






大家好,我是方木~
这次跟大家分享的是如何解决线上环境OOM问题
近期一周连续在测试环境遇到两次OOM 和 一次内存泄露,惨呐~
常见的问题排查方式
-
查看服务的进程是否存在
ps -ef | grep 服务名 ps -aux | grep 服务名 -
查看服务的日志
cat -n xxx_log |grep "OutOfMemoryError"java.lang.OutOfMemoryError GC overhead limit exceeded oracle官方给出了这个错误产生的原因和解决方法:
大概意思就是说,JVM花费了98%的时间进行垃圾回收,而只得到2%可用的内存,频繁的进行内存回收(最起码已经进行了5次连续的垃圾回收),JVM就会曝出ava.lang.OutOfMemoryError: GC overhead limit exceeded错误。
-
查看堆内存占用概况
jmap -heap 进程号 -
查看堆中对象的统计信息
jmap -histo 进程号 | head -n 100 -
查看GC统计信息
jstat -gcutil 进程号S0 S1 E O M CCS YGC YGCT FGC FGCT GCT 0.00 0.00 100.00 99.94 90.56 87.86 875 9.307 3223 5313.139 5322.446 S0:幸存1区当前使用比例 S1:幸存2区当前使用比例 E:Eden Space(伊甸园)区使用比例 O:Old Gen(老年代)使用比例 M:元数据区使用比例 CCS:压缩使用比例 YGC:年轻代垃圾回收次数 FGC:老年代垃圾回收次数 FGCT:老年代垃圾回收消耗时间 GCT:垃圾回收消耗总时间 -
生产对堆快照Heap dump
jmap -dump:format=b,file=/tmp/进程号_jmap_dump.hprof 进程号 -
分析生成的堆快照
使用 Eclipse Memory Analyzer 工具。 下载地址: www.eclipse.org/mat/download
内存泄露
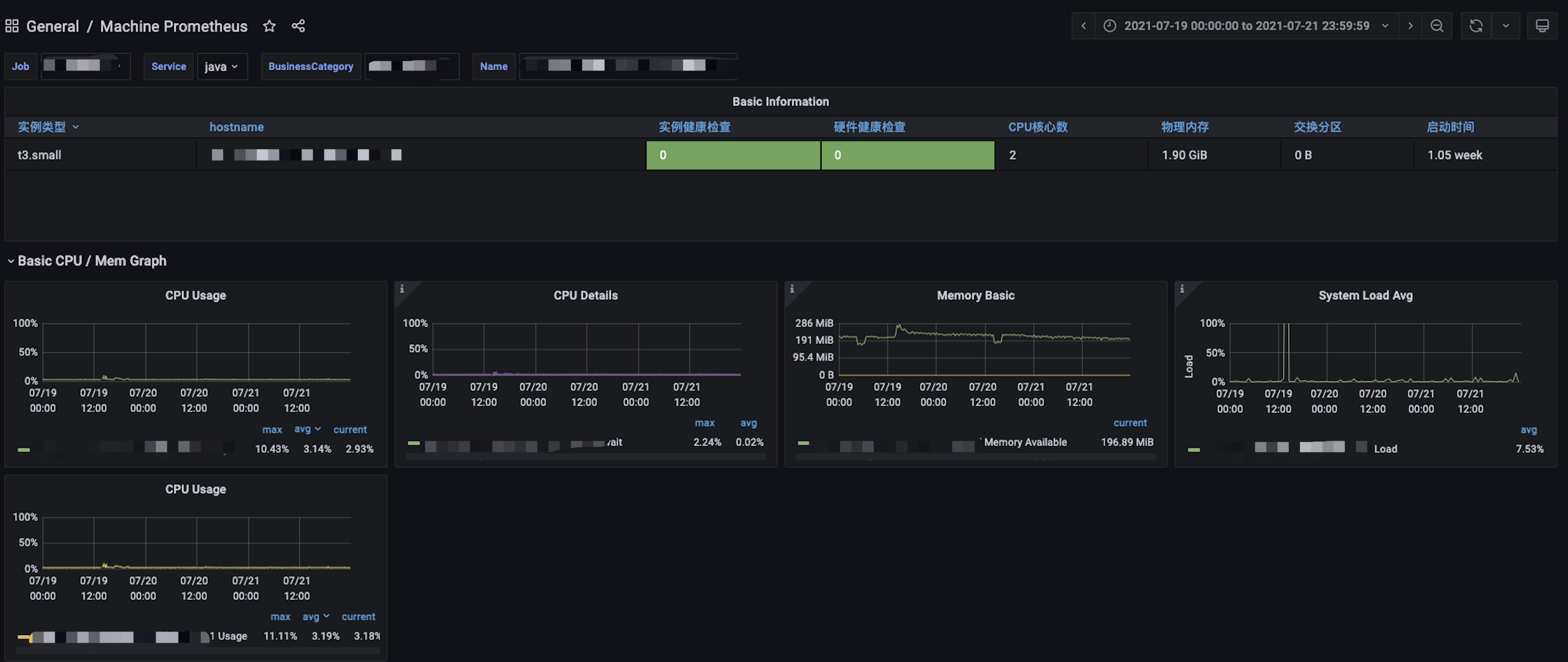
内存泄露的背景,新启了一个新项目,长时间放在测试环境运行测试中,过了一周多,突然服务重启的时候,一直都是重启失败,看了下监控面板发现,从7月8日直到7月14日,每天内存都在下降(正常情况下 应该在某个区间来回波动),此时开始怀疑程序写了某些bug导致内存泄露了

后续又让服务跑了一段时间后,主动生成此时的jvm dump文件,使用 mat 工具分析后发现 ByteArrayInputStream 的数据比较,评估了下,预计就是使用流不规范 未及时回收导致的。真是低级的错误
涉及修改的代码
代码的逻辑很简单:从apollo获取对应key的配置,将其配置加载到 Properties中,怀疑这块代码使用不规范导致内存泄露
String configTmp = config.getProperty("canal_config_template", "");
Properties canalConfigProperties.load(new ByteArrayInputStream(configTmp.getBytes(StandardCharsets.UTF_8)));
修改方案,jdk1.8 可以通过将 ByteArrayInputStream定义在 try中,使用完会自动回收资源,相当于 在finnaly{byteArrayInputStream.close();}
Properties canalConfigProperties;
String configTmp = config.getProperty("canal_config_template", "");
try (ByteArrayInputStream byteArrayInputStream = new ByteArrayInputStream(configTmp.getBytes(StandardCharsets.UTF_8))) {
canalConfigProperties.load(byteArrayInputStream);
}
后续进行一段时间的压测,发现 Memory Basic 趋于一个区间,终于正常了(幸好还没上线)
OOM 问题排查 案例一
canal 测试环境突然报OOM异常
前提:canal 会先监听 mysql 所有的
binlog,将binlog进行解析得到sql过滤掉哪些 不需要监听的table。
由于现在在每个环境都配置了,服务发生OOM的时候 会自动生成 dump文件
-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/tmp/heapdump.hprof
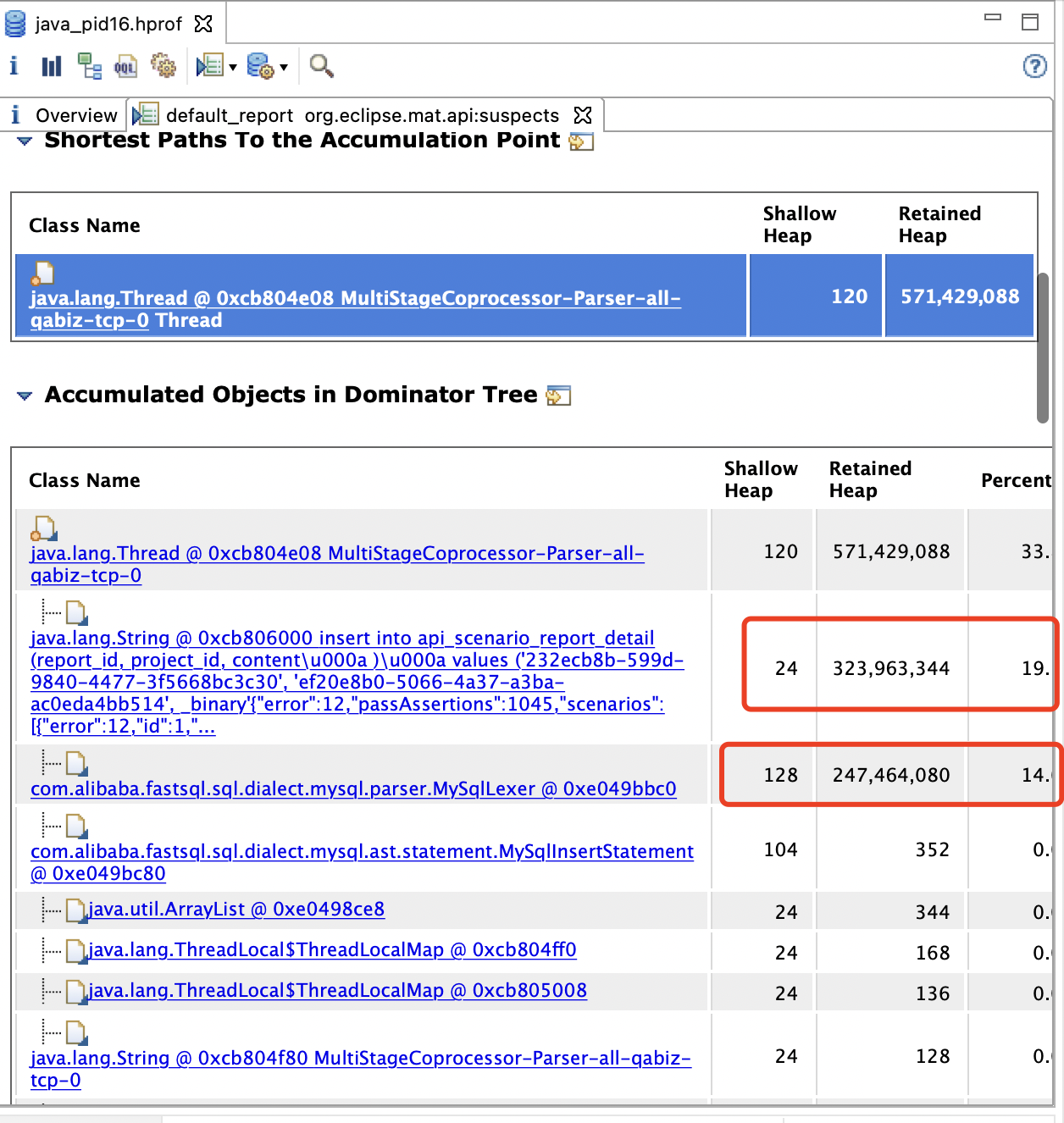
拿到 dump文件 使用 mat 开始一顿操作后,发现某个字符串特别大 300多M,解析它的对象 也以及 200M多了,在此次出现OOM,分析了执行多堆栈信息,发现 api_scenario_report_detail 这张表执行了一条 300多M的sql(这个就太夸张了),定位了问题后 与 对应开发人员沟通后得知,他们那边使用开源压测项目,里面有遗留的 bug,导致出现了这一条300多M的 sql(有惊无险,还好不是 canal 的 bug)
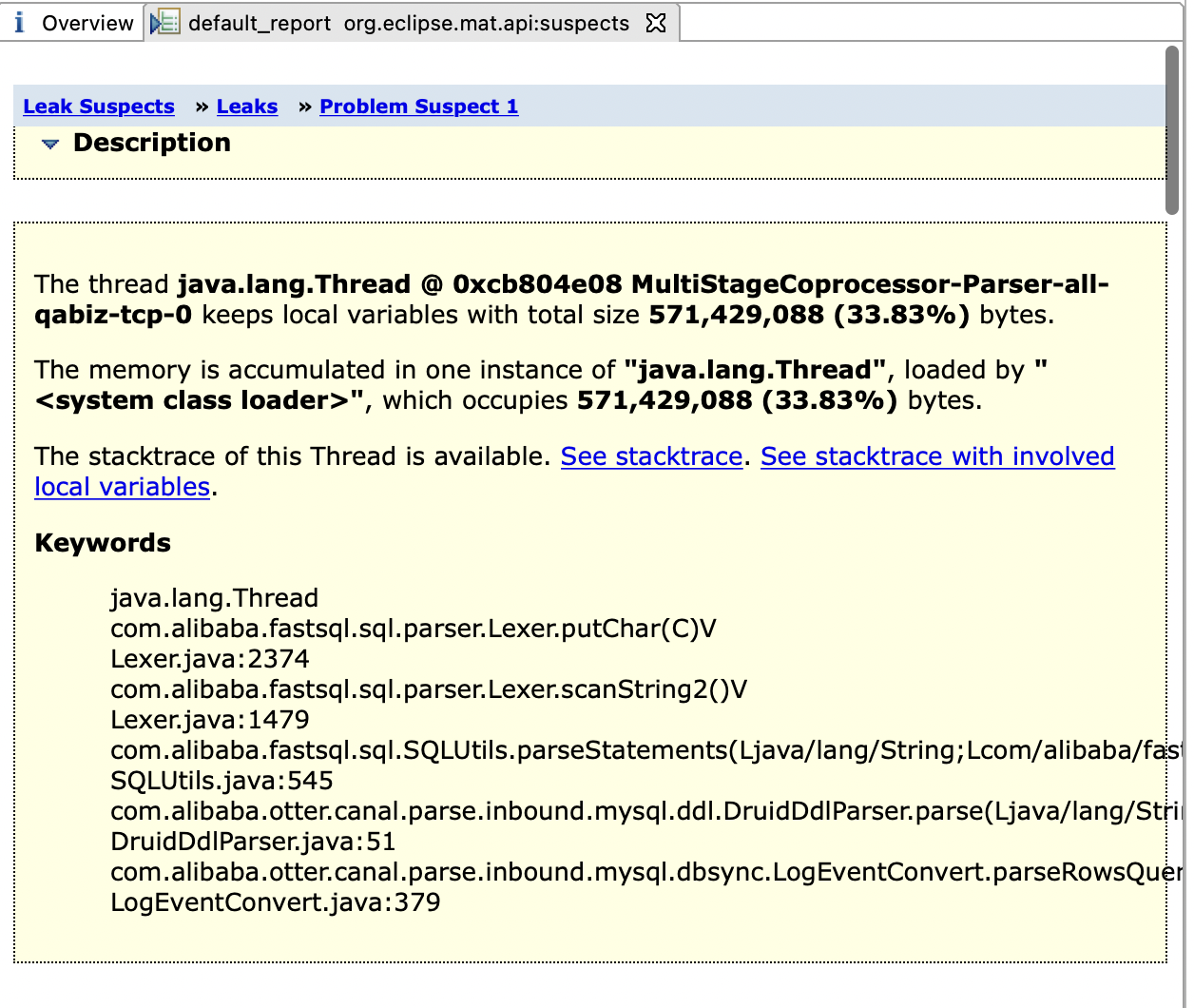
OOM 问题排查 案例二
前提:一个conusmer的服务 是专门用来监听 kafka中消息,将其数据进行加处理后,发送至es中
服务发生 OOM 后,很快就拿到了 dump文件,同样使用 mat 工具进行分析,分析后 发现 ArrayBlockingQueue 中在线程池等待的对象100多个,一个对象差不多 4M左右,相当于在 队列里 堆积了 400多M 的对象,还在上涨。此次在确认了下 测试环境 consumer 这个服务 kafka 中的消息突然激增,导致 consumer 消费能力跟不上,再加上测试环境的服务机器都是 1.8核1.6G,服务本身的一些其他逻辑 可用的内存本身就500多M,也就导致了此次的 OOM 的问题。(准备写这个文章的时候,这个 dump文件 找不到了)
查看相应的代码逻辑
int cpuNum = Runtime.getRuntime().availableProcessors();
if(cpuNum < 1 ) {
cpuNum = 1;
}
// configProperties.getKafkaComsumerQueue() 之前的配置是 500
threadPoolExecutor = new ThreadPoolExecutor(1,cpuNum,5000L, TimeUnit.MILLISECONDS,new ArrayBlockingQueue<>(configProperties.getKafkaComsumerQueue()),new ThreadPoolExecutor.CallerRunsPolicy());
...
// 监听消费kafka对应的topic消息
之前 configProperties.getKafkaComsumerQueue() 的配置是 500,如果一个对象是4M的话,得至少快 2G的内存 才能防止 OOM…
既然是测试环境,而且平时数据量都比较小,没必要申请更搞配置的机器,因此降低 队列的长度即可解决问题,为了安全期间后 再出现此类的 OOM,甚至上游的对象那天变大了 又导致 OOM,因此 将队列的大小改为 100(至少先保证服务可用~)
总结
大家用到线程池的话,一定要留意 执行的任务是 CPU密集型和IO密集型,以及队列的大小需要预留多少
欢迎关注我的微信公众号:Java架构师进阶编程
专注分享Java技术干货,包括JVM、SpringBoot、SpringCloud、数据库、架构设计、面试题、电子书等,期待你的关注!

















 1102
1102











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











