






最近在学习和实践自然语言处理相关的知识,在这个文档从头到尾做个总结,防止自己忘记,也提供给新人来参考。本教程英文处理使用的是NLTK这个Python库,中文处理使用的是jieba这个Python库,主要是看July7月学习NLP视频学习而来,如有侵权,立即删除。Natural Language Processing(NLP)自然语言处理主要是处理以及理解自然语言的计算过程。整个自然语言处理的大致流程入下图所示:
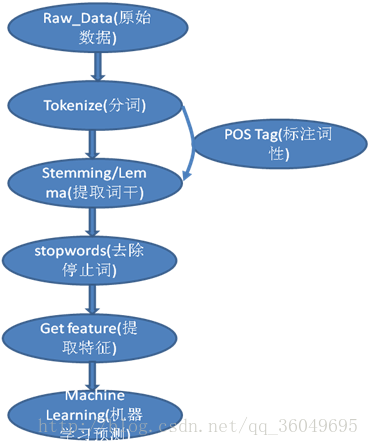
图1:自然语言处理流程
一、自然语言处理流程
第一步:Tokenize——分词,分词是将一个句子分成很多个单词,用一个word list存起来。如:
英文:How are you today? 会分成 [“How”,”are”,”you”,”today”,”?”]
中文:今天心情很好。 会分成[“今天”,”心情”,”很”,”好”,”。”]
第二步: Stemming/Lemma——提取词干,是将英文的过去式,名词形式,复数形式全部转换为最原始单词。如:
apples => apple, went => go, watched => watch, watching => watch
第三步:stopwords ——去除停止词,去掉单词列表中的停止词the,a等单词。如:
英文: The school is beautiful. => [“school”,”beautiful”],去掉了the,is等单词。
有时会用到POS Tag —— 标注词性,即标注出单词是动词/名词/形容词/副词等。
第四步:Get feature —— 提取特征,这个步骤的意思是用一个什么样的向量来表示这单词或者句子。如使用TF-IDF来表示一个单词:
TF:Term Frequecy:衡量一个单词在文档中出现的次数
TF(term) = (term出现在文档中的次数)/(文档中单词的总数)
IDF:Inverse Document Frequecy,衡量一个单词的重要性
IDF(term) = loge(文档总数/含有term的文档总数)
如果一个单词在所有文档中都出现了,则IDF(term) = 0,表明这个单词不重要。
TF-IDF = TF * IDF
对每个单词进行统计和计算,就可以得到每个单词的TF-IDF的值,用这个值来代替这个单词,整个句子就变成了一个浮点数的List。
当然这个是最简单的模型,这个模型有很多缺陷,现在流行的word2vect和fasttext,都是由google实习生写出来的,这两个模型生成的分布式向量可以有效的表达出两个单词之间的关系,这个在后续再做介绍。
第五步:Machine Learning——机器学习,机器学习是表示得到特征向量之后,能根据训练集合来预测需要测试集合。这个部分也在后续再做专门的介绍。
二、自然语言处理入门软件安装以及常见问题
整个实验环境是在VMWare+Ubuntu 16.04 LTS下完成的,最好是能翻墙,我用的翻墙软件是LoCo加速器。
自然语言处理入门学习系列<一>
最新推荐文章于 2024-08-22 10:46:55 发布

 本文档是对自然语言处理(NLP)的入门总结,使用Python的NLTK和jieba库。介绍了NLP的基本流程,包括分词、词干提取、去除停用词等,并分享了在Ubuntu环境下安装NLP相关软件的步骤,解决常见问题。最后,以Kaggle竞赛为例,展示了数据清洗和特征提取的实践操作。
本文档是对自然语言处理(NLP)的入门总结,使用Python的NLTK和jieba库。介绍了NLP的基本流程,包括分词、词干提取、去除停用词等,并分享了在Ubuntu环境下安装NLP相关软件的步骤,解决常见问题。最后,以Kaggle竞赛为例,展示了数据清洗和特征提取的实践操作。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3406
3406

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









