







环境:
hudi 0.10.1
spark 2.4.5
hive 2.3.7
hadoop 2.7.5
将编译好的hudi jar, copy到hive lib目录下:
cp /Users/xxx/cloudera/lib/hudi/packaging/hudi-hadoop-mr-bundle/target/hudi-hadoop-mr-bundle-0.11.0-SNAPSHOT.jar ~/cloudera/cdh5.7/hive/lib/
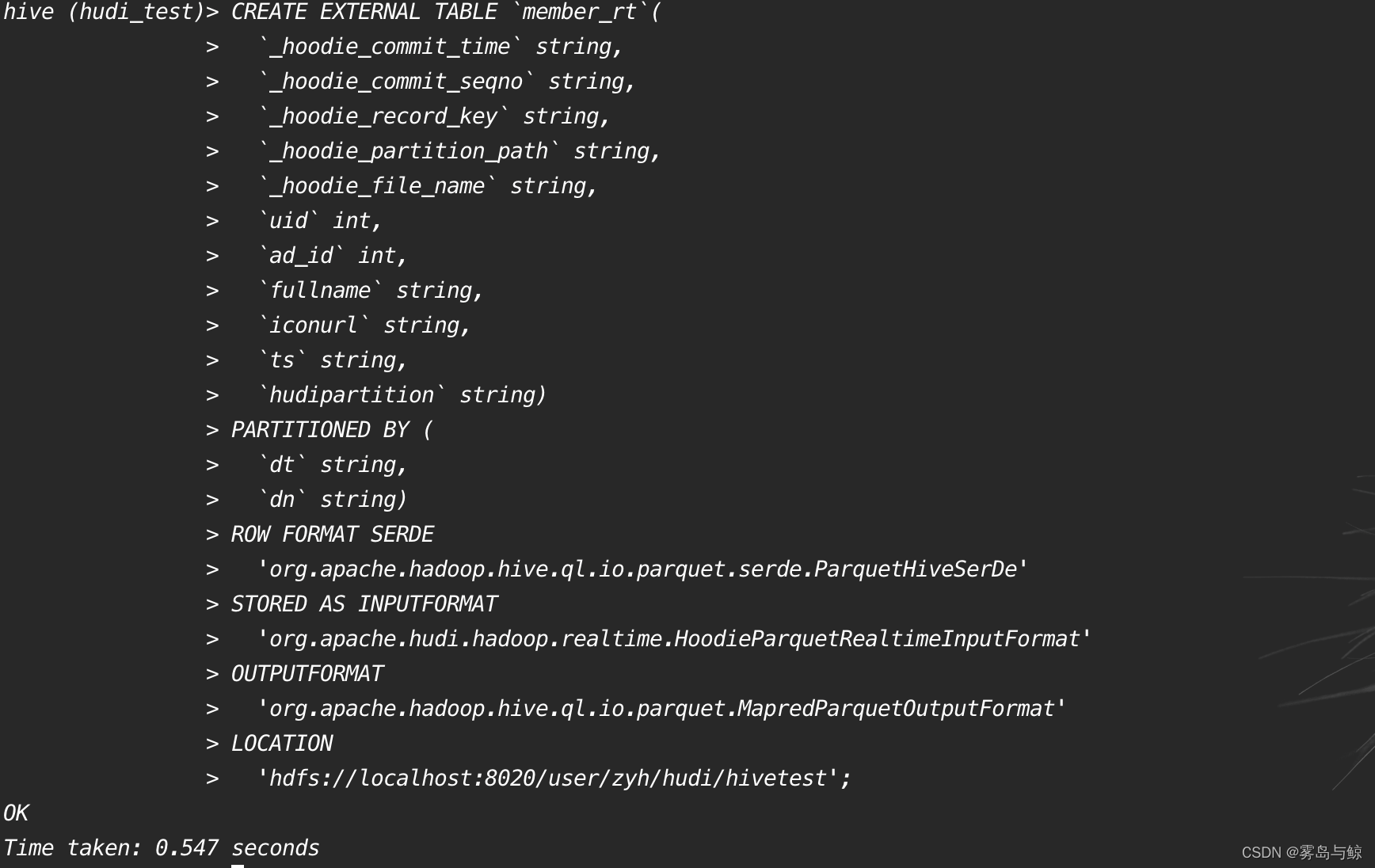
1、建表并插入数据
hudi会自动创建表,也可以提前建表:
CREATE EXTERNAL TABLE `member_rt`(
`_hoodie_commit_time` string,
`_hoodie_commit_seqno` string,
`_hoodie_record_key` string,
`_hoodie_partition_path` string,
`_hoodie_file_name` string,
`uid` int,
`ad_id` int,
`fullname` string,
`iconurl` string,
`ts` string,
`hudipartition` string)
PARTITIONED BY (
`dt` string,
`dn` string)
ROW FORMAT SERDE
'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe'
STORED AS INPUTFORMAT
'org.apache.hudi.hadoop.realtime.HoodieParquetRealtimeInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat'
LOCATION
'hdfs://localhost:8020/user/zyh/hudi/hivetest';
测试写数据
import com.google.gson.Gson
import com.zyh.bean.DwsMember
import org.apache.hudi.DataSourceWriteOptions
import org.apache.hudi.config.HoodieIndexConfig
import org.apache.hudi.hive.MultiPartKeysValueExtractor
import org.apache.hudi.index.HoodieIndex
import org.apache.spark.sql.{SaveMode, SparkSession}
object HudiTestHive {
def main(args: Array[String]): Unit = {
val sparkSession = SparkSession
.builder()
.appName("dwd_member_import")
.master("local[*]")
.config("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
.enableHiveSupport()
.getOrCreate()
val ssc = sparkSession.sparkContext
ssc.hadoopConfiguration.set("fs.defaultFS", "hdfs://localhost:8020")
ssc.hadoopConfiguration.set("dfs.nameservices", "localhost")
import org.apache.spark.sql.functions._
import sparkSession.implicits._
val commitTime = System.currentTimeMillis().toString //生成提交时间
val df = sparkSession.read.text("/user/test/ods/member.log")
.mapPartitions(partitions => {
val gson = new Gson
partitions.map(item => {
gson.fromJson(item.getString(0), classOf[DwsMember])
})
})
.withColumn("ts", lit(commitTime))
.withColumn("hudipartition", concat_ws("/", col("dt"), col("dn")))
Class.forName("org.apache.hive.jdbc.HiveDriver");
df.write.format("org.apache.hudi")
.option(DataSourceWriteOptions.TABLE_TYPE_OPT_KEY, DataSourceWriteOptions.MOR_TABLE_TYPE_OPT_VAL) //选择表的类型 到底是MERGE_ON_READ 还是 COPY_ON_WRITE
.option(DataSourceWriteOptions.RECORDKEY_FIELD_OPT_KEY, "uid") //设置主键
.option(DataSourceWriteOptions.PRECOMBINE_FIELD_OPT_KEY, "ts") //数据更新时间戳的
.option(DataSourceWriteOptions.PARTITIONPATH_FIELD_OPT_KEY, "hudipartition") //hudi分区列
.option("hoodie.table.name", "member") //hudi表名
.option(DataSourceWriteOptions.HIVE_URL_OPT_KEY, "jdbc:hive2://localhost:10000") //hiveserver2地址
.option(DataSourceWriteOptions.HIVE_DATABASE_OPT_KEY, "hudi_test") //设置hudi与hive同步的数据库
.option(DataSourceWriteOptions.HIVE_TABLE_OPT_KEY, "member") //设置hudi与hive同步的表名, 这个名字不需要和hive外部表表名一致
.option(DataSourceWriteOptions.HIVE_PARTITION_FIELDS_OPT_KEY, "dt,dn") //hive表同步的分区列
.option(DataSourceWriteOptions.HIVE_PARTITION_EXTRACTOR_CLASS_OPT_KEY, classOf[MultiPartKeysValueExtractor].getName) // 分区提取器 按/ 提取分区
.option(DataSourceWriteOptions.HIVE_SYNC_ENABLED_OPT_KEY, "true") //设置数据集注册并同步到hive
.option(HoodieIndexConfig.BLOOM_INDEX_UPDATE_PARTITION_PATH, "true") //设置当分区变更时,当前数据的分区目录是否变更
.option(HoodieIndexConfig.INDEX_TYPE_PROP, HoodieIndex.IndexType.GLOBAL_BLOOM.name()) //设置索引类型目前有HBASE,INMEMORY,BLOOM,GLOBAL_BLOOM 四种索引 为了保证分区变更后能找到必须设置全局GLOBAL_BLOOM
.option("hoodie.insert.shuffle.parallelism", "12")
.option("hoodie.upsert.shuffle.parallelism", "12")
.mode(SaveMode.Append)
.save("/user/zyh/hudi/hivetest")
}
}
查询表数据:
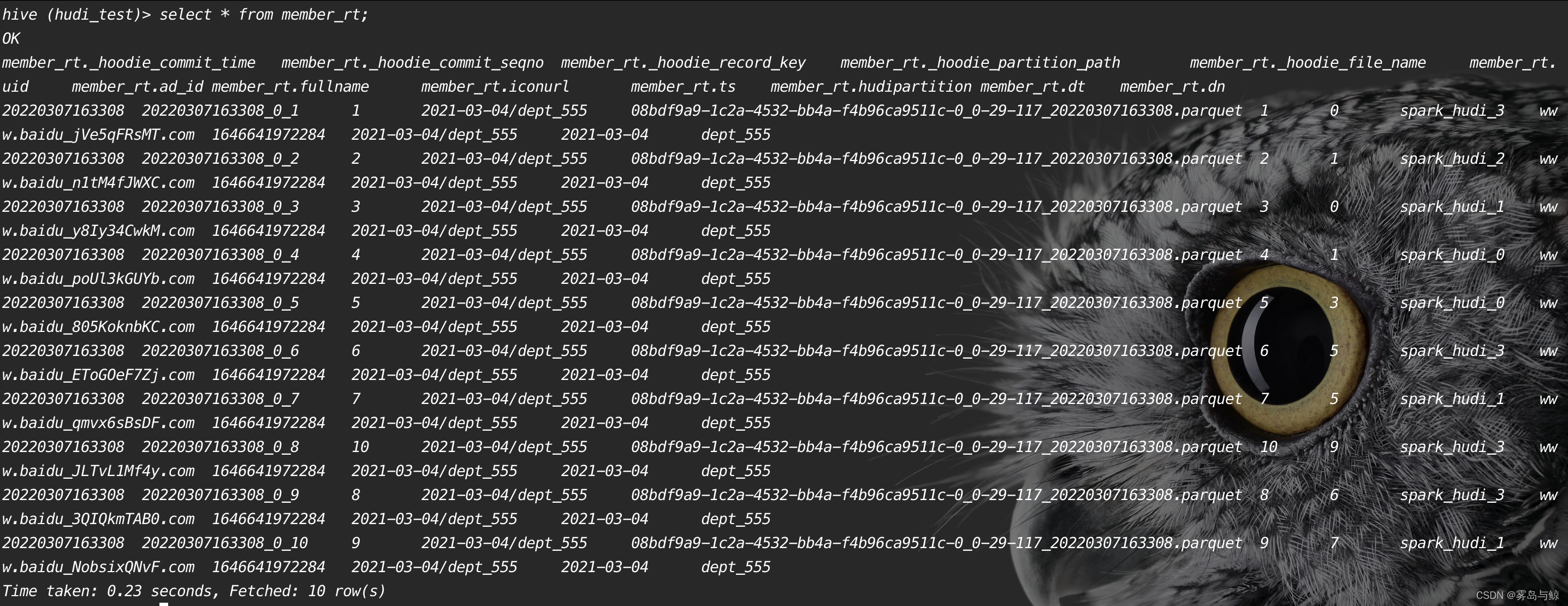
Hudi集成hive, 即Hudi同步数据到hive, 供hive查询
2、表类型对比
针对copy_on_write表和merge_on_read表同时生成两份表数据,读取member日志数据各自生成两种类型的表
object HudiTestHiveForTableType {
def main(args: Array[String]): Unit = {
System.setProperty("HADOOP_USER_NAME", "zhangyunhao")
val sparkSession = SparkSession
.builder()
.appName("dwd_member_import")
.master("local[*]")
.config("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
.enableHiveSupport()
.getOrCreate()
val ssc = sparkSession.sparkContext
ssc.hadoopConfiguration.set("fs.defaultFS", "hdfs://localhost:8020")
ssc.hadoopConfiguration.set("dfs.nameservices", "localhost")
generateData(sparkSession)
// queryData(sparkSession)
// updateData(sparkSession)
// queryData(sparkSession)
}
def generateData(sparkSession: SparkSession) = {
import org.apache.spark.sql.functions._
import sparkSession.implicits._
val commitTime = System.currentTimeMillis().toString //生成提交时间
val df = sparkSession.read.text("/user/test/ods/member.log")
.mapPartitions(partitions => {
val gson = new Gson
partitions.map(item => {
gson.fromJson(item.getString(0), classOf[DwsMember])
})
}).withColumn("ts", lit(commitTime))
.withColumn("hudipartition", concat_ws("/", col("dt"), col("dn")))
// Merge_ON_READ建表时会自动创建两种视图 : member1_ro (读优化视图) / member1_rt (实时视图)
df.write.format("org.apache.hudi")
.option(DataSourceWriteOptions.TABLE_TYPE_OPT_KEY, DataSourceWriteOptions.MOR_TABLE_TYPE_OPT_VAL) //指定表类型为MERGE_ON_READ
.option("hoodie.insert.shuffle.parallelism", 12)
.option("hoodie.upsert.shuffle.parallelism", 12)
.option(DataSourceWriteOptions.RECORDKEY_FIELD_OPT_KEY, "uid") //指定记录键
.option(DataSourceWriteOptions.PRECOMBINE_FIELD_OPT_KEY, "ts") //数据更新时间戳的
.option(DataSourceWriteOptions.PARTITIONPATH_FIELD_OPT_KEY, "hudipartition") //hudi分区列
.option("hoodie.table.name", "hudimembertest1") //hudi表名
.option(DataSourceWriteOptions.HIVE_URL_OPT_KEY, "jdbc:hive2://localhost:10000") //hiveserver2地址
.option(DataSourceWriteOptions.HIVE_DATABASE_OPT_KEY, "hudi_test") //设置hudi与hive同步的数据库
.option(DataSourceWriteOptions.HIVE_TABLE_OPT_KEY, "member1") //设置hudi与hive同步的表名
.option(DataSourceWriteOptions.HIVE_PARTITION_FIELDS_OPT_KEY, "dt,dn") //hive表同步的分区列
.option(DataSourceWriteOptions.HIVE_PARTITION_EXTRACTOR_CLASS_OPT_KEY, classOf[MultiPartKeysValueExtractor].getName) // 分区提取器 按/ 提取分区
.option(DataSourceWriteOptions.HIVE_SYNC_ENABLED_OPT_KEY, "true") //设置数据集注册并同步到hive
.option(HoodieIndexConfig.BLOOM_INDEX_UPDATE_PARTITION_PATH, "true") //设置当分区变更时,当前数据的分区目录是否变更
.option(HoodieIndexConfig.INDEX_TYPE_PROP, HoodieIndex.IndexType.GLOBAL_BLOOM.name()) //设置索引类型目前有HBASE,INMEMORY,BLOOM,GLOBAL_BLOOM 四种索引 为了保证分区变更后能找到必须设置全局GLOBAL_BLOOM
.option("hoodie.insert.shuffle.parallelism", "12")
.option("hoodie.upsert.shuffle.parallelism", "12")
.mode(SaveMode.Overwrite)
.save("/user/zyh/hudi/hudimembertest1")
// COPY_ON_WRITE建表时只会自动创建读优化视图 : member2
df.write.format("org.apache.hudi")
.option(DataSourceWriteOptions.TABLE_TYPE_OPT_KEY, DataSourceWriteOptions.COW_TABLE_TYPE_OPT_VAL) //指定表类型为COPY_ON_WRITE
.option("hoodie.insert.shuffle.parallelism", 12)
.option("hoodie.upsert.shuffle.parallelism", 12)
.option(DataSourceWriteOptions.RECORDKEY_FIELD_OPT_KEY, "uid") //指定记录键
.option(DataSourceWriteOptions.PRECOMBINE_FIELD_OPT_KEY, "ts") //数据更新时间戳的
.option(DataSourceWriteOptions.PARTITIONPATH_FIELD_OPT_KEY, "hudipartition") //hudi分区列
.option("hoodie.table.name", "hudimembertest2") //hudi表名
.option(DataSourceWriteOptions.HIVE_URL_OPT_KEY, "jdbc:hive2://localhost:10000") //hiveserver2地址
.option(DataSourceWriteOptions.HIVE_DATABASE_OPT_KEY, "hudi_test") //设置hudi与hive同步的数据库
.option(DataSourceWriteOptions.HIVE_TABLE_OPT_KEY, "member2") //设置hudi与hive同步的表名
.option(DataSourceWriteOptions.HIVE_PARTITION_FIELDS_OPT_KEY, "dt,dn") //hive表同步的分区列
.option(DataSourceWriteOptions.HIVE_PARTITION_EXTRACTOR_CLASS_OPT_KEY, classOf[MultiPartKeysValueExtractor].getName) // 分区提取器 按/ 提取分区
.option(DataSourceWriteOptions.HIVE_SYNC_ENABLED_OPT_KEY, "true") //设置数据集注册并同步到hive
.option(HoodieIndexConfig.BLOOM_INDEX_UPDATE_PARTITION_PATH, "true") //设置当分区变更时,当前数据的分区目录是否变更
.option(HoodieIndexConfig.INDEX_TYPE_PROP, HoodieIndex.IndexType.GLOBAL_BLOOM.name()) //设置索引类型目前有HBASE,INMEMORY,BLOOM,GLOBAL_BLOOM 四种索引 为了保证分区变更后能找到必须设置全局GLOBAL_BLOOM
.option("hoodie.insert.shuffle.parallelism", "12")
.option("hoodie.upsert.shuffle.parallelism", "12")
.mode(SaveMode.Overwrite)
.save("/user/zyh/hudi/hudimembertest2")
}
}
查看hive,发现自动建好3张表,继续使用命令查看表结构

可以看到格式有两种HoodieParquetInputFormat和HoodieParquetRealtimeInputFormat,两种在hudi中是读优化视图和实时视图。
Merge_ON_READ建表时会自动创建两种视图,COPY_ON_WRITE建表时只会自动创建读优化视图。
查询表,都已同步数据。
3、修改数据
有了数据之后对表进行更新操作,对两张表分别只更新uid 0-9的10条数据, 将full_name 全部更改为testName
def updateData(sparkSession: SparkSession) = {
import org.apache.spark.sql.functions._
import sparkSession.implicits._
val commitTime = System.currentTimeMillis().toString //生成提交时间
val df = sparkSession.read.text("/user/test/ods/member2.log")
.mapPartitions(partitions => {
val gson = new Gson
partitions.map(item => {
gson.fromJson(item.getString(0), classOf[DwsMember])
})
}).where("uid>=0 and uid<=9")
val result = df.map(item => {
item.fullname = "testName" // 修改fullname为testName
item
}).withColumn("ts", lit(commitTime))
.withColumn("hudipartition", concat_ws("/", col("dt"), col("dn")))
// result.show()
result.write.format("org.apache.hudi")
.option("hoodie.insert.shuffle.parallelism", 12)
.option("hoodie.upsert.shuffle.parallelism", 12)
.option(DataSourceWriteOptions.RECORDKEY_FIELD_OPT_KEY, "uid") //指定记录键
.option(DataSourceWriteOptions.PRECOMBINE_FIELD_OPT_KEY, "ts") //数据更新时间戳的
.option(DataSourceWriteOptions.PARTITIONPATH_FIELD_OPT_KEY, "hudipartition") //hudi分区列
.option("hoodie.table.name", "hudimembertest1") //hudi表名1
.option(DataSourceWriteOptions.HIVE_URL_OPT_KEY, "jdbc:hive2://localhost:10000") //hiveserver2地址
.option(DataSourceWriteOptions.HIVE_DATABASE_OPT_KEY, "hudi_test") //设置hudi与hive同步的数据库
.option(DataSourceWriteOptions.HIVE_TABLE_OPT_KEY, "member1") //设置hudi与hive同步的表名
.option(DataSourceWriteOptions.HIVE_PARTITION_FIELDS_OPT_KEY, "dt,dn") //hive表同步的分区列
.option(DataSourceWriteOptions.HIVE_PARTITION_EXTRACTOR_CLASS_OPT_KEY, classOf[MultiPartKeysValueExtractor].getName) // 分区提取器 按/ 提取分区
.option(DataSourceWriteOptions.HIVE_SYNC_ENABLED_OPT_KEY, "true") //设置数据集注册并同步到hive
.option(HoodieIndexConfig.BLOOM_INDEX_UPDATE_PARTITION_PATH, "true") //设置当分区变更时,当前数据的分区目录是否变更
.option(HoodieIndexConfig.INDEX_TYPE_PROP, HoodieIndex.IndexType.GLOBAL_BLOOM.name()) //设置索引
.option("hoodie.insert.shuffle.parallelism", "12")
.option("hoodie.upsert.shuffle.parallelism", "12")
.mode(SaveMode.Append)
.save("/user/zyh/hudi/hudimembertest1")
result.write.format("org.apache.hudi")
.option("hoodie.insert.shuffle.parallelism", 12)
.option("hoodie.upsert.shuffle.parallelism", 12)
.option(DataSourceWriteOptions.RECORDKEY_FIELD_OPT_KEY, "uid") //指定记录键
.option(DataSourceWriteOptions.PRECOMBINE_FIELD_OPT_KEY, "ts") //数据更新时间戳的
.option(DataSourceWriteOptions.PARTITIONPATH_FIELD_OPT_KEY, "hudipartition") //hudi分区列
.option("hoodie.table.name", "hudimembertest2") //hudi表名
.option(DataSourceWriteOptions.HIVE_URL_OPT_KEY, "jdbc:hive2://localhost:10000") //hiveserver2地址
.option(DataSourceWriteOptions.HIVE_DATABASE_OPT_KEY, "hudi_test") //设置hudi与hive同步的数据库
.option(DataSourceWriteOptions.HIVE_TABLE_OPT_KEY, "member2") //设置hudi与hive同步的表名
.option(DataSourceWriteOptions.HIVE_PARTITION_FIELDS_OPT_KEY, "dt,dn") //hive表同步的分区列
.option(DataSourceWriteOptions.HIVE_PARTITION_EXTRACTOR_CLASS_OPT_KEY, classOf[MultiPartKeysValueExtractor].getName) // 分区提取器 按/ 提取分区
.option(DataSourceWriteOptions.HIVE_SYNC_ENABLED_OPT_KEY, "true") //设置数据集注册并同步到hive
.option(HoodieIndexConfig.BLOOM_INDEX_UPDATE_PARTITION_PATH, "true") //设置当分区变更时,当前数据的分区目录是否变更
.option(HoodieIndexConfig.INDEX_TYPE_PROP, HoodieIndex.IndexType.GLOBAL_BLOOM.name()) //设置索引
.option("hoodie.insert.shuffle.parallelism", "12")
.option("hoodie.upsert.shuffle.parallelism", "12")
.mode(SaveMode.Append)
.save("/user/zyh/hudi/hudimembertest2")
}
修改完毕后,查看对应hdfs路径下的文件变化
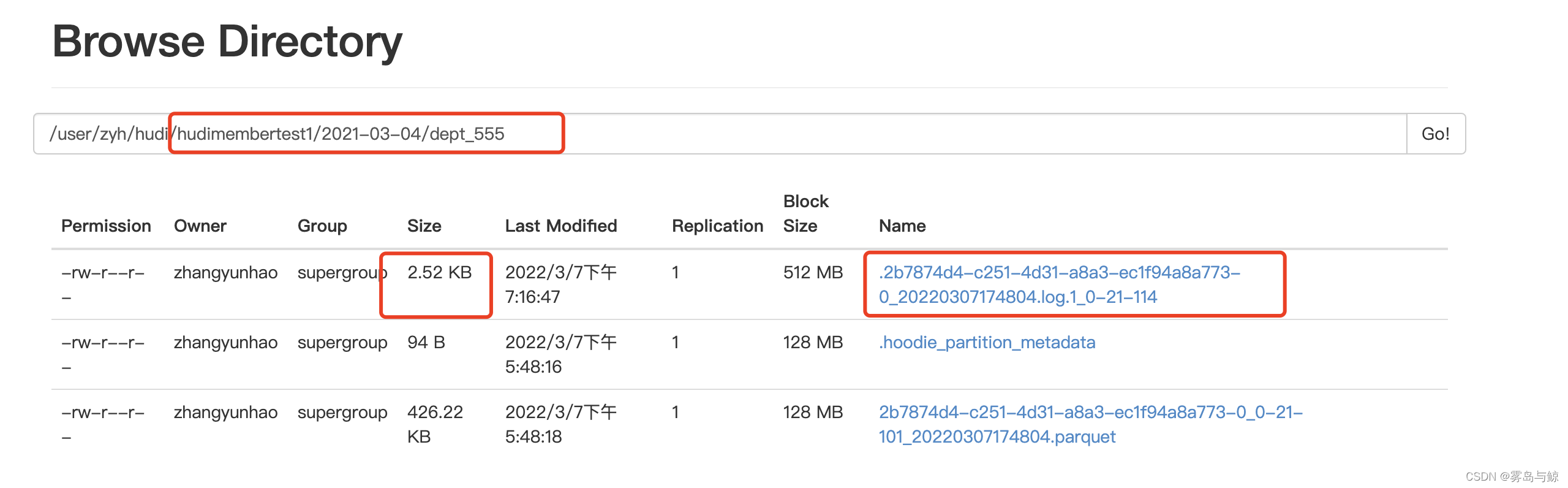
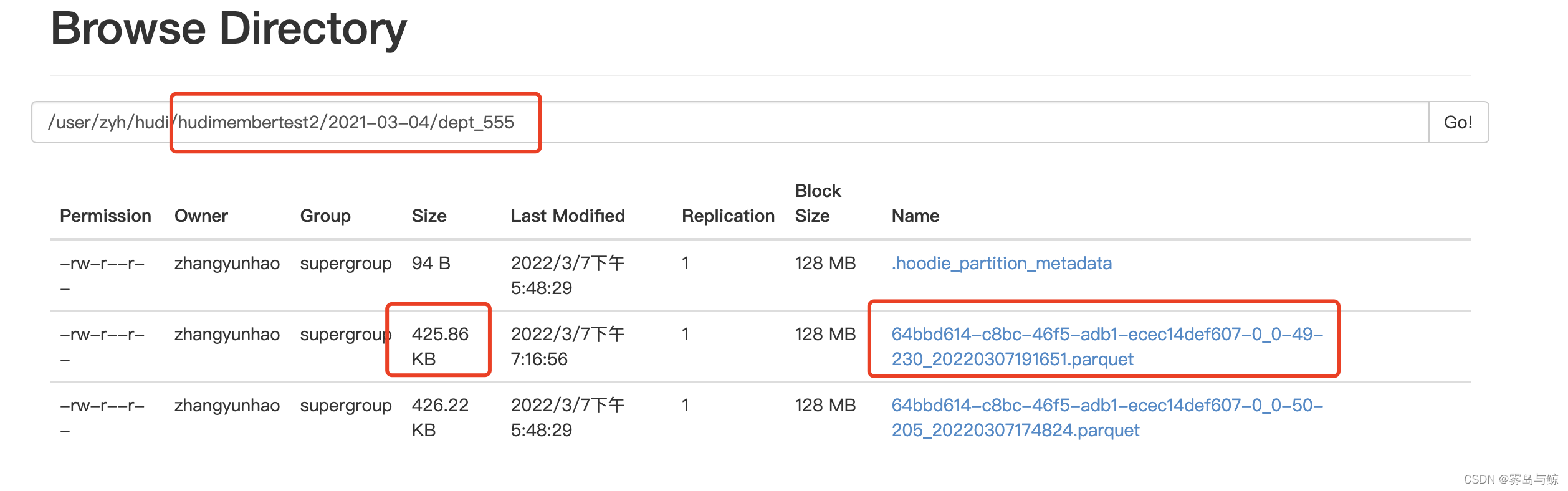
可以看到对于新增数据,Merger_On_Read(读时合并表)采用增量日志的方式修改数据,而Copy_On_Write(写实时表)采用了全量更新出一份全新文件方式进行修改功能。
两者对比

最后修改完毕之后,查询对应hive表
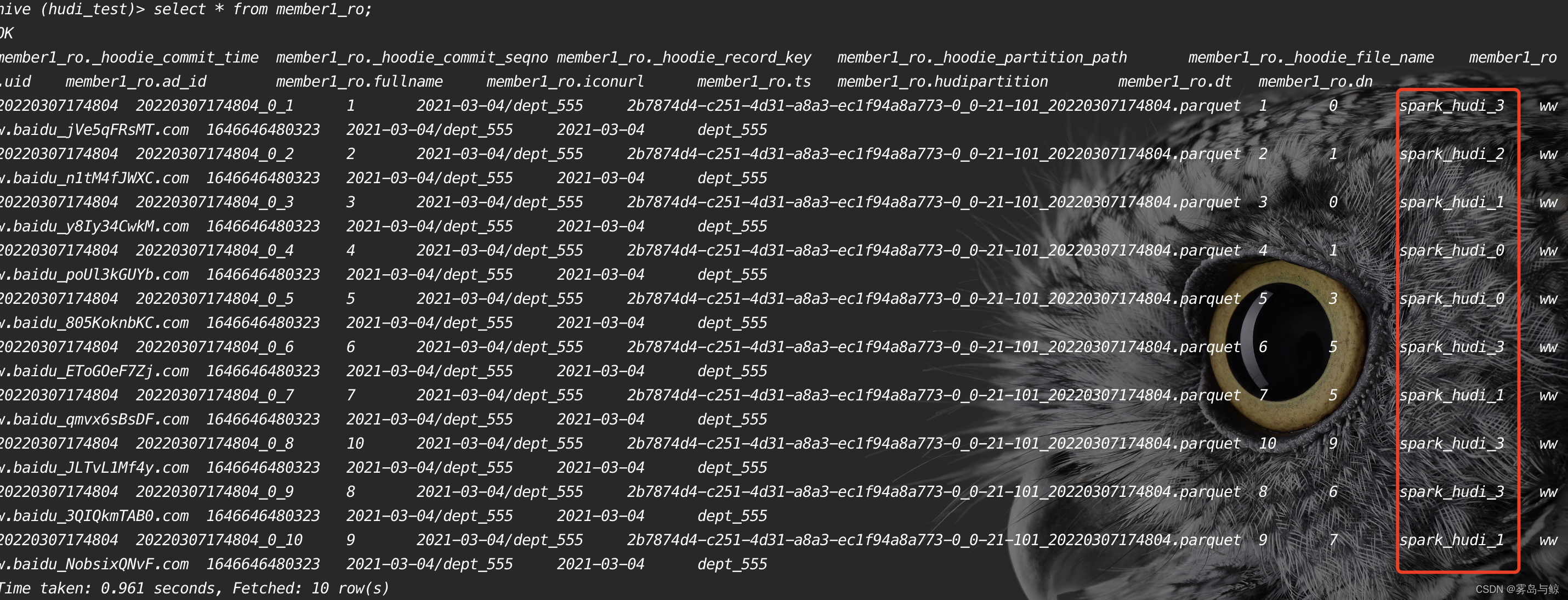
可以发现ro结尾的读优化视图没有发生变化。查询rt表
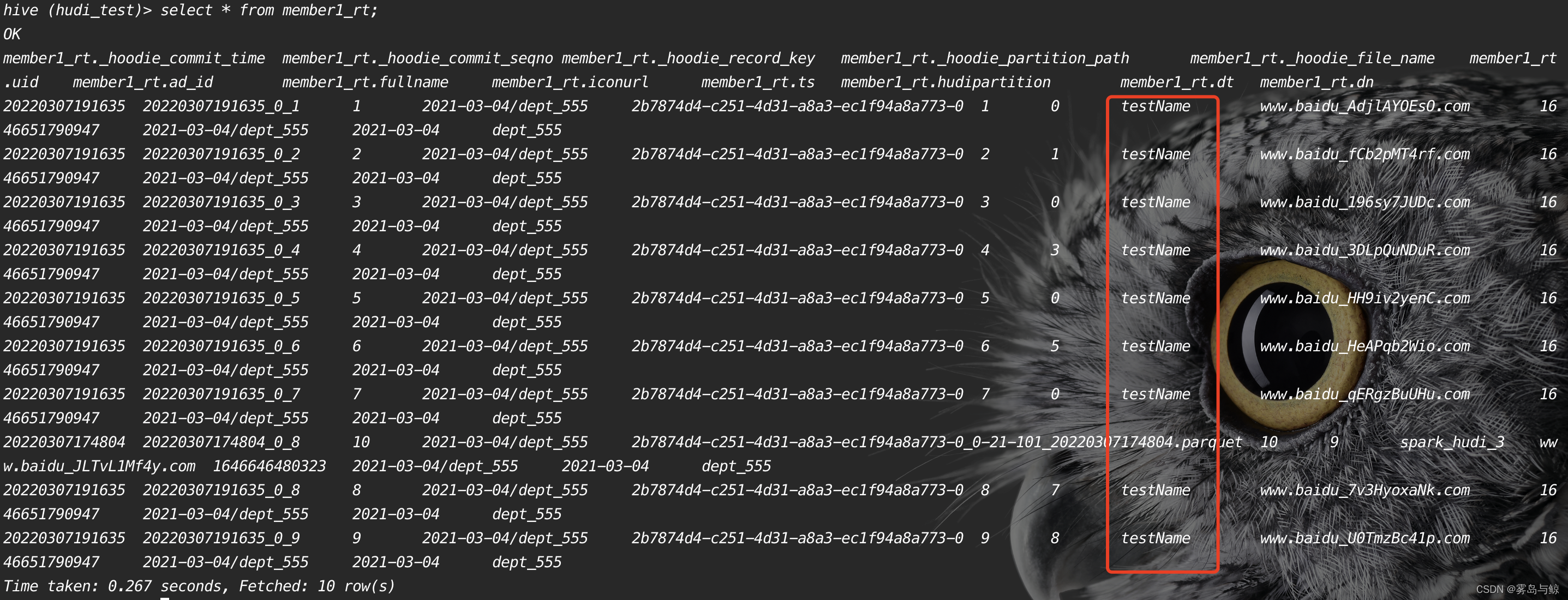
rt表的数据发生了变化,实时视图是查询基础数据和日志数据的合并视图。最后查询member2的实时视图
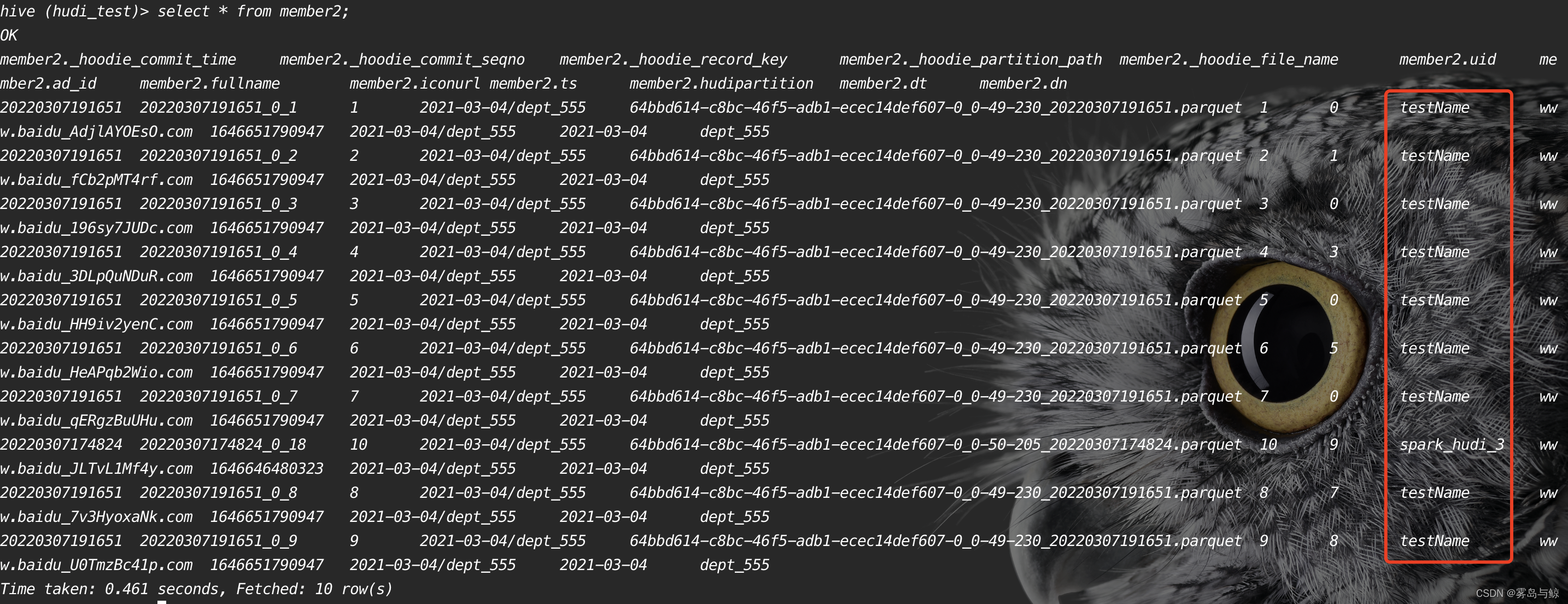
3、总结
由此可以理解为MERGE_ON_READ的表,是以增量的形式来记录表的数据,修改操作都以日志的形式保存。而COPY_ON_READ的表是以全量覆盖的方式进行保存数据,每次有修改操作那么会和历史数据重新合并生产一份新的数据文件,并且历史数据不会删除。
两种表视图,HoodieParquetInputFormat格式的只支持查询表的原始数据,HoodieParquetRealtimeInputFormat格式支持查询表和日志的合并视图提供最新的数据。
















 3555
3555











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











