







来源:韦玮老师课堂笔记
上节作业讲解 爬取千图网的高清图片
www.58pic.com/haibaomoban1、分析网址结构,
http://www.58pic.com/piccate/3-151-0.html
http://www.58pic.com/piccate/3-151-0-02.html
http://www.58pic.com/piccate/3-151-0-03.html
2、以一个或两个为例来发现规律
http://pic.qiantucdn.com/58pic/25/98/25/68W58PIC7Cy.jpg!qt290
缩略图在源码中
http://pic.qiantucdn.com/58pic/25/98/25/68W58PIC7Cy_1024.jpg!/fw/780/watermark/url/L3dhdGVybWFyay12MS4zLnBuZw==/align/center
大图在网页点击后复制得到
分析二者网址的区别
舍去大图jpg!后的所有字符。 缩略图网址_1024.jpg
import urllib.request
import re
import urllib.error
for i in range(1,10):
pageurl="http://www.58pic.com/haibaomoban/0/id-"+str(i)+".html"
data=urllib.request.urlopen(pageurl).read().decode("utf-8","ignore")
pat='<a class="thumb-box".*?src="(.*?).jpg!'
imglist=re.compile(pat).findall(data)
for j in range(0,len(imglist)):
try:
thisimg=imglist[j]
thisimgurl=thisimg+"_1024.jpg"
file="F:/天善-Python数据分析与挖掘课程/result/32/"+str(i)+str
(j)+".jpg"
urllib.request.urlretrieve(thisimgurl,filename=file)
print("第"+str(i)+"页第"+str(j)+"个图片爬取成功")
except urllib.error.URLError as e:
if hasattr(e,"code"):
print(e.code)
if hasattr(e,"reason"):
print(e.reason)
except Exception as e:
print(e)2通过代理服务器去爬
抓包分析实战——网页源码中无法得到
例如淘宝网评论信息,腾讯视频评论信息
抓包分析概述
即将网络传输发送与接收的数据包进行抓取的操作,做爬虫时,数据不一定在HTML源码中,很可能隐藏在一些网址中,所以我们需要抓包,分析出对应数据所隐藏在的网址,然后分析规律并爬取
使用Fiddler进行抓包——安装
火狐—>高级—>代理,手动配置代理,http代理 127.0.0.1 8888端口
将fiddler作为代理服务器,数据通过f发送,网络服务器将数据发给fiddler,
https://ask.hellobi.com/blog/weiwei/5159
抓取淘宝的评论文字和图片——网页重新刷新,得到评论的话代表数据包已经传送,检查textview
评论的url->url里的代码——运用小图得到大图的地址的思维->构造网址
构造网址方法->经验/删除进行网址测试
抓取HTTP数据包
爬取腾讯视频的评论--小项目
难点:自动加载,查看更多。
查看页面源代码——看评论是不是在源代码中,否则抓包clear->查看更多->触发评论,得到数据包JS->得到unicode编的网页
腾讯视频的评论抓取——构造思想,代码复用
点击加载更多->触发数据包的传送,fiddler接收->抓到js,得到评论地址,信息
源源不断得到更多的评论地址
找出网址规律——>不停加载“查看更多”
https://video.coral.qq.com/varticle/2439088723/comment/v2?callback=_varticle2439088723commentv2&orinum=10&oriorder=o&pageflag=1&cursor=6372084213407708330&scorecursor=0&orirepnum=2&reporder=o&reppageflag=1&source=9&_=1519312862047
https://video.coral.qq.com/varticle/2439088723/comment/v2?callback=_varticle2439088723commentv2&orinum=10&oriorder=o&pageflag=1&cursor=6372084213407708330&scorecursor=0&orirepnum=2&reporder=o&reppageflag=1&source=9&_=1519312862047
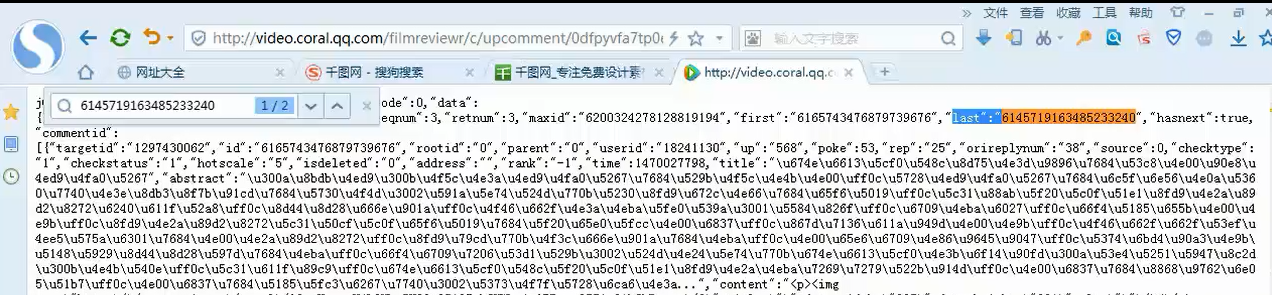
commentid=6372084213407708330 通过last得到commentid的值。实现方法:测试不同的参数在原网页中,看是否存在,从而改变其参数进行下一个网页的爬取
print(u'unicode代码’) 得到中文表达式
title评论标记 content评论内容进行提取
将unicode转化为普通python字符串 encode("utf-8","ascii","iso-8859-1")
将普通python字符串转化为unicode decode(string,"utf-8")
eval() 函数用来执行一个字符串表达式,并返回表达式的值。
x=7
eval('3*x')
结果21
筛选,去除网页标签——利用正则表达式
尝试一段时间没有反应——考虑是不是url问题?也有可能是网络问题
control+c终止python运行
代码 1导入包 2伪装成浏览器 3构造地址
import urllib.request
import re
import urllib.error
headers=("User-Agent","Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.22 Safari/537.36 SE 2.X MetaSr 1.0")
opener=urllib.request.build_opener()
opener.addheaders=[headers]
urllib.request.install_opener(opener)
comid="6165793094371986503"
url="http://video.coral.qq.com/filmreviewr/c/upcomment/0dfpyvfa7tp0ewe?commentid="+comid+"&reqnum=3&callback=jQuery1120026430801920245595_1478436999932&_=1478436999935"
for i in range(0,100):
data=urllib.request.urlopen(url).read().decode()
patnext='"last":"(.*?)"'
nextid=re.compile(patnext).findall(data)[0]
patcom='"content":"(.*?)",'
comdata=re.compile(patcom).findall(data)
for j in range(0,len(comdata)):
print("------第"+str(i)+str(j)+"条评论内容是:")
print(eval('u"'+comdata[j]+'"'))
url="http://video.coral.qq.com/filmreviewr/c/upcomment/0dfpyvfa7tp0ewe?commentid="+nextid+"&reqnum=3&callback=jQuery1120026430801920245595_1478436999932&_=1478436999935"微信爬虫实战——反爬破解
多线程爬虫——并行执行,大大提高程序运行效率
多线程爬虫实战
概念
糗事百科段子爬虫
1分析网页结构
https://www.qiushibaike.com/8hr/page/3/
https://www.qiushibaike.com/8hr/page/2/
2 所有内容都在 <div class="content"> <span> </span> </div>
设置pat的内容
3改为多线程爬虫
设置线程
import threading
class A(threading.Thread):设置为线程
#至少有两个方法
def__init__(self):
#初始化线程
threading.Thread.__init__(self)
def run(self):
for i in range(0,10,2):增量为2
print("我是线程A")
开启线程
t1=A()
t1.start()开启线程
t2=B()
t2.start()#线程A,B交叉执行
4异常处理的重要性
单线程,50多s
多线程,44s
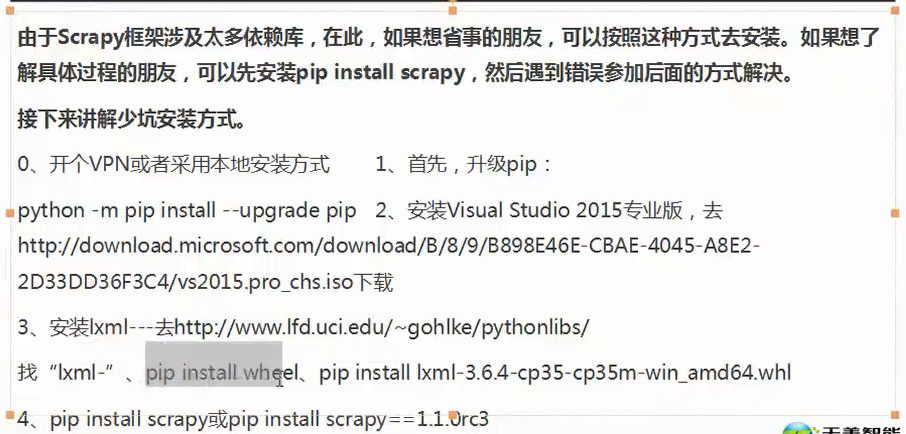
scrapy框架安装,适合做大型爬虫项目,不必过多关注细节
urllib是个基础,框架底层
省事安装方法:
开VPN否则很容易发生超时
scrapy框架——大型爬虫必备,安装方法















 61万+
61万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









