







聚簇索引与非聚簇索引
聚簇索引和非聚簇索引是数据库中常用的两种索引类型,它们的区别在于索引的顺序是否与数据的物理存储顺序一致。
聚簇索引: 聚簇索引的顺序就是数据的物理存储顺序,因此每张表只能有一个聚簇索引。聚簇索引的优点是查询速度快,因为数据的物理存储顺序与索引顺序一致,可以减少磁盘I/O操作。但是聚簇索引的缺点是插入和更新数据时需要移动数据,因此会影响性能。
简单点理解就是将数据与索引放到了一起,找到索引也就找到了数据。也就是说,对于聚簇索引来说他的非叶子节点上存储的是索引字段的值,而他的叶子节点上存储的是这条记录的整行数据。
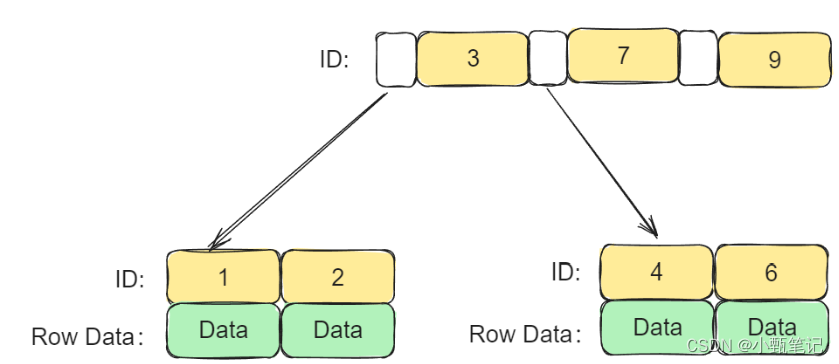
在InnoDB中,聚族索引 (Clustered lndex) 指的是按照每张表的主键构建的一种索引方式,它是将表数据按照主键的顺序存储在磁盘上的一种方式。这种索引方式保证了行的物理存储顺序与主键的逻辑顺序相同,因此查找聚簇索引的速度非常快
非聚簇索引: 非聚簇索引的索引顺序与数据物理排列顺序无关,因此每张表可以有多个非聚簇索引。非聚簇索引的优点是插入和更新数据时不需要移动数据,因此不会影响性能。但是查询速度相对较慢,因为需要先查找索引,再根据索引查找数据。
非聚簇索引就是将数据与索引分开存储,叶子节点包含索引字段值及指向数据页数据行的逻辑指针
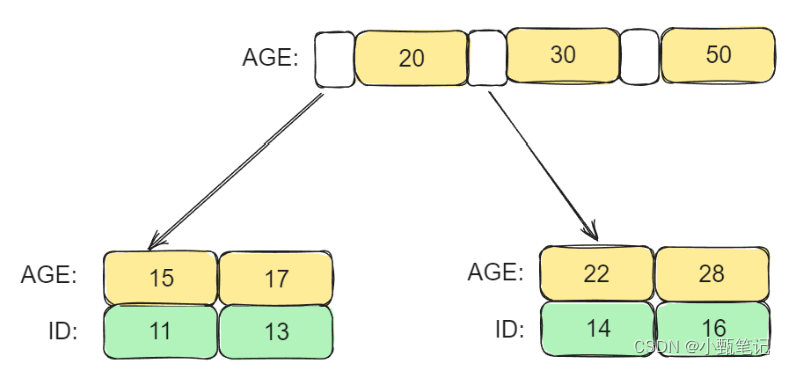
在InnoDB中,主键索引就是聚簇索引,而非主键索引,就是非聚簇索引,
所以在InnoDB中对于聚簇索引来说,他的非叶子节点上存储的是索引值,而它的叶子节点上存储的是整行记录
对于非聚簇索引来说,他的非叶子节点上存储的都是索引值,而它的叶子节点上存储的是主键的值.
所以,通过非聚簇索引的查询,需要进行一次回表,就是先查到主键ID,在通过ID查询所需字段
索引叶子节点和非叶子节点
MySQL中索引的叶子节点和非叶子节点存储的内容是不同的。具体来说,叶子节点包含索引和数据,而非叶子节点只存储索引不存储数据。叶子节点用指针连接起来,叶子节点包含全部索引值,而非叶子节点的索引值只是叶子节点的冗余。
在MySQL中,索引分为聚集索引和非聚集索引两种类型。聚集索引的数据文件只有数据结构文件.frm和数据文件.idb,其中.idb中存放的是数据和索引信息,是存放在一起的。而对于非聚集索引,表数据存储顺序与索引顺序无关。非聚集索引的叶节点存储的是索引值和指向对应数据行的指针,而非叶子节点存储的是索引值和指向下一级节点的指针。
因此,索引的叶子节点和非叶子节点存储的内容是不同的,具体存储的内容也与索引的类型有关。















 164
164











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









