活值;
这里主要写一下Layer 1到Layer 2的前向传播数学表达式:
z
1
(
2
)
=
w
11
(
2
)
x
1
+
w
12
(
2
)
x
2
+
w
13
(
2
)
x
3
z
2
(
2
)
=
w
21
(
2
)
x
1
+
w
22
(
2
)
x
2
+
w
23
(
2
)
x
3
z
3
(
2
)
=
w
31
(
2
)
x
1
+
w
32
(
2
)
x
2
+
w
33
(
2
)
x
3
z_1^{(2)}=w_{11}^{(2)}x_1+w_{12}^{(2)}x_2+w_{13}^{(2)}x_3 \\ z_2^{(2)}=w_{21}^{(2)}x_1+w_{22}^{(2)}x_2+w_{23}^{(2)}x_3 \\ z_3^{(2)}=w_{31}^{(2)}x_1+w_{32}^{(2)}x_2+w_{33}^{(2)}x_3
z1(2)=w11(2)x1+w12(2)x2+w13(2)x3z2(2)=w21(2)x1+w22(2)x2+w23(2)x3z3(2)=w31(2)x1+w32(2)x2+w33(2)x3
在深度学习中,这样的表达式过于繁琐,通常使用矩阵来进行简洁的表达。上述表达式的矩阵表达为:
[
z
1
(
2
)
z
2
(
2
)
z
3
(
2
)
]
=
[
w
11
(
2
)
w
12
(
2
)
w
13
(
2
)
w
21
(
2
)
w
22
(
2
)
w
23
(
2
)
w
31
(
2
)
w
32
(
2
)
w
33
(
2
)
]
[
x
1
x
2
x
3
]
+
[
b
1
(
2
)
b
2
(
2
)
b
3
(
3
)
]
(1)
\left[ \begin{matrix} z_1^{(2)} \\ z_2^{(2)} \\ z_3^{(2)} \end{matrix} \right]=\left[ \begin{matrix} w_{11}^{(2)} & w_{12}^{(2)} & w_{13}^{(2)} \\ w_{21}^{(2)} & w_{22}^{(2)} & w_{23}^{(2)} \\ w_{31}^{(2)} & w_{32}^{(2)} & w_{33}^{(2)} \end{matrix} \right]\left[ \begin{matrix} x_1 \\ x_2 \\ x_3 \end{matrix} \right]+\left[ \begin{matrix} b_1^{(2)} \\ b_2^{(2)} \\ b_3^{(3)} \end{matrix} \right] \tag{1}
⎣⎢⎡z1(2)z2(2)z3(2)⎦⎥⎤=⎣⎢⎡w11(2)w21(2)w31(2)w12(2)w22(2)w32(2)w13(2)w23(2)w33(2)⎦⎥⎤⎣⎡x1x2x3⎦⎤+⎣⎢⎡b1(2)b2(2)b3(3)⎦⎥⎤(1)
Z
(
l
)
=
W
(
l
)
X
+
B
(
l
)
(2)
Z^{(l)}=W^{(l)}X+B^{(l)}\tag{2}
Z(l)=W(l)X+B(l)(2)
公式(2)中的
Z
(
l
)
Z^{(l)}
Z(l)和
X
X
X都是列向量。
pytorch nn.Linear
torch.nn.Linear(in_features, out_features, bias=True)
官方文档的注释:
Applies a linear transformation to the incoming data:
y
=
x
A
T
+
b
y=xA^T+b
y=xAT+b
对比公式(2),可以发现
A
A
A其实就是
W
W
W,但是两者的表达还是有些不同的。
个人理解:公式(2)是针对单个sample的数学推导,其中单个sample是以列向量的形式表达的,但是在神经网络的训练中一般是使用batch train,这个时候就要使用sample matrix了。
x
x
x表示sample matrix,矩阵的每一行表示一个sample,即
x
x
x的size为
b
a
t
c
h
s
i
z
e
∗
i
n
_
f
e
a
t
u
r
e
s
batchsize*in\_features
batchsize∗in_features,
i
n
_
f
e
a
t
u
r
e
s
in\_features
in_features表示上一层的输出维度。
y
y
y的size为
b
a
t
c
h
_
s
i
z
e
∗
o
u
t
_
f
e
a
t
u
r
e
s
batch\_size*out\_features
batch_size∗out_features,
o
u
t
_
f
e
a
t
u
r
e
s
out\_features
out_features表示该层的输出维度,即该层的隐藏神经元个数。单个sample时,我们用列向量来表示sample,但是在sample matrix时,我们有行向量表示一个sample,所以矩阵
A
A
A需要转置。
b
a
t
c
h
_
s
i
z
e
∗
i
n
_
f
e
a
t
u
r
e
s
∗
i
n
_
f
e
a
t
u
r
e
s
∗
o
u
t
_
f
e
a
t
u
r
e
s
=
b
a
t
c
h
_
s
i
z
e
∗
o
u
t
_
f
e
a
t
u
r
e
s
batch\_size*in\_features*in\_features*out\_features=batch\_size*out\_features
batch_size∗in_features∗in_features∗out_features=batch_size∗out_features
矩阵
A
A
A的维度是
o
u
t
_
f
e
a
t
u
r
e
s
∗
i
n
_
f
e
a
t
u
r
e
s
out\_features*in\_features
out_features∗in_features,这和
W
W
W的形式是相同的。
之所以要转置,估计是因为batch train的原因。

关于shape的理解:
对于二维sample matrix,
∗
*
∗表示batch_size,三维sample matrix,N可以理解为channel;不管有多少维,理解的时候从最后一维开始理解,最后一维表示一个样本的维度,前一维表示多少个样本,最后两维表示构成一个sample matrix;再往前一维表示有多少个这样的sample matrix;更多的维度按照这样的方式去理解就比较容易了。
#preference:
1、https://zhuanlan.zhihu.com/p/71892752
2、https://pytorch.org/docs/stable/nn.html#linear-layers


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









