






飞书导出在线文档
调用飞书API,下载飞书在线文档:调用[API] 下载导出文件,[API] 创建导出任务,[API] 查询导出任务结果。不是在线文档可以直接调用下载API,在线文档需要3个步骤

创建应用,申请权限
创建应用。在开发者后台,根据实际需求,创建自建应用或者商店应用。
注意: 仅拥有 ISV 资质的用户可以创建商店应用。有关 ISV 的详细介绍,请参考如何入驻飞书开放平台。
申请权限。如果要调用 API,需要先获取接口调用权限;如果涉及到访问敏感字段,还需获取访问敏感字段的权限。
https://open.feishu.cn/document/server-docs/application-scope/introduction

获取 tenant_access_token
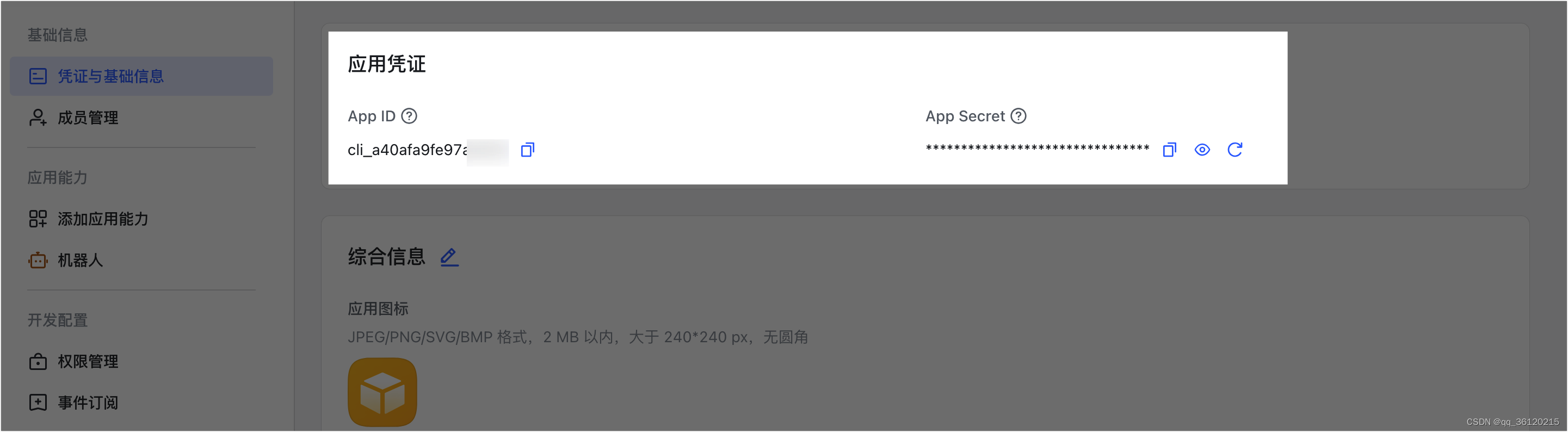
1.登录开发者后台,选择指定的自建应用。
2.在 基础信息 > 凭证与基础信息 页面,获取应用凭证 App ID 和 App Secret。
3.调用自建应用获取 tenant_access_token 接口,通过应用凭证 App ID 和 App Secret 获取自建应用的tenant_access_token。
代码
class Feishu_Download:
def __init__(self):
pass
def export(self):
token = 'XXX'
# 连接飞书,获取token
url = "https://open.feishu.cn/open-apis/auth/v3/tenant_access_token/internal/"
payload = {"app_id": "XXX", "app_secret": "XXX"}
response = requests.post(url=url, json=payload)
access_token = response.json()["tenant_access_token"]
# 创建导出任务
url1 = "https://open.feishu.cn/open-apis/drive/v1/export_tasks"
headers = {"Content-Type": "application/json", "Authorization": "Bearer " + str(access_token)} # 请求头
payload1 = json.dumps({
"file_extension": "xlsx",
"token": token,
"type": "sheet"
})
response = requests.request("POST", url=url1, data=payload1, headers=headers)
print(response.json()["msg"])
ticket = response.json()["data"]["ticket"]
print(ticket)
time.sleep(5)
# 查看导出任务结果
url2 = "https://open.feishu.cn/open-apis/drive/v1/export_tasks/" + ticket + "?token=" + token
headers2 = {'Authorization': 'Bearer ' + str(access_token)} # 请求头
response = requests.request("GET", url2, headers=headers2)
file_token = response.json()["data"]["result"]["file_token"]
print(file_token)
# 下载文件
try:
url = "https://open.feishu.cn/open-apis/drive/v1/export_tasks/file/" + file_token + "/download"
payload = ''
response = requests.request("GET", url, headers=headers, data=payload)
with open("result.xlsx", "wb") as f:
f.write(response.content)
print('下载飞书在线文档成功')
except Exception as e:
traceback.print_exc()
如何获取云文档资源相关 token(id)?
1.通过浏览器地址栏获取 token (以下红色部分)(注意: 拷贝时 URL 末尾可能多余的 “#”)
文件夹 folder_token: https://sample.feishu.cn/drive/folder/cSJe2JgtFFBwRuTKAJK6baNGUn0
文件 file_token:https://sample.feishu.cn/file/ndqUw1kpjnGNNaegyqDyoQDCLx1
文档 doc_token:https://sample.feishu.cn/docs/2olt0Ts4Mds7j7iqzdwrqEUnO7q
新版文档 document_id:https://sample.feishu.cn/docx/UXEAd6cRUoj5pexJZr0cdwaFnpd
电子表格 spreadsheet_token:https://sample.feishu.cn/sheets/MRLOWBf6J47ZUjmwYRsN8utLEoY
多维表格 app_token:https://sample.feishu.cn/base/Pc9OpwAV4nLdU7lTy71t6Kmmkoz
知识空间 space_id(知识库管理员打开设置页面):https://sample.feishu.cn/wiki/settings/7075377271827264924
知识库节点 node_token:https://sample.feishu.cn/wiki/sZdeQp3m4nFGzwqR5vx4vZksMoe
2.通过开放平台接口获取
「云空间」资源的 token 和 type 获取
通过文件管理获取根文件夹 root_token 。
通过文件管理获取文件夹下文件清单 获取各种资源的 token 和 type。再通过 文档、电子表格、多维表格API 读写文档内容数据。
「知识库」资源的 token 和 type 获取
通过 知识库 获取知识空间列表获取 space_id。
通过 知识库 获取子节点列表获取 node_token。
通过 知识库 获取节点信息获取各种资源的 obj_token 和 obj_type。再通过 文档、电子表格、多维表格API 读写文档内容数据。
「文档」中嵌入的电子表格 spreadsheet_token (多维表格 app_token) 获取
通过 获取文档富文本内容 返回文档中嵌入的电子表格 spreadsheet_token 和 tableId (多维表格 app_token 和 tableId) 。例如:
电子表格(“_” 前面是 spreadsheet_token,后面是 tableId) MRLOWBf6J47ZUjmwYRsN8utLEoY_m7fMrN
多维表格(“_” 前面是 app_token,后面是 tableId) Pc9OpwAV4nLdU7lTy71t6Kmmkoz_tblC63QuAGFOJkU9
「电子表格」中嵌入的多维表格 app_token 获取
通过 获取表格元数据 返回电子表格中嵌入的多维表格 app_token 和 tableId 。例如:
多维表格(“_” 前面是 app_token,后面是 tableId) Pc9OpwAV4nLdU7lTy71t6Kmmkoz_tbliITl3F8GXBtKw
https://open.feishu.cn/document/server-docs/docs/drive-v1/export_task/export-user-guide
飞书开发者文档非常全面,此文章只是提供个思路。飞书API调试台对于每个接口都有代码示例,非常好用


















 4928
4928

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









