







记录自己使用VMware搭建Spark集群的过程,使用三台虚拟机。
若只需要Hadoop集群,则将5和7跳过即可;
若只需要Spark Standalone模式的集群,则将6和7跳过即可。
文章目录
1. 环境
- 系统:VM下的ubuntu16.04,本次实验中使用3个VM
- JDK版本:jdk1.8.0_201
- hadoop版本:hadoop-2.6.5
- Spark版本: spark-2.4.1-bin-hadoop2.6
2. 第一台虚拟机
2.1 虚拟机创建
- 下载Ubuntu16.04的ISO镜像,使用VMware创建虚拟机,本次实验中分配内存为2GB,硬盘100G,用户命名为
node(自己在做的时候命名成vm01了) - 启动虚拟机,使用
ifconfig查看自己分配到的ip地址,如下:
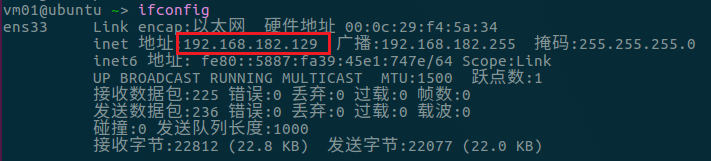
-
测试下ping外网(比如www.baidu.com)能不能ping通,再测试与物理机是否可以互相ping通,若可以则网络没问题
-
修改源,本次实验使用清华源如下(网上找下就有),复制到
/etc/apt/sources.list即可(覆盖原来的)
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ xenial main restricted universe multiverse
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ xenial-updates main restricted universe multiverse
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ xenial-backports main restricted universe multiverse
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ xenial-security main restricted universe multiverse
- 修改后更新下软件,如下:
sudo apt update
sudo apt upgrade
- 下载
vim(编辑文件方便)、fish(无敌shell)
sudo apt install vim
sudo apt install fish
- 修改hosts文件,给ip取个名字,方便访问
sudo vim /etc/hosts
#这里有个127.0.1.1的,注释掉,不然后面启动的时候master会被解释成这个地址,导致slave节点访问不到
#127.0.1.1 master
#增加内容如下,预计ip是下面三个,之后其他虚拟机ip不对也可以直接改
192.168.182.129 master
192.168.182.130 slave1
192.168.182.131 slave2
2.2 Hadoop安装
Hadoop的安装按照之前的笔记操作,但是配置部分就不用了,也就是安装好jdk和hadoop就可以了。
关于Hadoop开发环境配置等问题,可参考之前有关的另一篇笔记。
2.3 Spark安装
- 从官网上下载跟之前hadoop版本匹配的spark版本,如下:
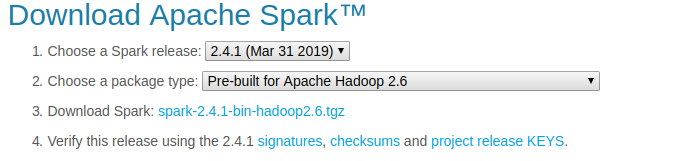
- 解压文件,放到/opt目录下
tar -xf spark-2.4.1-bin-hadoop2.6.tgz
mv spark-2.4.1-bin-hadoop2.6 /opt
- 建立spark-2.4.1-bin-hadoop2.6的软链接(方便使用不同版本),并在/etc/profile中配置环境变量
ln -snf spark-2.4.1-bin-hadoop2.6/ spark
vim /etc/profile
#spark环境变量
SPARK_HOME=/opt/spark
PATH=$PATH:${SPARK_HOME}/bin
source /etc/profile #运行使环境变量生效
- 运行spark-shell(若环境变量配置成功,任何目录下都可以),如下(
:quit退出):
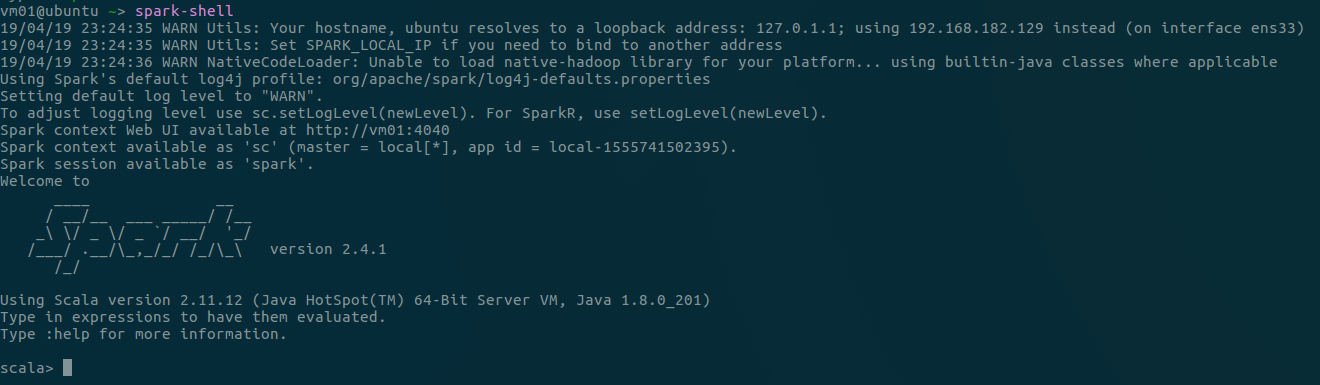
3. 虚拟机复制
直接复制第一台配置好的虚拟机,后面的集群搭建只需要修改一些配置文件即可。
3.1 修改用户名/组(看黑体)
若刚才用户命名为node这步就可以跳过了,这步是我一开始把用户命名成vm01了,改成node好看点。
对vm01修改用户名和所属组,参考Reference.2,具体如下(以命名为Node为例):
- 查看某个目录下的文件,如下以
/opt为例:

- 修改
/etc/sudoers,提前给用户权限,如下:
sudo vim /etc/sudoers
#User privilege specification
root ALL=(ALL:ALL) ALL #这一行本来有的
vm01 ALL=(ALL:ALL) ALL
Node ALL=(ALL:ALL) ALL
- 修改
/etc/shadow,修改登录时的用户,如下:
sudo vim /etc/shadow
vm01:$1$RnoyuyTk$OHTSf0TNpJajOkmim7uFD/:18006:0:99999:7::: #原来的,把vm01改成下面的Node
Node:$1$RnoyuyTk$OHTSf0TNpJajOkmim7uFD/:18006:0:99999:7:::
- 修改home下的文件
cd /home
sudo mv vm01 Node
- 修改passwd文件
sudo vim /etc/passwd
vm01:x:1000:1000:vm01,,,:/home/vm01:/bin/bash #原来的,把vm01改成下面的Node
Node:x:1000:1000:Node,,,:/home/Node:/bin/bash
- 修改用户的组
sudo vim /etc/group
vm01:x:1000: #原来的,把vm01改成下面的Node
Node:x:1000:
- 再次进入
/etc/sudoers,将刚才增加的vm01去掉 reboot重启,再次查看/opt下的文件,如下,可以看到已经成功修改

3.2 克隆虚拟机
- 在VMware中选择
vm01,右键“管理”,点击“克隆”,按提示进行克隆即可(以命名为vm02为例)
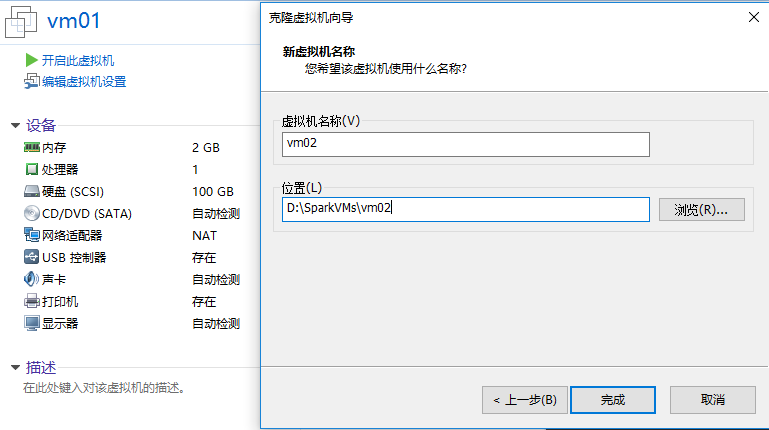
- 重复上述过程,本次实验中克隆2个虚拟机,分别为
vm02和vm03
3.3 修改主机名称
把三台VM的主机名分别改为master,slave1,slave2,参考Reference.2,具体如下:
- 修改主机名,进入文件改成要的名字
sudo vim /etc/hostname
- 修改hosts文件,把原来的主机名改成新的主机名
sudo vim /etc/hosts
- 重启即可
4. 配置ssh免密登陆
启动Spark节点的时候之前的通信使用ssh,若没有ssh,则启动会报错如下:

-
先确定三台VM是否能互相ping通
-
在三台主机上都安装
ssh
sudo apt install openssh-server
- 检查ssh是否开启,若输出类似下方则成功开启,若无反应则未开启
ps -e | grep ssh
#开启命令
sudo service ssh start #安装好应该会自动开启,一般上面这步就可以看到输出了

- 在主节点
master上生成公钥,使用如下命令,一路回车即可
ssh-keygen -t rsa
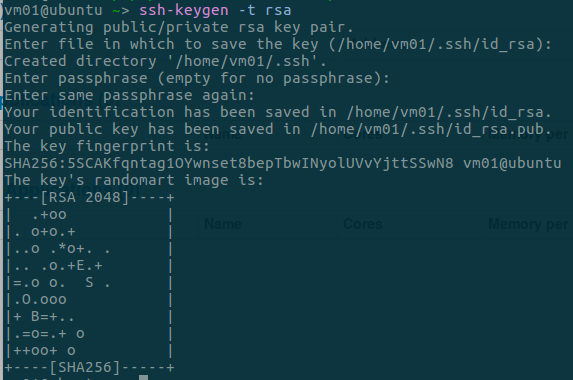
- 复制生成的公钥为
authorized_keys,如下:
cd ~/.ssh
cp id_rsa.pub authorized_keys
- 在另外两台VM上也进行4,并利用
scp命令将id_rsa.pub传送给主节点,此时主节点文件如下:
scp id_rsa.pub Node@master:~/.ssh/id_rsa.pub_slave1
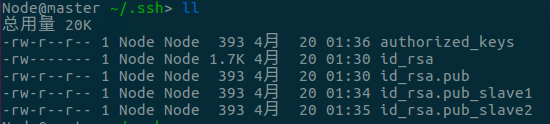
- 将新的两个PublicKey写入
authorized_keys,如下:
cat id_rsa.pub_slave1 >> authorized_keys
cat id_rsa.pub_slave2 >> authorized_keys
- 把
authorized_keys使用scp命令传送到两个从节点,如下:
scp authorized_keys Node@slave1:~/.ssh
scp authorized_keys Node@slave2:~/.ssh
- 修改
.ssh和authorized_keys的权限,如下:
chmod 700 ~/.ssh
chmod 600 ~/.ssh/authorized_keys
- 验证是否可以ssh无密码登陆,主节点ssh到一个从节点,如下:
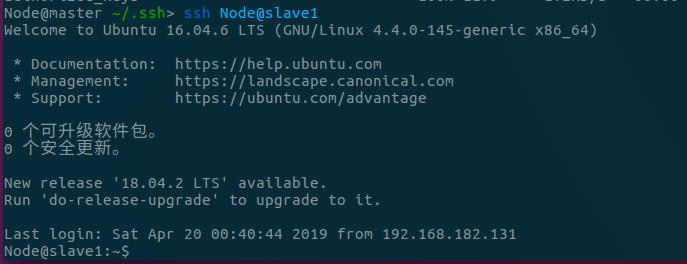
5. Spark Standalone模式搭建
master为主节点,修改spark-env.sh,增加如下内容
cd /opt/spark/conf
cp spark-env.sh.template spark-env.sh
vim spark-env.sh
export JAVA_HOME=$JAVA_HOME
export SPARK_MASTER_HOST=master #或直接用ip地址
export SPARK_MASTER_PORT=7077
- 修改
slaves,增加如下内容
cp slaves.template slaves
vim slaves
# A Spark Worker will be started on each of the machines listed below.
# 原来的localhost删掉
slave1
slave2
-
把这两个文件复制到其他节点
-
在主节点使用
sbin/start_all.sh开启服务,如下:

- 查看log可以看到
master节点的web UI为master:8080,进入查看如下:
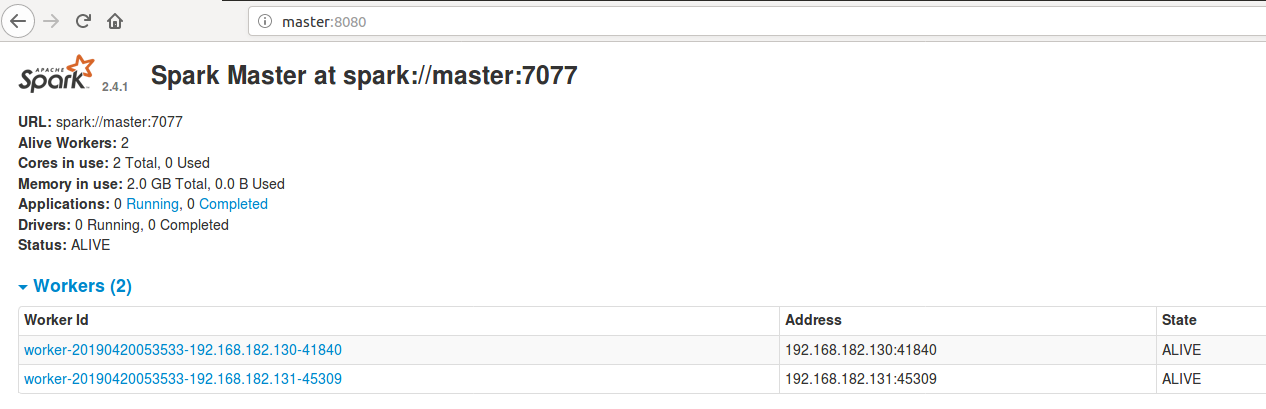
- 尝试运行,使用Standalone的
client提交,如下,可以在web UI中看到相应的运行情况
spark-submit --master spark://master:7077
--class org.apache.spark.examples.SparkPi examples/jars/spark-examples_2.11-2.4.1.jar 1000
- Standalone模式搭建完成
6. Hadoop集群搭建
搭建Hadoop集群,作为之后Spark的YARN模式的基础。
- 在hadoop中创建4个文件夹,等下配置时要用到,如下:
cd /opt/hadoop
mkdir hdfs
mkdir hdfs/tmp
mkdir hdfs/dn
mkdir hdfs/nn
- 配置文件存放在
/opt/hadoop/etc/hadoop中
cd /opt/hadoop/etc/hadoop
- 修改
hadoop-env.sh第25行JAVA_HOME,设置为与上述JDK配置时一致
#export JAVA_HOME=${JAVA_HOME} #注释掉原来的
export JAVA_HOME=/opt/jdk
- 修改
yarn-env.sh的JAVA_HOME,设置为与上述JDK配置时一致,先将第23行的#去掉,修改如下:

- 修改
core-site.xml最后的configuration,如下:
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/opt/hadoop/hdfs/tmp</value>
<description>A base for other temporary directories.</description>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
</configuration>
- 修改
hdfs-site.xml最后的configuration,如下:
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/opt/hadoop/hdfs/nn</value>
<final>true</final>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/opt/hadoop//hdfs/dn</value>
<final>true</final>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:9001</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
- 修改
mapred-site.xml,在hadoop的相关目录中没有此文件,但是有一个mapred-site.xml.template文件,将该文件复制一份为mapred-site.xml
cp mapred-site.xml.template mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
- 修改
yarn-site.xml最后的configuration如下:
<configuration>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:18040</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:18030</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:18025</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:18141</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>
- 修改
slaves文件,去掉localhost,改成:
slave1
slave2
- 将配置好的文件整个文件夹使用
scp传过去,如下:
scp -r /opt/hadoop-2.6.5/ Node@slave1:/opt/
scp -r /opt/hadoop-2.6.5/ Node@slave2:/opt/
- 初始化HDFS集群
hdfs namenode -format
- 使用
start-dfs.sh和start-yarn.sh开启集群,在主节点和从节点查看jps如下,说明搭建成功
 |  |
192.168.182.129:50070 #查看各节点,需要用ip,不能直接用master
192.168.182.129:8088 #查看YARN调度任务情况,上面设置的端口
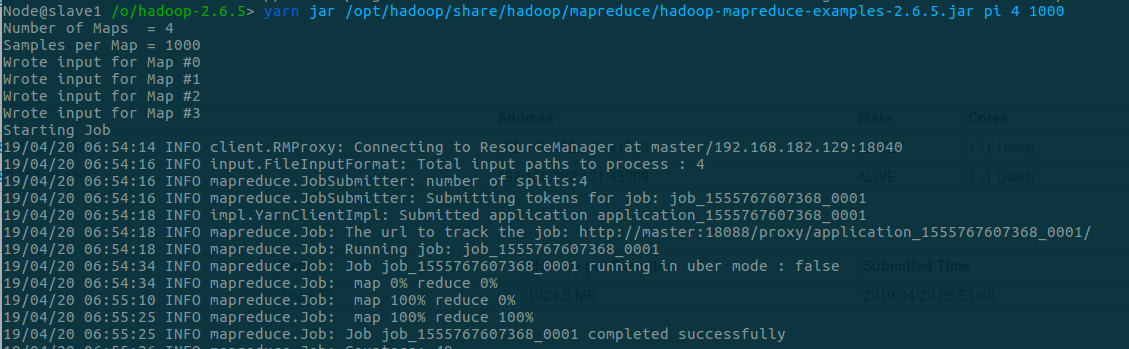
- 运行example程序,如下:
yarn jar /opt/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.5.jar pi 4 1000
7. Spark YARN模式搭建
- 修改Spark的
spark-env.sh,如下:
export JAVA_HOME=/opt/jdk
export SPARK_MASTER_HOST=master
export SPARK_MASTER_PORT=7077
export HADOOP_HOME=/opt/hadoop
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
- 将配置文件分发到两个slave节点,如下:
scp conf/spark-env.sh Node@slave1:/opt/spark/conf
scp conf/spark-env.sh Node@slave2:/opt/spark/conf
start-all.sh启动集群,如下:
 |  |
- 运行example程序,如下:
spark-submit --master yarn
--class org.apache.spark.examples.SparkPi examples/jars/spark-examples_2.11-2.4.1.jar 1000
报错,提示如下,1G是yarn-site.xml里的yarn.scheduler.minimum-allocation-mb设置的,最小为1G;而yarn-site.xml中的yarn.nodemanager.vmem-pmem-ratio(虚存与物理内存比值)默认为2.1,而这个应用需要虚存2.1G,超过了就被Kill掉了。
Container [pid=14164,containerID=container_1555808155076_0003_02_000001] is running
beyond virtual memory limits.Current usage: 129.3 MB of 1 GB physical memory used;
2.1 GB of 2.1 GB virtual memory used. Killing container.
比如,再设置为yarn.scheduler.minimum-allocation-mb为1.5G,比值为1.3,则报错如下:1.5*1.3=1.9
Container [pid=18544,containerID=container_1555814125799_0002_02_000001] is running
beyond virtual memory limits. Current usage: 106.6 MB of 1.5 GB physical memory used;
2.1 GB of 1.9 GB virtual memory used. Killing container.
解决方法参考【hadoop】 running beyond virtual memory错误原因及解决办法,可以——
- 改比值,使得虚存比需要的虚存大即可
- 直接把检查虚存够不够的参数置为False
- 修改
yarn.scheduler.minimum-allocation-mb,使得映射后的虚存更大(本次实验采用该方法,比值默认是2.1,1.5*2.1 > 2.1,够用了,如下:)
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>1536</value>
</property>
- 再次运行如下:
















 896
896











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









