




 本文档详细介绍了如何安装Kafka 3.0.0,包括下载、解压、配置server.properties、环境变量设置、启动脚本编写以及测试创建和使用topic的过程。
本文档详细介绍了如何安装Kafka 3.0.0,包括下载、解压、配置server.properties、环境变量设置、启动脚本编写以及测试创建和使用topic的过程。
1.下载
wget https://dlcdn.apache.org/kafka/3.0.0/kafka_2.12-3.0.0.tgz --no-check-certificate
2.解压并同步到其他节点
tar -zxvf kafka_2.12-3.0.0.tgz -C ../src
pscp -h /node.list -r kafka_2.12-3.0.0 /opt/src/
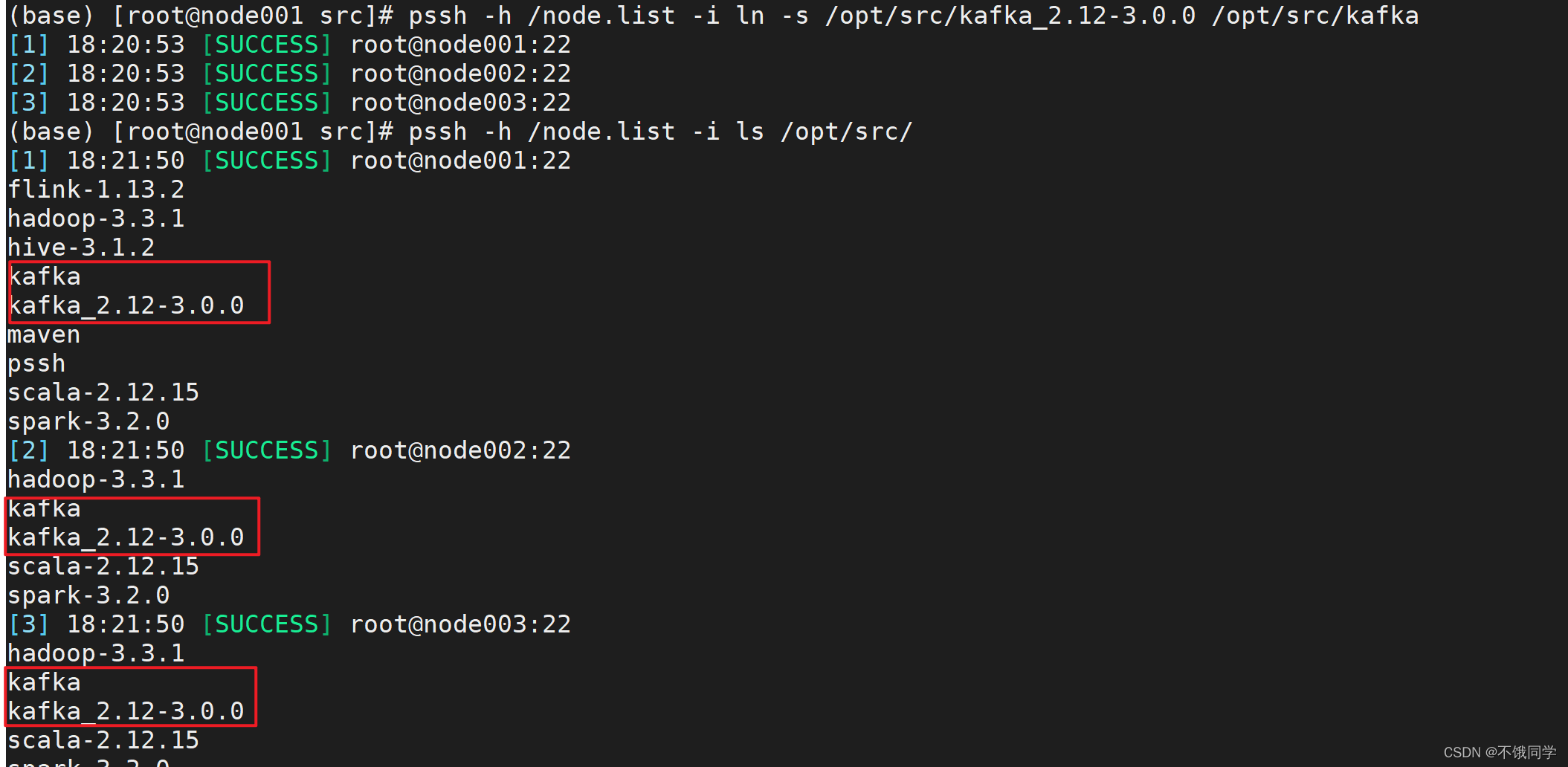
pssh -h /node.list -i ls /opt/src/
pssh -h /node.list -i ln -s /opt/src/kafka_2.12-3.0.0 /opt/src/kafka
3.修改配置
修改 server.properties
vim /opt/src/kafka/config/server.properties
分别配置
node001:
broker.id=0
listeners=PLAINTEXT://node001:9092
zookeeper.connect=node001:2181,node002:2181,node003:2181
node002:
broker.id=1
listeners=PLAINTEXT://node002:9092
zookeeper.connect=node001:2181,node002:2181,node003:2181
node003:
broker.id=2
listeners=PLAINTEXT://node003:9092
zookeeper.connect=node001:2181,node002:2181,node003:2181
4.配置环境变量同步到其他节点并激活
vim /root/.bashrc
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 566
566

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









