







一、Java集合框架
集合框架是一个用来代表和操纵集合的统一架构。Java的集合框架又被称为容器,所有的集合框架都包含如下内容:
-
接口:是代表集合的抽象数据类型。例如 Collection、List、Set、Map 等。之所以定义多个接口,是为了以不同的方式操作集合对象
-
实现(类):是集合接口的具体实现。从本质上讲,它们是可重复使用的数据结构,例如:ArrayList、LinkedList、HashSet、HashMap。
-
算法:是实现集合接口的对象里的方法执行的一些有用的计算,例如:搜索和排序。这些算法被称为多态,那是因为相同的方法可以在相似的接口上有着不同的实现。Java集合框架图
Java集合框架图
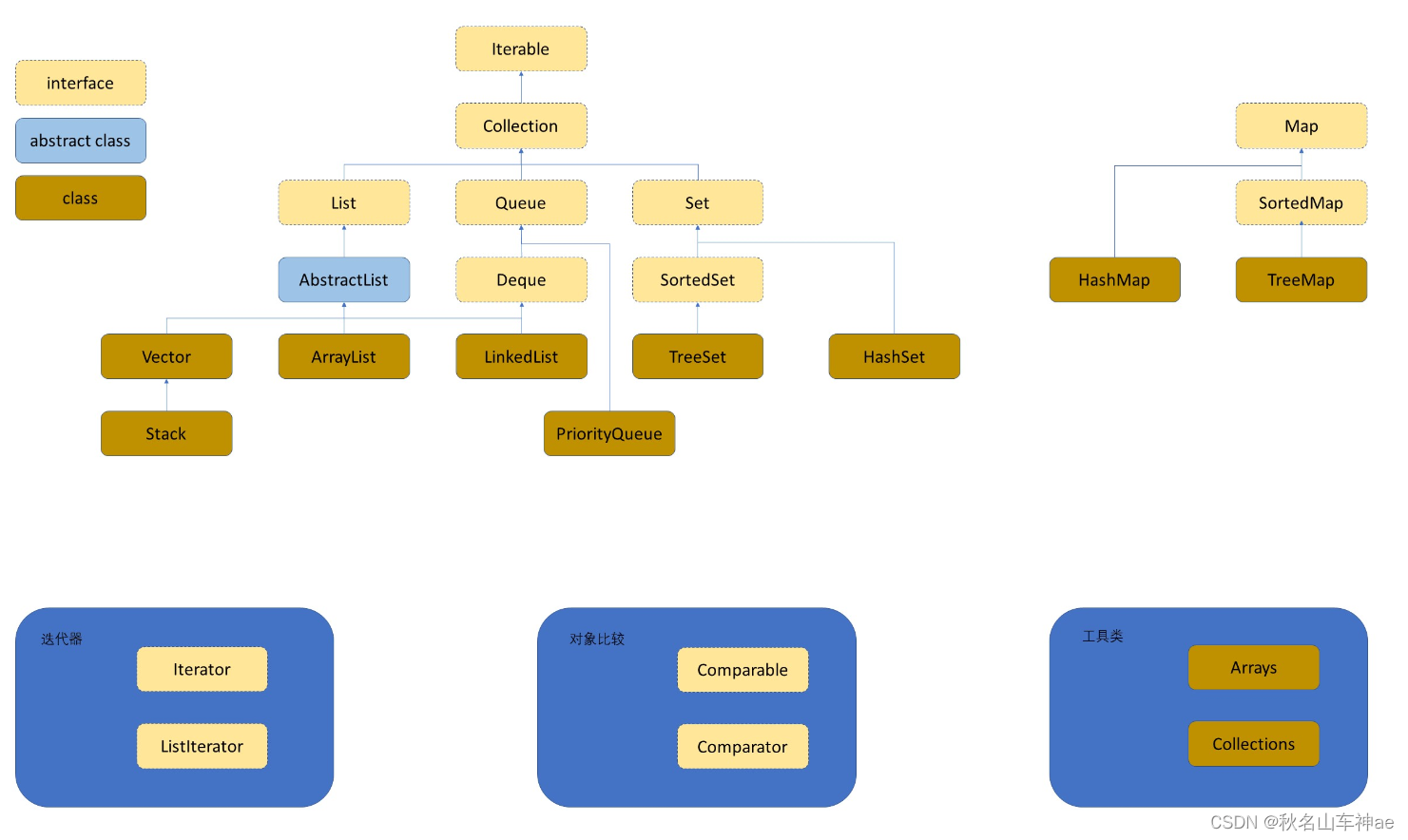
集合框架体系图
Java的集合框架背后的数据结构:
- Collection:是一个接口,包含了大部分容器常用的一些方法
- List:是一个接口,规范了ArrayList 和 LinkedList中要实现的方法
- ArrayList:实现了List接口,底层为动态类型顺序表
- LinkedList:实现了List接口,底层为双向链表
- Stack:底层是栈,栈是一种特殊的顺序表,先进后出。
- Queue:底层是队列,队列是一种特殊的顺序表,先进先出。
- Deque:是一个接口
- Set:集合,是一个接口,里面放置的是K模型
- HashSet:底层为哈希桶,查询的时间复杂度为O(1)
- TreeSet:底层为红黑树,查询的时间复杂度为O( log2n),关于key有序的
- Map:映射,里面存储的是K-V模型的键值对
- HashMap:底层为哈希桶,查询时间复杂度为O(1)
- TreeMap:底层为红黑树,查询的时间复杂度为O(log2n),关于key有序。
什么是数据结构?:
数据结构是计算机存储、组织数据的方式,指相互之间存在一种或多种特定关系的数据元素的集合。
二、复杂度
算法效率:
算法效率分为时间效率和空间效率,时间效率主要用来衡量算法的运行速度,空间效率主要用来衡量算法运行时需要的额外空间。
时间复杂度:
算法的时间复杂度是一个数学函数,定量描述了一个算法执行所耗费的时间,一个算法执行耗费的时间与其中语句的执行次数成正相关,算法中的基本语句的执行次数,称为算法的时间复杂度。
大O表示法:
计算算法的执行次数时,并不一定需要计算精确的执行次数,只需计算出大概的次数,于是我们使用大O渐进表示法来表示,大O的渐进表示法去掉了那些对结果影响不大的项,简洁明了的表示出了执行次数。
例:
void func1(int N){
int count = 0;
for (int i = 0; i < N ; i++) {
for (int j = 0; j < N ; j++) {
count++;
}
}
for (int k = 0; k < 2 * N ; k++) {
count++;
}
int M = 10;
while ((M--) > 0) {
count++;
}
System.out.println(count);
}这个算法的执行次数是 :
N^2+2*N+10在大0渐进表示法中:
1、用常数1取代运行时间中的所有加法常数。
2、在修改后的运行次数函数中,只保留最高阶项。
3、如果最高阶项存在且不是1,则去除与这个项目相乘的常数。得到的结果就是大O阶。
所以当使用大O渐进表示法后,该算法的时间复杂度为O(N^2);
以及当算法的执行次数存在最好情况,平均情况和最坏情况时,我们在实际中一般关注算法的最坏执行情况,例如遍历一个长度为n的数组去查找元素,我们认为最坏的情况是查找了n次,所以数组查找的时间复杂度为O(N)。
空间复杂度:
空间复杂度是对算法在执行是临时占用的内存空间的大小的一个量度,空间复杂度计算的是变量的个数,也采用大O渐进表示法表示。
复杂度实例:
//时间复杂度实例1
void func3(int N, int M) {
int count = 0;
for (int k = 0; k < M; k++) {
count++;
}
for (int k = 0; k < N ; k++) {
count++;
}
System.out.println(count);
}
//时间复杂度实例2
int binarySearch(int[] array, int value) {
int begin = 0;
int end = array.length - 1;
while (begin <= end) {
int mid = begin + ((end-begin) / 2);
if (array[mid] < value)
begin = mid + 1;
else if (array[mid] > value)
end = mid - 1;
else return mid;
}
return -1;
}
实例1中:循环1执行M次,循环2执行N次,所以时间复杂度为O(M+N).
实例2为二分查找,在最坏的情况下,每次排除掉一半的值,剩下n/2。所以最坏情况下的执行次数是log2n,因此时间复杂度为log2n。
//空间复杂度实例1
void bubbleSort(int[] array) {
for (int end = array.length; end > 0; end--) {
boolean sorted = true;
for (int i = 1; i < end; i++) {
if (array[i - 1] > array[i]) {
Swap(array, i - 1, i);
sorted = false;
}
}
if(sorted == true) {
break;
}
}
//空间复杂度实例2
long factorial(int N) {
return N < 2 ? N : factorial(N-1)*N;
}实例1中,额外使用的空间为常数个,所以空间复杂度为O(1);
实例2中,递归了N次,每递归1次,会开辟一个函数栈帧,共开辟N个栈帧,所以时间复杂度为O(N)。
三.初识泛型
泛型是什么,为什么要有泛型,泛型能做什么?
泛型通俗地讲便是适用于多种类型。例如我们需要实现一个类,类中有一个数组,我们想让这个类在实例化后,这个数组不但可以存放整形,也可以实现存放字符型,甚至可以存放各种类型。要实现上述想法,我们就需要用到泛型。泛型是将类型参数化后,进行传递,从而可以指定当前的容器拥有什么类型的对象。
泛型的使用:
泛型类的定义:
class 泛型类名称<类型形参列表> {
//类中可以使用类型参数
//例:
T func(T val){
return val;
}
class ClassName<T1, T2, ..., Tn> {
}
class 泛型类名称<类型形参列表> extends 继承类/* 这里可以使用类型参数 */ {
}
class ClassName<T1, T2, ..., Tn> extends ParentClass<T1> {
}实例化示例:
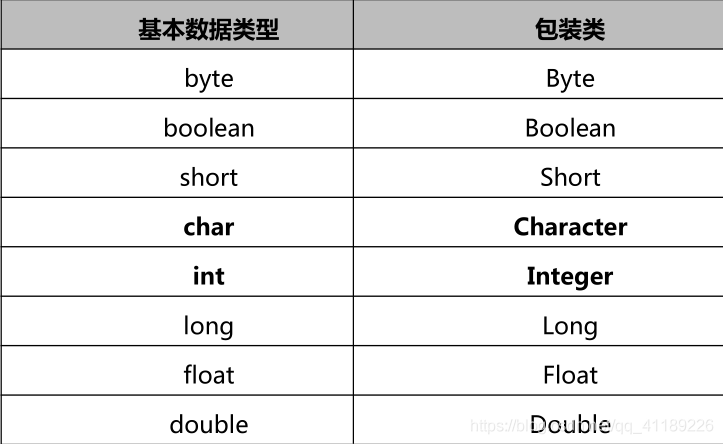
MyArray<Integer> list = new MyArray<Integer>();泛型只能接受类,所有的基本数据类型要使用包装类。
Java基本数据类型包装类
当编译器可以根据上下文推导出类型实参时,可以省略类型实参的填写::
MyArray<Integer> list = new MyArray<>();实例化泛型数组:
此方法并不规范,正确的方法应该由反射去创建,但泛型简单了解能够使用即可。
public T[] array = (T[])new Object[10];泛型的上界:
定义泛型类时,通过类型边界来约束传入的类型变量。
public class MyArray<E extends Number> {
//只接受 Number 的子类型作为 E 的类型实参
}泛型方法:
//语法格式
//方法限定符 <类型形参列表> 返回值类型 方法名称(形参列表) { ... }
public class Util {
//静态的泛型方法 需要在static后用<>声明泛型类型参数
public static <E> void swap(E[] array, int i, int j) {
E t = array[i];
array[i] = array[j];
array[j] = t;
}
}
自动装箱和自动拆箱:
编译器对包基本数据类型的包装称为装箱,所以当内置的基本数据类型被当作对象使用的时候,编译器会把内置类型装箱为包装类。相似的,编译器也可以把一个对象拆箱为内置类型。
int i = 10;
Integer ii = i; // 自动装箱
Integer ij = (Integer)i; // 自动装箱
int j = ii; // 自动拆箱
int k = (int)ii; // 自动拆箱--------------------------------------------------2022-07-23----------------------------------------------------------------















 1865
1865











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









