










写爬虫的时候,请求头几乎是必写的,但是写起来有点繁琐,虽然不难,但是麻烦,所以这时候,一个自动生成请求头的方法就显得很重要了
在线生成请求头
使用方法
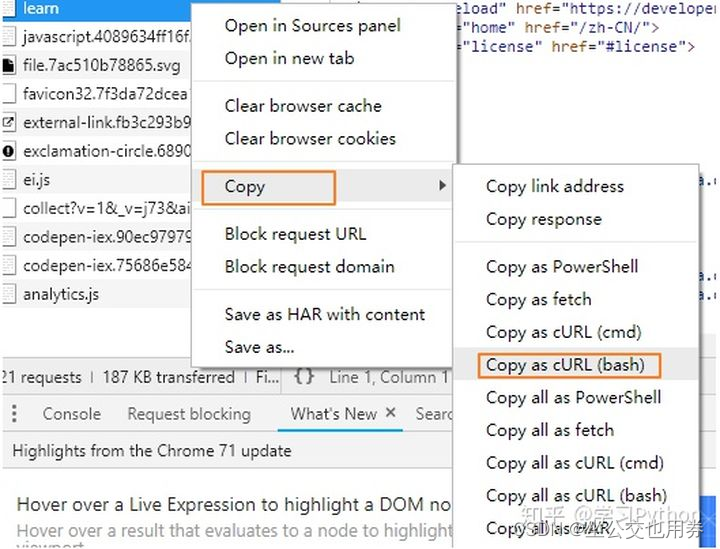
import requests
headers = {
'authority': 'curlconverter.com',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'accept-language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
'cache-control': 'max-age=0',
'if-modified-since': 'Fri, 15 Jul 2022 21:44:42 GMT',
'if-none-match': 'W/"62d1dfca-3a58"',
'referer': 'https://link.csdn.net/?target=https%3A%2F%2Fcurlconverter.com%2F',
'sec-ch-ua': '" Not A;Brand";v="99", "Chromium";v="102", "Microsoft Edge";v="102"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Linux"',
'sec-fetch-dest': 'document',
'sec-fetch-mode': 'navigate',
'sec-fetch-site': 'cross-site',
'sec-fetch-user': '?1',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.5005.63 Safari/537.36 Edg/102.0.1245.30',
}
response = requests.get('https://curlconverter.com/', headers=headers)
















 991
991

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











