







ElasticSearch安装
下载软件
ElasticSearch的官网,视频教程里用的Version是7.8.0,所以,我们也是用7.8.0版本的ElasticSearch。
下载地址:https://www.elastic.co/cn/downloads/past-releases#elasticsearch,然后搜索7.8.0版本即可。
按照视频里讲的,下载了Windows版本的ElasticSearch,当然,生产环境肯定是Linux版本的。
安装软件
Windows版本的安装很简单,解压后就可以使用了。
| 目录 | 含义 |
|---|---|
| bin | 可执行脚本目录 |
| config | 配置目录 |
| jdk | 内置JDK目录 |
| lib | 类库 |
| logs | 日志目录 |
| modules | 模块目录 |
| plugins | 插件目录 |
解压缩后,进入到bin目录下,运行elasticsearch.bat文件就启动了ElasticSearch服务。这里需要留意两个端口:9200和9300。
9200端口为浏览器访问的http协议RESTful端口,9300端口为Elasticsearch集群间组件的通信端口。
此时打开浏览器访问:http://localhost:9200/,可以看到内容,表示ElasticSearch服务启动成功。
问题解决
ElasticSearch是基于Java开发的,7.8.0版本的ElasticSearch需要JDK1.8及以上版本,默认的安装包里带有JDK,如果系统配置了JAVA_HOME,会使用系统配置的JDK,如果没有配置,会使用安装包里自带的JDK,建议使用系统配置的JDK。
如果出现启动后闪退的情况,可能是空间不足,需要修改config/jvm.options配置文件。
# 设置JVM初始内存为1G。此值可以设置与-Xmx相同,以避免每次垃圾回收完成后JVM重新分配内存
# Xms represents the initial size of total heap space
# 设置JVM最大可用内存为1G
# Xmx represents the maximum size of total heap space
-Xms1g
-Xmx1g
ElasticSearch基本操作
RESTful
REST指的是一组架构约束条件和原则。满足这些约束条件和原则的应用程序或设计就是RESTful。Web应用程序最重要的REST原则是,客户端和服务器之间的交互在请求之间是无状态的。从客户端到服务器的每个请求都必须包含理解请求所必需的信息。如果服务器在请求之间的任何时间点重启,客户端不会得到通知。此外,无状态请求可以由任何可用服务器回答,这十分适合云计算之类的环境。客户端可以缓存数据以改进性能。
在服务器端,应用程序状态和功能可以分为各种资源。资源是一个有趣的概念实体,它向客户端公开。资源的例子有:应用程序对象、数据库记录、算法等等。每个资源都使用URI(Universal Resource Identifier)得到一个唯一的地址。所有资源都共享统一的接口,以便在客户端和服务器之间传输状态。使用的是标准的HTTP方法,比如GET、PUT、POST和DELETE。
在REST样式的Web服务中,每个资源都有一个地址。资源本身都是方法调用的目标,方法列表对所有资源都是一样的。这些方法都是标准方法,包括HTTP GET、POST、PUT、DELETE,还可能包括HEAD和OPTIONS。简单的理解就是,如果想要访问互联网上的资源,就必须向资源所在的服务器发出请求,请求体中必须包含资源的网络路径,以及对资源进行的操作(增删改查)。
客户端安装
如果直接通过浏览器向Elasticsearch服务器发请求,那么需要在发送的请求中包含HTTP标准的方法,而HTTP的大部分特性且仅支持GET和POST方法。所以为了能方便地进行客户端的访问,可以使用Postman软件Postman是一款强大的网页调试工具,提供功能强大的Web API和HTTP请求调试。
软件功能强大,界面简洁明晰、操作方便快捷,设计得很人性化。Postman中文版能够发送任何类型的HTTP请求(GET, HEAD, POST, PUT……),不仅能够表单提交,且可以附带任意类型请求体。
Postman官网
Postman下载
数据格式
Elasticsearch是面向文档型数据库,一条数据在这里就是一个文档。为了方便大家理解,我们将Elasticsearch里存储文档数据和关系型数据库MySQL存储数据的概念进行一个类比。
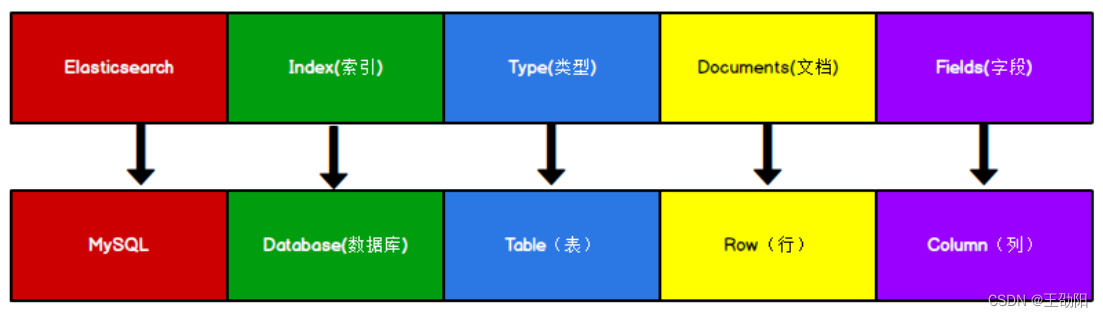
ES里的Index可以看做一个库,而Types相当于表,Documents则相当于表的行。
这里Types的概念已经被逐渐弱化,Elasticsearch 6.X中,一个index下已经只能包含一个type,Elasticsearch 7.X中,Type的概念已经被删除了。
用JSON作为文档序列化的格式。
HTTP操作
索引操作
创建索引
# 创建一个名为my_index的索引
PUT /my_index
# 结果
{
"acknowledged": true,
"shards_acknowledged": true,
"index": "my_index"
}
# 再次执行这个请求,会返回错误信息
{
"error": {
"root_cause": [
{
"type": "resource_already_exists_exception",
"reason": "index [my_index/_vtClcNVRtGutbWMgIhpAg] already exists",
"index_uuid": "_vtClcNVRtGutbWMgIhpAg",
"index": "my_index"
}
],
"type": "resource_already_exists_exception",
"reason": "index [my_index/_vtClcNVRtGutbWMgIhpAg] already exists",
"index_uuid": "_vtClcNVRtGutbWMgIhpAg",
"index": "my_index"
},
"status": 400
}
查看所有索引
# 查看所有索引
GET /_cat/indices
# 结果
yellow open my_index _vtClcNVRtGutbWMgIhpAg 1 1 0 0 208b 208b
| 表头 | 含义 |
|---|---|
| health | 当前服务器健康状态:green-集群完整,yellow-单点正常、集群不完整,red-单点不正常 |
| status | 索引打开、关闭状态 |
| index | 索引名 |
| uuid | 索引唯一编号 |
| pri | 主分片数量 |
| rep | 副本数量 |
| docs.count | 可用文档数量 |
| docs.deleted | 文档删除状态(逻辑删除) |
| store.size | 主分片和副分片整体占空间大小 |
| pri.store.size | 主分片占空间大小 |
查看单个索引
# 查看单个索引
GET /my_index
# 结果
{
"my_index": {
"aliases": {},
"mappings": {},
"settings": {
"index": {
"creation_date": "1685762192047",
"number_of_shards": "1",
"number_of_replicas": "1",
"uuid": "_vtClcNVRtGutbWMgIhpAg",
"version": {
"created": "7080099"
},
"provided_name": "my_index"
}
}
}
}
删除索引
# 删除索引
DELETE /my_index
# 结果
{
"acknowledged": true
}
# 再次执行这个请求,会返回错误信息
{
"error": {
"root_cause": [
{
"type": "index_not_found_exception",
"reason": "no such index [my_index]",
"resource.type": "index_or_alias",
"resource.id": "my_index",
"index_uuid": "_na_",
"index": "my_index"
}
],
"type": "index_not_found_exception",
"reason": "no such index [my_index]",
"resource.type": "index_or_alias",
"resource.id": "my_index",
"index_uuid": "_na_",
"index": "my_index"
},
"status": 404
}
文档操作
创建文档
接下来,我们创建文档,一个文档相当于关系型数据库表中的一行数据。
# 创建文档
POST /my_index/_doc
{
"name": "王劭阳",
"sex": "男",
"address": "山东省济南市"
}
# 结果
{
"_index": "my_index",
"_type": "_doc",
"_id": "G4JNf4gB5UHhrLgfdkiL",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 0,
"_primary_term": 1
}
在早期ElasticSearch里,有type的概念,在ElasticSearch 7版本,移除了type的概念,历史版本创建的数据,默认置为_doc。在ElasticSearch 8版本,完全废弃了type的概念。
在创建的时候,由于没有指定数据唯一标识,ElasticSearch会随机生成一个,如果想要指定唯一标识,可以在创建的路径上加上标识。
# 创建指定id的文档
POST /my_index/_doc/1
{
"name": "王劭阳1",
"sex": "男",
"address": "山东省济南市"
}
# 结果
{
"_index": "my_index",
"_type": "_doc",
"_id": "1",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 1,
"_primary_term": 1
}
查看文档
# 根据id查看文档
GET /my_index/_doc/1
# 结果
{
"_index": "my_index",
"_type": "_doc",
"_id": "1",
"_version": 1,
"_seq_no": 1,
"_primary_term": 1,
"found": true,
"_source": {
"name": "王劭阳1",
"sex": "男",
"address": "山东省济南市"
}
}
修改文档
# 根据id修改文档
POST /my_index/_doc/1
{
"name": "王劭阳update",
"sex": "男",
"address": "山东省济南市update"
}
# 结果
{
"_index": "my_index",
"_type": "_doc",
"_id": "1",
"_version": 2,
"result": "updated",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 2,
"_primary_term": 1
}
这个操作是一个全字段替换,直接将请求体的内容完全替换到文档里。
修改字段
# 根据id修改字段
POST /my_index/_update/1
{
"doc": {
"name": "王劭阳update1"
}
}
# 结果
{
"_index": "my_index",
"_type": "_doc",
"_id": "1",
"_version": 3,
"result": "noop",
"_shards": {
"total": 0,
"successful": 0,
"failed": 0
},
"_seq_no": 3,
"_primary_term": 1
}
删除文档
# 根据id删除文档
DELETE /my_index/_doc/1
# 结果
{
"_index": "my_index",
"_type": "_doc",
"_id": "1",
"_version": 6,
"result": "deleted",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 6,
"_primary_term": 1
}
# 再次执行这个请求,会返回错误信息
{
"_index": "my_index",
"_type": "_doc",
"_id": "1",
"_version": 7,
"result": "not_found",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 7,
"_primary_term": 1
}
条件删除文档
# 条件删除文档
POST /my_index/_delete_by_query
{
"query": {
"match": {
"name": "王劭阳"
}
}
}
# 结果
{
"took": 2276,
"timed_out": false,
"total": 1,
"deleted": 1,
"batches": 1,
"version_conflicts": 0,
"noops": 0,
"retries": {
"bulk": 0,
"search": 0
},
"throttled_millis": 0,
"requests_per_second": -1.0,
"throttled_until_millis": 0,
"failures": []
}
映射操作
有了索引库,等于有了数据库中的database。接下来就需要建索引库(index)中的映射了,类似于数据库(database)中的表结构(table)。
创建数据库表需要设置字段名称,类型,长度,约束等;索引库也一样,需要知道这个类型下有哪些字段,每个字段有哪些约束信息,这就叫做映射(mapping)。
创建映射
# 创建映射
PUT /my_index/_mapping
{
"properties": {
"name": {
"type": "text",
"index": true
},
"sex": {
"type": "text",
"index": false
},
"age": {
"type": "long",
"index": false
}
}
}
# 结果
{
"acknowledged": true
}
在创建的时候,报错了,提示我某个字段已经有了mapping,这是因为我们先插入了文档,没有创建映射,ES自动帮我们创建的映射和我们想要创建的映射冲突导致的,我的解决方法是:把index_name删掉重建,但是不插入文档,然后执行创建映射的操作。
在properties里,有多个对象,查看每一个对象的构成。
字段名:任意写,下面指定多个属性
type:类型,ES中支持多种数据类型:
- String类型的text:可分词
- String类型的keyword:不可分次
- Numerical类型的基本数据类型:long、integer、short、byte、double、float、half_float
- Numerical类型的浮点数高精度类型:scaled_float
- Date:日期类型
- Array:数组类型
- Object:对象类型
index:是否索引,默认为true
- true:字段会被索引,可以用来搜索
- false:字段不会被索引,不能用来搜索
store:是否将数据进行独立存储,默认为false。原始的文本会存储在_source里面,默认情况下其他提取出来的字段都不是独立存储的,是从_source里面提取出来的。当然你也可以独立的存储某个字段,只要设置"store": true 即可,获取独立存储的字段要比从_source中解析快得多,但是也会占用更多的空间,所以要根据实际业务需求来设置
analyzer:分词器
查看映射
# 查看映射
GET /my_index/_mapping
# 结果
{
"my_index1": {
"mappings": {
"properties": {
"age": {
"type": "long",
"index": false
},
"name": {
"type": "text"
},
"address": {
"type": "text",
"index": true
}
}
}
}
}
索引映射关联
索引和映射要建立关联,才能方便后面的查询,上一步已经有映射关联了,所以这里再给index_name创建映射会报错,为了演示效果,先把索引删除,再创建索引映射关联。
# 索引映射关联
PUT /my_index
{
"settings": {},
"mappings": {
"properties": {
"name": {
"type": "text",
"index": true
},
"sex": {
"type": "text",
"index": false
},
"address": {
"type": "text",
"index": true
}
}
}
}
# 结果
{
"acknowledged": true,
"shards_acknowledged": true,
"index": "my_index"
}
高级查询
为了演示查询的功能,我们重建索引和映射,并插入4个文档信息用于查询。
# 创建索引和映射
PUT /my_index
{
"settings": {},
"mappings": {
"properties": {
"name": {
"type": "text",
"index": true
},
"sex": {
"type": "text",
"index": false
},
"address": {
"type": "text",
"index": true
}
}
}
}
# 插入数据
POST /my_index/_doc/1
{
"name": "张三",
"sex": "男",
"address": "山东省济南市"
}
POST /my_index/_doc/2
{
"name": "李四",
"sex": "女",
"address": "山东省淄博市"
}
POST /my_index/_doc/3
{
"name": "王五",
"sex": "男",
"address": "山东省聊城市"
}
POST /my_index/_doc/4
{
"name": "赵六",
"sex": "女",
"address": "山东省青岛市"
}
查询所有文档
# 查询所有文档
GET /_search
{
"from": 0,
"size": 10,
"query": {
"match_all": {}
}
}
# 结果
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 4,
"relation": "eq"
},
"max_score": 1.0,
"hits": [
{
"_index": "my_index",
"_type": "_doc",
"_id": "1",
"_score": 1.0,
"_source": {
"name": "张三",
"sex": "男",
"address": "山东省济南市"
}
},
{
"_index": "my_index",
"_type": "_doc",
"_id": "2",
"_score": 1.0,
"_source": {
"name": "李四",
"sex": "女",
"address": "山东省淄博市"
}
},
{
"_index": "my_index",
"_type": "_doc",
"_id": "3",
"_score": 1.0,
"_source": {
"name": "王五",
"sex": "男",
"address": "山东省聊城市"
}
},
{
"_index": "my_index",
"_type": "_doc",
"_id": "4",
"_score": 1.0,
"_source": {
"name": "赵六",
"sex": "女",
"address": "山东省青岛市"
}
}
]
}
}
匹配查询
# 匹配查询
GET /_search
{
"query": {
"match": {
"name": "张三"
}
}
}
# 结果
{
"took": 13,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 2.4079456,
"hits": [
{
"_index": "my_index",
"_type": "_doc",
"_id": "1",
"_score": 2.4079456,
"_source": {
"name": "张三",
"sex": "男",
"address": "山东省济南市"
}
}
]
}
}
字段匹配查询
# 字段匹配查询
GET /_search
{
"query": {
"multi_match": {
"query": "李四",
"fields": [
"name",
"address"
]
}
}
}
# 结果
{
"took": 6,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 2.4079456,
"hits": [
{
"_index": "my_index",
"_type": "_doc",
"_id": "2",
"_score": 2.4079456,
"_source": {
"name": "李四",
"sex": "女",
"address": "山东省淄博市"
}
}
]
}
}
关键字精确查询
不对查询条件进行分词,这里没有查到好像和分词有关系,先学习语法吧,这里我也不大清楚为什么查不到。
# 关键字精确查询
GET /_search
{
"query": {
"term": {
"address": {
"value": "山东省青岛市"
}
}
}
}
# 结果
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 0,
"relation": "eq"
},
"max_score": null,
"hits": []
}
}
多关键字精确查询
# 多关键字精确查询
GET /_search
{
"query": {
"terms": {
"address": [
"山东省青岛市",
"山东省淄博市"
]
}
}
}
# 结果
{
"took": 2,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 0,
"relation": "eq"
},
"max_score": null,
"hits": []
}
}
指定查询字段
只想查询name和address,通过_source可以指定。
# 指定查询字段
GET /my_index/_search
{
"_source": [
"name",
"address"
],
"query": {
"match": {
"name": "王五"
}
}
}
# 结果
{
"took": 2,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 2.4079456,
"hits": [
{
"_index": "my_index",
"_type": "_doc",
"_id": "3",
"_score": 2.4079456,
"_source": {
"address": "山东省聊城市",
"name": "王五"
}
}
]
}
}
过滤字段
通过includes和excludes作用于_source,指定想要显示的字段和不想显示的字段。
# 指定查询字段
GET /my_index/_search
{
"_source": {
"includes": [
"name",
"address"
]
},
"query": {
"match": {
"name": "赵六"
}
}
}
# 结果
{
"took": 5,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 2.4079456,
"hits": [
{
"_index": "my_index",
"_type": "_doc",
"_id": "4",
"_score": 2.4079456,
"_source": {
"address": "山东省青岛市",
"name": "赵六"
}
}
]
}
}
组合查询
通过must、must_not、should方式进行组合,构造出查询条件。
# 组合查询
GET /my_index/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"sex": "男"
}
}
],
"must_not": [
{
"match": {
"address": "山东省济南市"
}
}
],
"should": [
{
"match": {
"name": "王五"
}
}
]
}
}
}
# 结果
{
"took": 7,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 0,
"relation": "eq"
},
"max_score": null,
"hits": []
}
}
范围查询
# 范围查询
GET /my_index/_search
{
"query": {
"range": {
"age": {
"gt": "大于",
"gte": "大于等于",
"lt": "小于",
"lte": "小于等于"
}
}
}
}
# 结果
{
"took": 4,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 0,
"relation": "eq"
},
"max_score": null,
"hits": []
}
}
模糊查询
返回包含与搜索字词相似字词的文档。
编辑距离是将一个术语转换为另一个术语所需的一个字符更改的次数,这些更改包括:更改字符、删除字符、插入字符、转置两个相邻字符。
为了找到相似的术语,模糊查询会在指定编辑距离内创建一组搜索词的所有可能变体或扩展,然后查询返回每个扩展的完全匹配。
通过fuzziness修改编辑距离,一般使用AUTO,根据术语的长度生成编辑距离。
# 模糊查询
GET /my_index/_search
{
"query": {
"fuzzy": {
"address": {
"value": "山东省聊城市",
"fuzziness": "2"
}
}
}
}
# 结果
{
"took": 12,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 0,
"relation": "eq"
},
"max_score": null,
"hits": []
}
}
单字段排序
这里必须带上keyword,否则直接报错,不知道为什么,而且排序后的结果也很奇怪,跟我想象的也不一样。感觉还是和分词有关系,上面的几个查询,如果带上keyword,就可以查到东西,应该也是类似的原因。
# 单字段排序
GET /my_index/_search
{
"query": {
"match_all": {
}
},
"sort": [
{
"name.keyword": {
"order": "asc"
}
}
]
}
# 结果
{
"took": 2,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 4,
"relation": "eq"
},
"max_score": null,
"hits": [
{
"_index": "my_index",
"_type": "_doc",
"_id": "1",
"_score": null,
"_source": {
"name": "张三",
"sex": "男",
"address": "山东省济南市"
},
"sort": [
"张三"
]
},
{
"_index": "my_index",
"_type": "_doc",
"_id": "2",
"_score": null,
"_source": {
"name": "李四",
"sex": "女",
"address": "山东省淄博市"
},
"sort": [
"李四"
]
},
{
"_index": "my_index",
"_type": "_doc",
"_id": "3",
"_score": null,
"_source": {
"name": "王五",
"sex": "男",
"address": "山东省聊城市"
},
"sort": [
"王五"
]
},
{
"_index": "my_index",
"_type": "_doc",
"_id": "4",
"_score": null,
"_source": {
"name": "赵六",
"sex": "女",
"address": "山东省青岛市"
},
"sort": [
"赵六"
]
}
]
}
}
多字段排序
# 多字段排序
GET /my_index/_search
{
"query": {
"match_all": {
}
},
"sort": [
{
"name.keyword": {
"order": "asc"
}
},
{
"address.keyword": {
"order": "desc"
}
}
]
}
# 结果
{
"took": 2049,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 4,
"relation": "eq"
},
"max_score": null,
"hits": [
{
"_index": "my_index",
"_type": "_doc",
"_id": "4",
"_score": null,
"_source": {
"name": "赵六",
"sex": "女",
"address": "山东省青岛市"
},
"sort": [
"赵六",
"山东省青岛市"
]
},
{
"_index": "my_index",
"_type": "_doc",
"_id": "3",
"_score": null,
"_source": {
"name": "王五",
"sex": "男",
"address": "山东省聊城市"
},
"sort": [
"王五",
"山东省聊城市"
]
},
{
"_index": "my_index",
"_type": "_doc",
"_id": "2",
"_score": null,
"_source": {
"name": "李四",
"sex": "女",
"address": "山东省淄博市"
},
"sort": [
"李四",
"山东省淄博市"
]
},
{
"_index": "my_index",
"_type": "_doc",
"_id": "1",
"_score": null,
"_source": {
"name": "张三",
"sex": "男",
"address": "山东省济南市"
},
"sort": [
"张三",
"山东省济南市"
]
}
]
}
}
高亮查询
Elasticsearch可以对查询内容中的关键字部分,进行标签和样式(高亮)的设置。在使用match查询的同时,加上一个highlight属性:
pre_tags:前置标签
post_tags:后置标签
fields:需要高亮的字段
title:声明title字段需要高亮,后面可以为这个字段设置特有配置,也可以为空
# 高亮查询
GET /my_index/_search
{
"query": {
"match": {
"name": {
"query": "张三"
}
}
},
"highlight": {
"pre_tags": "<font color='red'>",
"post_tags": "</font>",
"fields": {
"name": {}
}
}
}
# 结果
{
"took": 3,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 2.4079456,
"hits": [
{
"_index": "my_index",
"_type": "_doc",
"_id": "1",
"_score": 2.4079456,
"_source": {
"name": "张三",
"sex": "男",
"address": "山东省济南市"
},
"highlight": {
"name": [
"<font color='red'>张</font><font color='red'>三</font>"
]
}
}
]
}
}
分页查询
通过设置from和size的值来控制分页,from默认从0开始,from = (pageNum - 1) * size 。
# 分页查询
GET /my_index/_search
{
"query": {
"match_all": {
}
},
"from": 0,
"size": 2
}
# 结果
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 4,
"relation": "eq"
},
"max_score": 1.0,
"hits": [
{
"_index": "my_index",
"_type": "_doc",
"_id": "1",
"_score": 1.0,
"_source": {
"name": "张三",
"sex": "男",
"address": "山东省济南市"
}
},
{
"_index": "my_index",
"_type": "_doc",
"_id": "2",
"_score": 1.0,
"_source": {
"name": "李四",
"sex": "女",
"address": "山东省淄博市"
}
}
]
}
}
聚合查询
聚合查询用于对文档进行统计分析,类似于group by,因为没有合适的文档用于展示,所以下面查询都是空的。
# 聚合查询之最大值
GET /my_index/_search
{
"aggs": {
"max_address": {
"max": {
"field": "address"
}
}
},
"size": 0
}
# 聚合查询之最小值
GET /my_index/_search
{
"aggs": {
"min_address": {
"min": {
"field": "address"
}
}
},
"size": 0
}
# 聚合查询之求和
GET /my_index/_search
{
"aggs": {
"sum_address": {
"sum": {
"field": "address"
}
}
},
"size": 0
}
# 聚合查询之求平均
GET /my_index/_search
{
"aggs": {
"avg_address": {
"avg": {
"field": "address"
}
}
},
"size": 0
}
# 聚合查询值求去重后获取总数
GET /my_index/_search
{
"aggs": {
"distinct_address": {
"cardinality": {
"field": "address"
}
}
},
"size": 0
}
# 聚合操作之state聚合,对某一个字段一次性返回count、max、min、avg、sum五个指标
GET /my_index/_search
{
"aggs": {
"state_address": {
"stats": {
"field": "address"
}
}
},
"size": 0
}
桶聚合查询
桶聚合相当于sql中的group by语句。
GET /my_index/_search
{
"aggs": {
"sex_group_by": {
"terms": {
"field": "sex.keyword"
}
}
}
}
# 结果
{
"took": 7,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 4,
"relation": "eq"
},
"max_score": 1.0,
"hits": [
{
"_index": "my_index",
"_type": "_doc",
"_id": "1",
"_score": 1.0,
"_source": {
"name": "张三",
"sex": "男",
"address": "山东省济南市"
}
},
{
"_index": "my_index",
"_type": "_doc",
"_id": "2",
"_score": 1.0,
"_source": {
"name": "李四",
"sex": "女",
"address": "山东省淄博市"
}
},
{
"_index": "my_index",
"_type": "_doc",
"_id": "3",
"_score": 1.0,
"_source": {
"name": "王五",
"sex": "男",
"address": "山东省聊城市"
}
},
{
"_index": "my_index",
"_type": "_doc",
"_id": "4",
"_score": 1.0,
"_source": {
"name": "赵六",
"sex": "女",
"address": "山东省青岛市"
}
}
]
},
"aggregations": {
"sex_group_by": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": "女",
"doc_count": 2
},
{
"key": "男",
"doc_count": 2
}
]
}
}
}
Java API操作
ElasticSearch是由Java语言开发的,所以可以通过Java API的方式访问ElasticSearch。
创建Maven项目
在pom.xml里添加依赖。
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>7.8.0</version>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.8.0</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-api</artifactId>
<version>2.8.2</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.8.2</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.9.9</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
<dependency>
<groupId>commons-logging</groupId>
<artifactId>commons-logging</artifactId>
<version>1.1.3</version>
</dependency>
客户端对象
早起版本的客户端对象已经不推荐使用, 这里使用RestHighLevelClient。
这里我用了一个Spring Boot项目直接创建的测试类,但是,奇怪的是,会报错,最后的解决方案是:新建一个空的Maven工程,因为Spring Boot项目里可能会引起jar包冲突。
java.lang.NoSuchMethodError: org.elasticsearch.client.Request.addParameters
索引操作
import org.apache.http.HttpHost;
import org.elasticsearch.action.admin.indices.delete.DeleteIndexRequest;
import org.elasticsearch.action.support.master.AcknowledgedResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.client.indices.CreateIndexRequest;
import org.elasticsearch.client.indices.CreateIndexResponse;
import org.elasticsearch.client.indices.GetIndexRequest;
import org.elasticsearch.client.indices.GetIndexResponse;
import java.io.IOException;
public class ElasticSearchTest {
public static void main(String[] args) {
try (RestHighLevelClient restHighLevelClient = new RestHighLevelClient(RestClient.builder(new HttpHost("localhost", 9200, "http")))) {
{// 创建索引
CreateIndexRequest createIndexRequest = new CreateIndexRequest("user");
CreateIndexResponse createIndexResponse = restHighLevelClient.indices().create(createIndexRequest, RequestOptions.DEFAULT);
System.out.println("操作状态:" + createIndexResponse.isAcknowledged());
}
{// 查询索引
GetIndexRequest getIndexRequest = new GetIndexRequest("user");
GetIndexResponse getIndexResponse = restHighLevelClient.indices().get(getIndexRequest, RequestOptions.DEFAULT);
System.out.println("aliases:" + getIndexResponse.getAliases());
System.out.println("mappings:" + getIndexResponse.getMappings());
System.out.println("settings:" + getIndexResponse.getSettings());
}
{// 删除索引
DeleteIndexRequest deleteIndexRequest = new DeleteIndexRequest("user");
AcknowledgedResponse acknowledgedResponse = restHighLevelClient.indices().delete(deleteIndexRequest, RequestOptions.DEFAULT);
System.out.println("操作结果:" + acknowledgedResponse.isAcknowledged());
}
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}
文档操作
首先创建一个user的索引,用于后续的文档操作,这里写一个demo,把新增文档、修改文档、查询文档、删除文档、批量操作都包含在内。
import net.sf.json.JSONObject;
import org.apache.http.HttpHost;
import org.elasticsearch.action.bulk.BulkRequest;
import org.elasticsearch.action.bulk.BulkResponse;
import org.elasticsearch.action.delete.DeleteRequest;
import org.elasticsearch.action.delete.DeleteResponse;
import org.elasticsearch.action.get.GetRequest;
import org.elasticsearch.action.get.GetResponse;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.action.index.IndexResponse;
import org.elasticsearch.action.update.UpdateRequest;
import org.elasticsearch.action.update.UpdateResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.common.xcontent.XContentType;
import java.io.IOException;
import java.util.Arrays;
public class ElasticSearchTest {
public static void main(String[] args) {
try (RestHighLevelClient restHighLevelClient = new RestHighLevelClient(RestClient.builder(new HttpHost("localhost", 9200, "http")))) {
{// 新增文档
IndexRequest indexRequest = new IndexRequest().index("user").id("0001");
User user = new User("zhangsan", 10, "男");
String userJSONString = JSONObject.fromObject(user).toString();// 对象转String
indexRequest.source(userJSONString, XContentType.JSON);// 指定文档数据格式为JSON
IndexResponse indexResponse = restHighLevelClient.index(indexRequest, RequestOptions.DEFAULT);
System.out.println("_index:" + indexResponse.getIndex());
System.out.println("_id:" + indexResponse.getId());
System.out.println("_result:" + indexResponse.getResult());
}
{// 修改文档
UpdateRequest updateRequest = new UpdateRequest();
updateRequest.index("user").id("0001");
updateRequest.doc(XContentType.JSON, "sex", "女");
UpdateResponse updateResponse = restHighLevelClient.update(updateRequest, RequestOptions.DEFAULT);
System.out.println("_index:" + updateResponse.getIndex());
System.out.println("_id:" + updateResponse.getId());
System.out.println("_result:" + updateResponse.getResult());
}
{// 查询文档
GetRequest getRequest = new GetRequest().index("user").id("0001");
GetResponse getResponse = restHighLevelClient.get(getRequest, RequestOptions.DEFAULT);
System.out.println("_index:" + getResponse.getIndex());
System.out.println("_type:" + getResponse.getType());
System.out.println("_id:" + getResponse.getId());
System.out.println("source:" + getResponse.getSourceAsString());
}
{// 删除文档
DeleteRequest deleteRequest = new DeleteRequest().index("user").id("0001");
DeleteResponse deleteResponse = restHighLevelClient.delete(deleteRequest, RequestOptions.DEFAULT);
System.out.println(deleteResponse.toString());
}
{// 批量操作
{// 批量添加
BulkRequest bulkRequest = new BulkRequest();
bulkRequest
.add(new IndexRequest().index("user").id("0001").source(JSONObject.fromObject(new User("zhangsan", 10, "男")).toString(), XContentType.JSON))
.add(new IndexRequest().index("user").id("0002").source(JSONObject.fromObject(new User("lisi", 20, "女")).toString(), XContentType.JSON));
BulkResponse bulkResponse = restHighLevelClient.bulk(bulkRequest, RequestOptions.DEFAULT);
System.out.println("took:" + bulkResponse.getTook());
System.out.println("items:" + Arrays.toString(bulkResponse.getItems()));
}
{// 批量删除
BulkRequest bulkRequest = new BulkRequest();
bulkRequest
.add(new DeleteRequest().index("user").id("0001"))
.add(new DeleteRequest().index("user").id("0002"));
BulkResponse bulkResponse = restHighLevelClient.bulk(bulkRequest, RequestOptions.DEFAULT);
System.out.println("took:" + bulkResponse.getTook());
System.out.println("items:" + Arrays.toString(bulkResponse.getItems()));
}
}
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}
高级查询
写一个demo,把请求体查询、高亮查询、聚合查询都包含在内,需要提前准备数据。
import net.sf.json.JSONObject;
import org.apache.http.HttpHost;
import org.elasticsearch.action.bulk.BulkRequest;
import org.elasticsearch.action.bulk.BulkResponse;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.common.unit.Fuzziness;
import org.elasticsearch.common.xcontent.XContentType;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.SearchHits;
import org.elasticsearch.search.aggregations.AggregationBuilders;
import org.elasticsearch.search.aggregations.bucket.terms.Terms;
import org.elasticsearch.search.aggregations.metrics.Max;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import org.elasticsearch.search.fetch.subphase.highlight.HighlightBuilder;
import org.elasticsearch.search.sort.SortOrder;
import java.io.IOException;
import java.util.Arrays;
public class ElasticSearchTest {
public static void main(String[] args) {
try (RestHighLevelClient restHighLevelClient = new RestHighLevelClient(RestClient.builder(new HttpHost("localhost", 9200, "http")))) {
{// 准备测试数据
BulkRequest bulkRequest = new BulkRequest();
bulkRequest
.add(new IndexRequest().index("user").id("0001").source(JSONObject.fromObject(new User("zhangsan", 10, "女")).toString(), XContentType.JSON))
.add(new IndexRequest().index("user").id("0002").source(JSONObject.fromObject(new User("lisi", 30, "女")).toString(), XContentType.JSON))
.add(new IndexRequest().index("user").id("0003").source(JSONObject.fromObject(new User("wangwu1", 40, "男")).toString(), XContentType.JSON))
.add(new IndexRequest().index("user").id("0004").source(JSONObject.fromObject(new User("wangwu2", 20, "女")).toString(), XContentType.JSON))
.add(new IndexRequest().index("user").id("0005").source(JSONObject.fromObject(new User("wangwu3", 50, "男")).toString(), XContentType.JSON))
.add(new IndexRequest().index("user").id("0006").source(JSONObject.fromObject(new User("wangwu4", 20, "男")).toString(), XContentType.JSON));
BulkResponse bulkResponse = restHighLevelClient.bulk(bulkRequest, RequestOptions.DEFAULT);
System.out.println("took:" + bulkResponse.getTook());
System.out.println("items:" + Arrays.toString(bulkResponse.getItems()));
}
{// 请求体查询
{// 查询所有索引数据
SearchRequest searchRequest = new SearchRequest()
.indices("user")
.source(new SearchSourceBuilder().query(QueryBuilders.matchAllQuery()));
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
SearchHits searchHits = searchResponse.getHits();
System.out.println("took:" + searchResponse.getTook());
System.out.println("timeout:" + searchResponse.isTimedOut());
System.out.println("total:" + searchHits.getTotalHits());
System.out.println("MaxScore:" + searchHits.getMaxScore());
for (SearchHit searchHit : searchHits) {// 输出每条查询结果
System.out.println(searchHit.getSourceAsString());
}
}
{// term查询,查询条件为关键字
SearchRequest searchRequest = new SearchRequest()
.indices("user")
.source(new SearchSourceBuilder().query(QueryBuilders.termQuery("age", "30")));
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
SearchHits searchHits = searchResponse.getHits();
System.out.println("took:" + searchResponse.getTook());
System.out.println("timeout:" + searchResponse.isTimedOut());
System.out.println("total:" + searchHits.getTotalHits());
System.out.println("MaxScore:" + searchHits.getMaxScore());
for (SearchHit searchHit : searchHits) {// 输出每条查询结果
System.out.println(searchHit.getSourceAsString());
}
}
{// 分页查询
SearchRequest searchRequest = new SearchRequest()
.indices("user")
.source(new SearchSourceBuilder()
.query(QueryBuilders.matchAllQuery())
.from(0)// offset
.size(2)// limit
);
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
SearchHits searchHits = searchResponse.getHits();
System.out.println("took:" + searchResponse.getTook());
System.out.println("timeout:" + searchResponse.isTimedOut());
System.out.println("total:" + searchHits.getTotalHits());
System.out.println("MaxScore:" + searchHits.getMaxScore());
for (SearchHit searchHit : searchHits) {// 输出每条查询结果
System.out.println(searchHit.getSourceAsString());
}
}
{// 数据排序
SearchRequest searchRequest = new SearchRequest()
.indices("user")
.source(new SearchSourceBuilder()
.query(QueryBuilders.matchAllQuery())
.sort("age", SortOrder.ASC)
// 如果有多个字段排序,那就继续指定sort()方法
);
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
SearchHits searchHits = searchResponse.getHits();
System.out.println("took:" + searchResponse.getTook());
System.out.println("timeout:" + searchResponse.isTimedOut());
System.out.println("total:" + searchHits.getTotalHits());
System.out.println("MaxScore:" + searchHits.getMaxScore());
for (SearchHit searchHit : searchHits) {// 输出每条查询结果
System.out.println(searchHit.getSourceAsString());
}
}
{// 过滤字段
SearchRequest searchRequest = new SearchRequest()
.indices("user")
.source(new SearchSourceBuilder()
.query(QueryBuilders.matchAllQuery())
.fetchSource(new String[]{"name", "age"}, new String[]{"sex"})
);
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
SearchHits searchHits = searchResponse.getHits();
System.out.println("took:" + searchResponse.getTook());
System.out.println("timeout:" + searchResponse.isTimedOut());
System.out.println("total:" + searchHits.getTotalHits());
System.out.println("MaxScore:" + searchHits.getMaxScore());
for (SearchHit searchHit : searchHits) {// 输出每条查询结果
System.out.println(searchHit.getSourceAsString());
}
}
{// Bool查询
SearchRequest searchRequest = new SearchRequest()
.indices("user")
.source(new SearchSourceBuilder().query(QueryBuilders.boolQuery()
.must(QueryBuilders.matchQuery("age", 20))// 必须满足的条件
.mustNot(QueryBuilders.matchQuery("name", "wangwu2"))// 必须不满足的条件
.should(QueryBuilders.matchQuery("sex", "男"))// 可以满足的条件
));
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
SearchHits searchHits = searchResponse.getHits();
System.out.println("took:" + searchResponse.getTook());
System.out.println("timeout:" + searchResponse.isTimedOut());
System.out.println("total:" + searchHits.getTotalHits());
System.out.println("MaxScore:" + searchHits.getMaxScore());
for (SearchHit searchHit : searchHits) {// 输出每条查询结果
System.out.println(searchHit.getSourceAsString());
}
}
{// 范围查询
SearchRequest searchRequest = new SearchRequest()
.indices("user")
.source(new SearchSourceBuilder().query(QueryBuilders.rangeQuery("age")
.gte("20")
.lte("30")));
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
SearchHits searchHits = searchResponse.getHits();
System.out.println("took:" + searchResponse.getTook());
System.out.println("timeout:" + searchResponse.isTimedOut());
System.out.println("total:" + searchHits.getTotalHits());
System.out.println("MaxScore:" + searchHits.getMaxScore());
for (SearchHit searchHit : searchHits) {// 输出每条查询结果
System.out.println(searchHit.getSourceAsString());
}
}
{// 模糊查询
SearchRequest searchRequest = new SearchRequest()
.indices("user")
.source(new SearchSourceBuilder().query(QueryBuilders.fuzzyQuery("name", "wangwu")
.fuzziness(Fuzziness.ONE)));
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
SearchHits searchHits = searchResponse.getHits();
System.out.println("took:" + searchResponse.getTook());
System.out.println("timeout:" + searchResponse.isTimedOut());
System.out.println("total:" + searchHits.getTotalHits());
System.out.println("MaxScore:" + searchHits.getMaxScore());
for (SearchHit searchHit : searchHits) {// 输出每条查询结果
System.out.println(searchHit.getSourceAsString());
}
}
}
{// 高亮查询
SearchRequest searchRequest = new SearchRequest()
.indices("user")
.source(new SearchSourceBuilder()
.query(QueryBuilders.termQuery("name", "zhangsan"))
.highlighter(new HighlightBuilder()
.field("name")
.preTags("<font color='red'>")
.postTags("</font>"))
);
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
SearchHits searchHits = searchResponse.getHits();
System.out.println("took:" + searchResponse.getTook());
System.out.println("timeout:" + searchResponse.isTimedOut());
System.out.println("total:" + searchHits.getTotalHits());
System.out.println("MaxScore:" + searchHits.getMaxScore());
for (SearchHit searchHit : searchHits) {// 输出每条查询结果
System.out.println(searchHit.getSourceAsString());
System.out.println(searchHit.getHighlightFields());
}
}
{// 聚合查询
{// 最大年龄
String maxName = "maxAge";
SearchRequest searchRequest = new SearchRequest()
.indices("user")
.source(new SearchSourceBuilder().aggregation(AggregationBuilders
.max(maxName).field("age"))
);
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
Max max = searchResponse.getAggregations().get(maxName);
System.out.println("最大值为:" + max.getValue());
}
{// 分组统计
String groupName = "groupByAge";
SearchRequest searchRequest = new SearchRequest()
.indices("user")
.source(new SearchSourceBuilder().aggregation(AggregationBuilders
.terms(groupName).field("age"))
);
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
Terms terms = searchResponse.getAggregations().get(groupName);
for (Terms.Bucket bucket : terms.getBuckets()) {
System.out.println("key=" + bucket.getKeyAsString() + ",count=" + bucket.getDocCount());
}
}
}
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}














 556
556











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









