






HDFS的体系结构
HDFS是一个分布式存储系统
HDFS的核心
NameNode
DataNode
SecondaryNameNode(NameNode的快照)
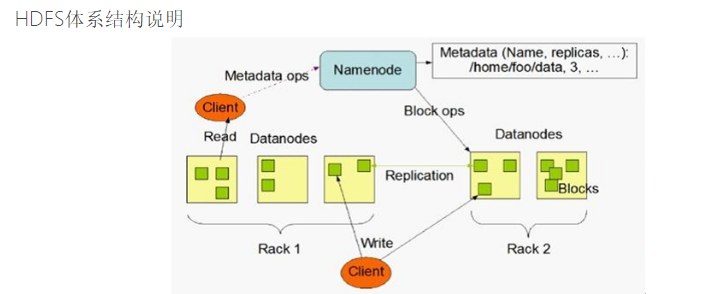
HDFS是一个主从结构,一个HDFS集群由一个名字节点(NameNode)和多个数据节点(DataNode)组成
HDFS的优点
1.高容错性 2.海量数据的存储 3.文件分块存储 4.移动计算 5.流式数据访问 6.可构建在廉价的机器上
HDFS的核心组件
namenode

01.Namenode执行文件系统的命名空间操作,例如打开、关闭、重命名文件和目录,同时决定block到具体Datanode节点的映射
02.协调客户端对文件的访问
03.记录每个文件数据在各个DataNode上的位置和副本信息
文件结构解析
fsimage:二进制文件,存储HDFS文件和目录元数据
Edits:二进制文件,每次保存fsimage之后到下次保存之间的所有HDFS操作,记录在Edit s文件。对文件的每一次操作,如打开、关闭、重命名文件和目录,都会生成一个edit记录。
fstime:二进制文件,fsimage做完一次checkpoint后,将最新的时间戳写入到fstime
VERSION:文本文件,文件的内容为(图示引用书籍:Hadoop实战):
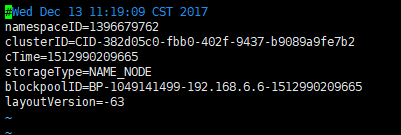
其中,namespaceID是文件系统的唯一标识符,当文件系统第一次被格式化的时候会被创建,这个标识符也要求所有的DataNode节点和NameNode保持一致。 NameNode会使用它识别新的DataNode,DataNode只有在向NameNode注册后才会获取namespaceID。
DataNode

DataNode的作用
保存block
启动DataNode线程的时候会向NameNode汇报block信息
通过向NameNode发送心跳保持与其联系(3秒一次),如果NameNode10分钟没有收到DataNode的心跳,则认为其已经lost,并copy其上的block到其它DataNode
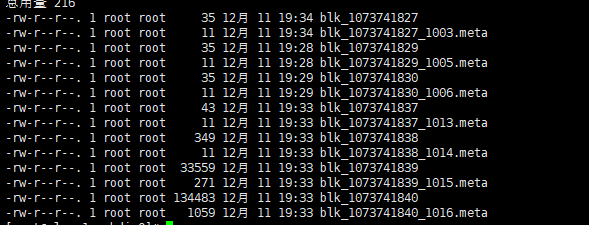
datanode启动时,每个datanode对本地磁盘进行扫描,将本datanode上保存的block信息汇报给namenode
namenode在接收到每个datanode的块信息汇报后,将接收到的块信息,以及其所在的datanode信息等保存在内存中。
Secondary NameNode 
02.记录Namenode中的metadata及其它数据
03.可以用来恢复Namenode,并不能替代NameNode!
第一步:Secondary NameNode首先请求NameNode进行edits的滚动,这样NameNode开始重新写一个新的edit log
第二步:Secondary NameNode通过HTTP方式读取NameNode中的fsimage及edits
第三步:Secondary NameNode读取fsimage到内存中,然后执行edits中的每个操作,并创建一个新的统一的fsimage文件。
第四步:Secondary NameNode通过HTTP方式将新的fsimage发送到NameNode
第五步:NameNode用新的fsimage替换旧的fsimage,旧的edits文件用步骤1中的edits进行替换,同时系统会更新fsimage文件记录检查点时间















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









